 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Domain Shift in Diffusion Models for Cross-Modality Image Translation
Jan 26, 2026Cross-modal image translation remains brittle and inefficient. Standard diffusion approaches often rely on a single, global linear transfer between domains. We find that this shortcut forces the sampler to traverse off-manifold, high-cost regions, inflating the correction burden and inviting semantic drift. We refer to this shared failure mode as fixed-schedule domain transfer. In this paper, we embed domain-shift dynamics directly into the generative process. Our model predicts a spatially varying mixing field at every reverse step and injects an explicit, target-consistent restoration term into the drift. This in-step guidance keeps large updates on-manifold and shifts the model's role from global alignment to local residual correction. We provide a continuous-time formulation with an exact solution form and derive a practical first-order sampler that preserves marginal consistency. Empirically, across translation tasks in medical imaging, remote sensing, and electroluminescence semantic mapping, our framework improves structural fidelity and semantic consistency while converging in fewer denoising steps.
InvarGC: Invariant Granger Causality for Heterogeneous Interventional Time Series under Latent Confounding
Oct 22, 2025Granger causality is widely used for causal structure discovery in complex systems from multivariate time series data. Traditional Granger causality tests based on linear models often fail to detect even mild non-linear causal relationships. Therefore, numerous recent studies have investigated non-linear Granger causality methods, achieving improved performance. However, these methods often rely on two key assumptions: causal sufficiency and known interventional targets. Causal sufficiency assumes the absence of latent confounders, yet their presence can introduce spurious correlations. Moreover, real-world time series data usually come from heterogeneous environments, without prior knowledge of interventions. Therefore, in practice, it is difficult to distinguish intervened environments from non-intervened ones, and even harder to identify which variables or timesteps are affected. To address these challenges, we propose Invariant Granger Causality (InvarGC), which leverages cross-environment heterogeneity to mitigate the effects of latent confounding and to distinguish intervened from non-intervened environments with edge-level granularity, thereby recovering invariant causal relations. In addition, we establish the identifiability under these conditions. Extensive experiments on both synthetic and real-world datasets demonstrate the competitive performance of our approach compared to state-of-the-art methods.
LLM Based Bayesian Optimization for Prompt Search
Oct 05, 2025



Bayesian Optimization (BO) has been widely used to efficiently optimize expensive black-box functions with limited evaluations. In this paper, we investigate the use of BO for prompt engineering to enhance text classification with Large Language Models (LLMs). We employ an LLM-powered Gaussian Process (GP) as the surrogate model to estimate the performance of different prompt candidates. These candidates are generated by an LLM through the expansion of a set of seed prompts and are subsequently evaluated using an Upper Confidence Bound (UCB) acquisition function in conjunction with the GP posterior. The optimization process iteratively refines the prompts based on a subset of the data, aiming to improve classification accuracy while reducing the number of API calls by leveraging the prediction uncertainty of the LLM-based GP. The proposed BO-LLM algorithm is evaluated on two datasets, and its advantages are discussed in detail in this paper.
Learning Flexible Time-windowed Granger Causality Integrating Heterogeneous Interventional Time Series Data
Jun 14, 2024Granger causality, commonly used for inferring causal structures from time series data, has been adopted in widespread applications across various fields due to its intuitive explainability and high compatibility with emerging deep neural network prediction models. To alleviate challenges in better deciphering causal structures unambiguously from time series, the use of interventional data has become a practical approach. However, existing methods have yet to be explored in the context of imperfect interventions with unknown targets, which are more common and often more beneficial in a wide range of real-world applications. Additionally, the identifiability issues of Granger causality with unknown interventional targets in complex network models remain unsolved. Our work presents a theoretically-grounded method that infers Granger causal structure and identifies unknown targets by leveraging heterogeneous interventional time series data. We further illustrate that learning Granger causal structure and recovering interventional targets can mutually promote each other. Comparative experiments demonstrate that our method outperforms several robust baseline methods in learning Granger causal structure from interventional time series data.
Towards Invariant Time Series Forecasting in Smart Cities
May 08, 2024In the transformative landscape of smart cities, the integration of the cutting-edge web technologies into time series forecasting presents a pivotal opportunity to enhance urban planning, sustainability, and economic growth. The advancement of deep neural networks has significantly improved forecasting performance. However, a notable challenge lies in the ability of these models to generalize well to out-of-distribution (OOD) time series data. The inherent spatial heterogeneity and domain shifts across urban environments create hurdles that prevent models from adapting and performing effectively in new urban environments. To tackle this problem, we propose a solution to derive invariant representations for more robust predictions under different urban environments instead of relying on spurious correlation across urban environments for better generalizability. Through extensive experiments on both synthetic and real-world data, we demonstrate that our proposed method outperforms traditional time series forecasting models when tackling domain shifts in changing urban environments. The effectiveness and robustness of our method can be extended to diverse fields including climate modeling, urban planning, and smart city resource management.
