 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMini-Omni2: Towards Open-source GPT-4o with Vision, Speech and Duplex Capabilities
Oct 16, 2024



GPT-4o, an all-encompassing model, represents a milestone in the development of large multi-modal language models. It can understand visual, auditory, and textual modalities, directly output audio, and support flexible duplex interaction. Models from the open-source community often achieve some functionalities of GPT-4o, such as visual understanding and voice chat. Nevertheless, training a unified model that incorporates all modalities is challenging due to the complexities of multi-modal data, intricate model architectures, and training processes. In this paper, we introduce Mini-Omni2, a visual-audio assistant capable of providing real-time, end-to-end voice responses to visoin and audio queries. By integrating pretrained visual and auditory encoders, Mini-Omni2 maintains performance in individual modalities. We propose a three-stage training process to align modalities, allowing the language model to handle multi-modal inputs and outputs after training on a limited dataset. For interaction, we introduce a command-based interruption mechanism, enabling more flexible interaction with users. To the best of our knowledge, Mini-Omni2 is one of the closest reproductions of GPT-4o, which have similar form of functionality, and we hope it can offer valuable insights for subsequent research.
Mini-Omni2: Towards Open-source GPT-4o Model with Vision, Speech and Duplex
Oct 15, 2024GPT4o, an all-encompassing model, represents a milestone in the development of multi-modal large models. It can understand visual, auditory, and textual modalities, directly output audio, and support flexible duplex interaction. However, its technical framework is not open-sourced. Models from the open-source community often achieve some functionalities of GPT4o, such as visual understanding and voice dialogue. Nevertheless, training a unified model that incorporates all modalities is challenging due to the complexities of multi-modal data, intricate model architectures, and training processes. In this paper, we introduce Mini-Omni2, a visual-audio assistant capable of providing real-time, end-to-end voice responses to user video and voice queries, while also incorporating auditory capabilities. By integrating pretrained visual and auditory encoders, Mini-Omni2 maintains strong performance in individual modalities. We propose a three-stage training process to align modalities, allowing the language model to handle multi-modal inputs and outputs after training on a limited dataset. For interaction, we introduce a semantic-based interruption mechanism, enabling more flexible dialogues with users. All modeling approaches and data construction methods will be open-sourced. To the best of our knowledge, Mini-Omni2 is one of the models closest to GPT4o in functionality, and we hope it can offer valuable insights for subsequent research.
Mini-Omni: Language Models Can Hear, Talk While Thinking in Streaming
Aug 30, 2024Recent advances in language models have achieved significant progress. GPT-4o, as a new milestone, has enabled real-time conversations with humans, demonstrating near-human natural fluency. Such human-computer interaction necessitates models with the capability to perform reasoning directly with the audio modality and generate output in streaming. However, this remains beyond the reach of current academic models, as they typically depend on extra TTS systems for speech synthesis, resulting in undesirable latency. This paper introduces the Mini-Omni, an audio-based end-to-end conversational model, capable of real-time speech interaction. To achieve this capability, we propose a text-instructed speech generation method, along with batch-parallel strategies during inference to further boost the performance. Our method also helps to retain the original model's language capabilities with minimal degradation, enabling other works to establish real-time interaction capabilities. We call this training method "Any Model Can Talk". We also introduce the VoiceAssistant-400K dataset to fine-tune models optimized for speech output. To our best knowledge, Mini-Omni is the first fully end-to-end, open-source model for real-time speech interaction, offering valuable potential for future research.
TokenFlow: Rethinking Fine-grained Cross-modal Alignment in Vision-Language Retrieval
Oct 03, 2022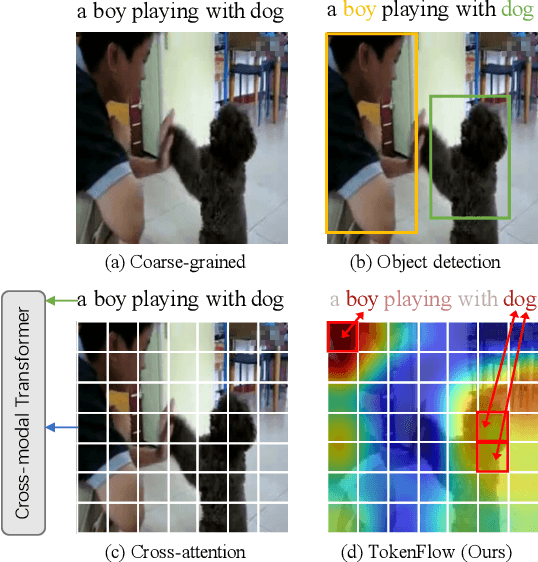
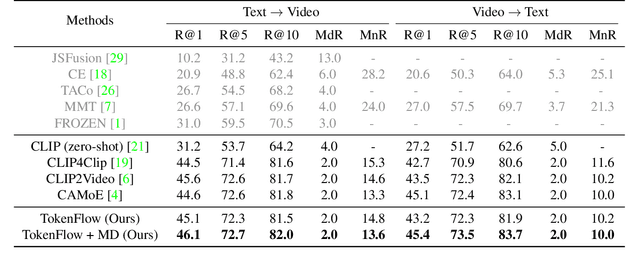
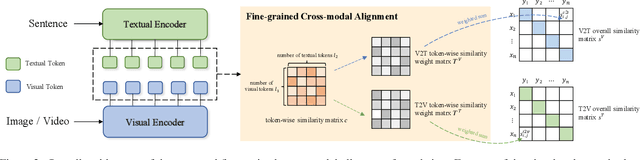
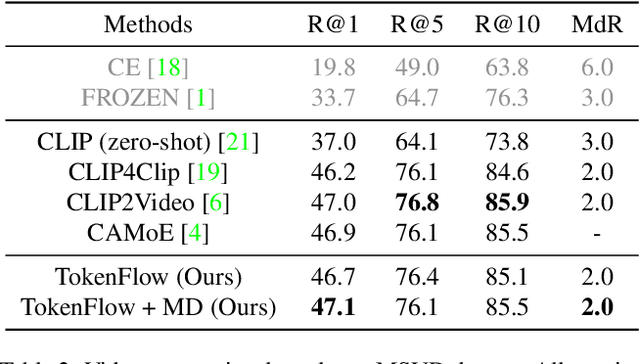
Most existing methods in vision-language retrieval match two modalities by either comparing their global feature vectors which misses sufficient information and lacks interpretability, detecting objects in images or videos and aligning the text with fine-grained features which relies on complicated model designs, or modeling fine-grained interaction via cross-attention upon visual and textual tokens which suffers from inferior efficiency. To address these limitations, some recent works simply aggregate the token-wise similarities to achieve fine-grained alignment, but they lack intuitive explanations as well as neglect the relationships between token-level features and global representations with high-level semantics. In this work, we rethink fine-grained cross-modal alignment and devise a new model-agnostic formulation for it. We additionally demystify the recent popular works and subsume them into our scheme. Furthermore, inspired by optimal transport theory, we introduce TokenFlow, an instantiation of the proposed scheme. By modifying only the similarity function, the performance of our method is comparable to the SoTA algorithms with heavy model designs on major video-text retrieval benchmarks. The visualization further indicates that TokenFlow successfully leverages the fine-grained information and achieves better interpretability.