 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokenFlow: Rethinking Fine-grained Cross-modal Alignment in Vision-Language Retrieval
Paper and Code
Oct 03, 2022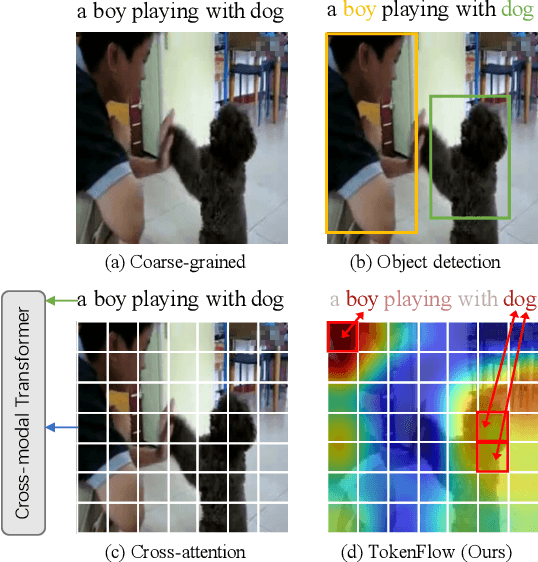
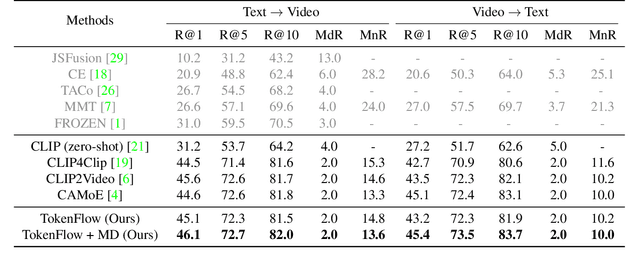
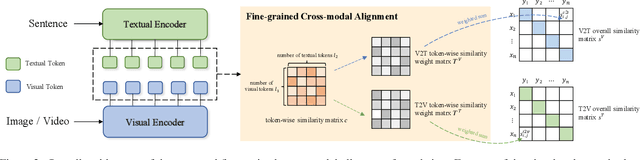
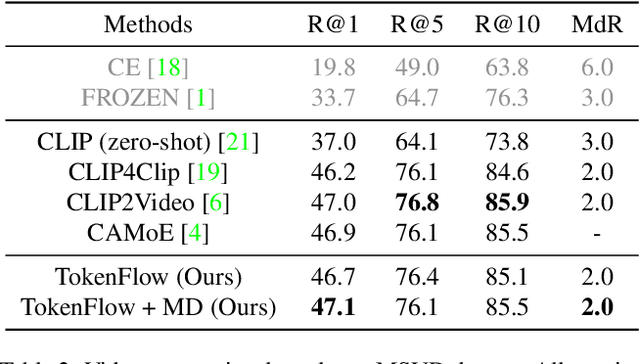
Most existing methods in vision-language retrieval match two modalities by either comparing their global feature vectors which misses sufficient information and lacks interpretability, detecting objects in images or videos and aligning the text with fine-grained features which relies on complicated model designs, or modeling fine-grained interaction via cross-attention upon visual and textual tokens which suffers from inferior efficiency. To address these limitations, some recent works simply aggregate the token-wise similarities to achieve fine-grained alignment, but they lack intuitive explanations as well as neglect the relationships between token-level features and global representations with high-level semantics. In this work, we rethink fine-grained cross-modal alignment and devise a new model-agnostic formulation for it. We additionally demystify the recent popular works and subsume them into our scheme. Furthermore, inspired by optimal transport theory, we introduce TokenFlow, an instantiation of the proposed scheme. By modifying only the similarity function, the performance of our method is comparable to the SoTA algorithms with heavy model designs on major video-text retrieval benchmarks. The visualization further indicates that TokenFlow successfully leverages the fine-grained information and achieves better interpretability.