Causal Bayesian Optimization via Exogenous Distribution Learning
Feb 06, 2024Maximizing a target variable as an operational objective in a structured causal model is an important problem. Existing Causal Bayesian Optimization (CBO) methods either rely on hard interventions that alter the causal structure to maximize the reward; or introduce action nodes to endogenous variables so that the data generation mechanisms are adjusted to achieve the objective. In this paper, a novel method is introduced to learn the distribution of exogenous variables, which is typically ignored or marginalized through expectation by existing methods. Exogenous distribution learning improves the approximation accuracy of structured causal models in a surrogate model that is usually trained with limited observational data. Moreover, the learned exogenous distribution extends existing CBO to general causal schemes beyond Additive Noise Models (ANM). The recovery of exogenous variables allows us to use a more flexible prior for noise or unobserved hidden variables. A new CBO method is developed by leveraging the learned exogenous distribution. Experiments on different datasets and applications show the benefits of our proposed method.
Dynamic Incremental Optimization for Best Subset Selection
Feb 06, 2024

Best subset selection is considered the `gold standard' for many sparse learning problems. A variety of optimization techniques have been proposed to attack this non-smooth non-convex problem. In this paper, we investigate the dual forms of a family of $\ell_0$-regularized problems. An efficient primal-dual algorithm is developed based on the primal and dual problem structures. By leveraging the dual range estimation along with the incremental strategy, our algorithm potentially reduces redundant computation and improves the solutions of best subset selection. Theoretical analysis and experiments on synthetic and real-world datasets validate the efficiency and statistical properties of the proposed solutions.
Word Embedding with Neural Probabilistic Prior
Sep 21, 2023To improve word representation learning, we propose a probabilistic prior which can be seamlessly integrated with word embedding models. Different from previous methods, word embedding is taken as a probabilistic generative model, and it enables us to impose a prior regularizing word representation learning. The proposed prior not only enhances the representation of embedding vectors but also improves the model's robustness and stability. The structure of the proposed prior is simple and effective, and it can be easily implemented and flexibly plugged in most existing word embedding models. Extensive experiments show the proposed method improves word representation on various tasks.
Variational Flow Graphical Model
Jul 06, 2022
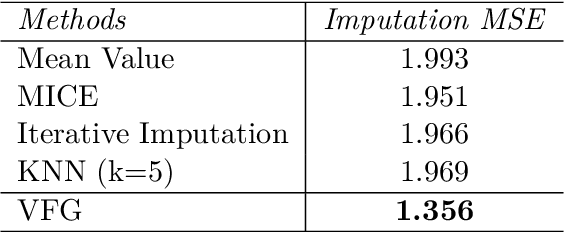
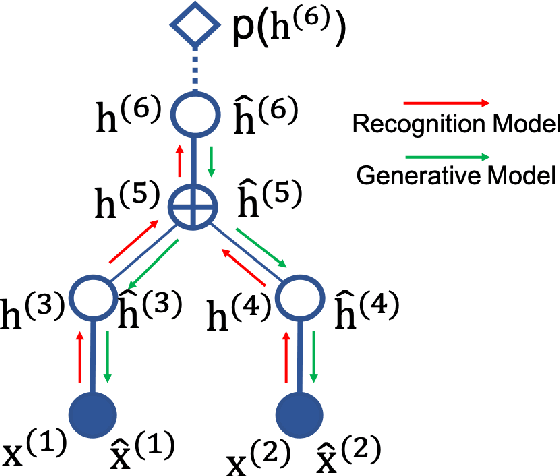

This paper introduces a novel approach to embed flow-based models with hierarchical structures. The proposed framework is named Variational Flow Graphical (VFG) Model. VFGs learn the representation of high dimensional data via a message-passing scheme by integrating flow-based functions through variational inference. By leveraging the expressive power of neural networks, VFGs produce a representation of the data using a lower dimension, thus overcoming the drawbacks of many flow-based models, usually requiring a high dimensional latent space involving many trivial variables. Aggregation nodes are introduced in the VFG models to integrate forward-backward hierarchical information via a message passing scheme. Maximizing the evidence lower bound (ELBO) of data likelihood aligns the forward and backward messages in each aggregation node achieving a consistency node state. Algorithms have been developed to learn model parameters through gradient updating regarding the ELBO objective. The consistency of aggregation nodes enable VFGs to be applicable in tractable inference on graphical structures. Besides representation learning and numerical inference, VFGs provide a new approach for distribution modeling on datasets with graphical latent structures. Additionally, theoretical study shows that VFGs are universal approximators by leveraging the implicitly invertible flow-based structures. With flexible graphical structures and superior excessive power, VFGs could potentially be used to improve probabilistic inference. In the experiments, VFGs achieves improved evidence lower bound (ELBO) and likelihood values on multiple datasets.
Best Subset Selection with Efficient Primal-Dual Algorithm
Jul 05, 2022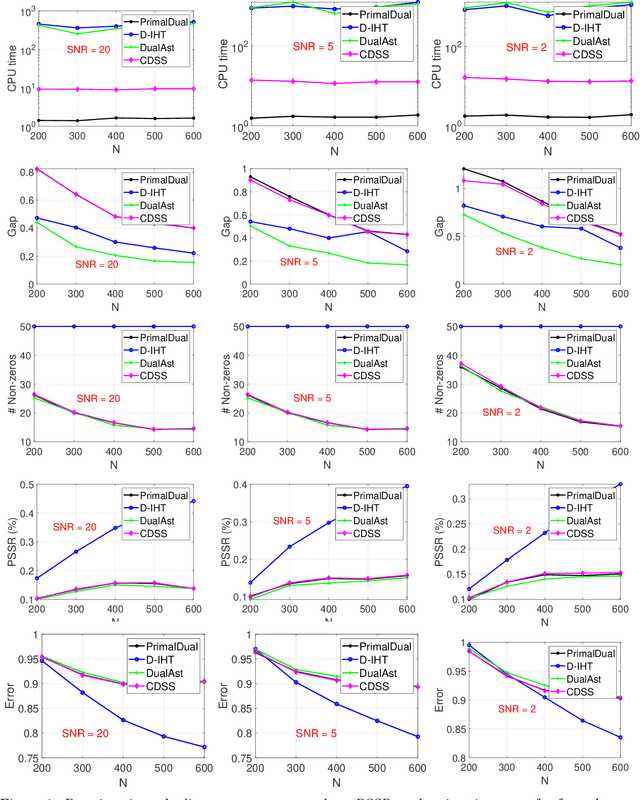
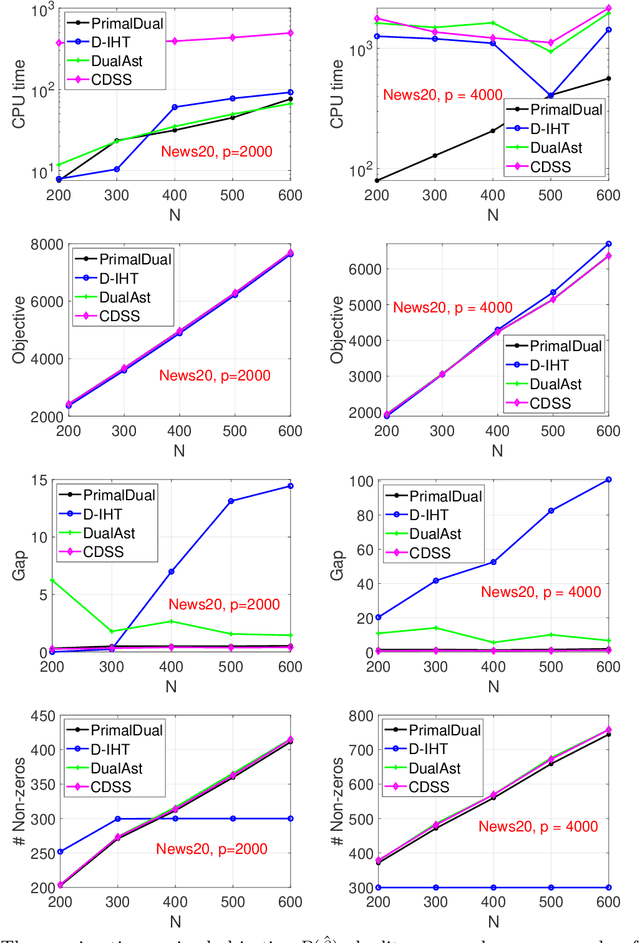
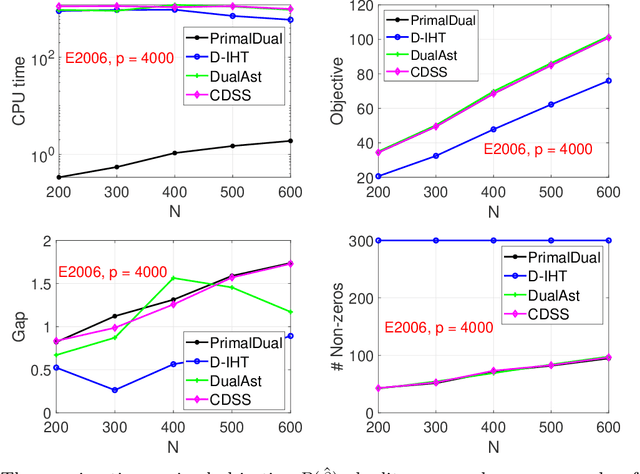
Best subset selection is considered the `gold standard' for many sparse learning problems. A variety of optimization techniques have been proposed to attack this non-convex and NP-hard problem. In this paper, we investigate the dual forms of a family of $\ell_0$-regularized problems. An efficient primal-dual method has been developed based on the primal and dual problem structures. By leveraging the dual range estimation along with the incremental strategy, our algorithm potentially reduces redundant computation and improves the solutions of best subset selection. Theoretical analysis and experiments on synthetic and real-world datasets validate the efficiency and statistical properties of the proposed solutions.