 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVAM: Universal Training-free Adaptive Visual Anchoring Embedded into Multimodal Large Language Model for Multi-image Question Answering
Aug 25, 2025The advancement of Multimodal Large Language Models (MLLMs) has driven significant progress in Visual Question Answering (VQA), evolving from Single to Multi Image VQA (MVQA). However, the increased number of images in MVQA inevitably introduces substantial visual redundancy that is irrelevant to question answering, negatively impacting both accuracy and efficiency. To address this issue, existing methods lack flexibility in controlling the number of compressed visual tokens and tend to produce discrete visual fragments, which hinder MLLMs' ability to comprehend images holistically. In this paper, we propose a straightforward yet universal Adaptive Visual Anchoring strategy, which can be seamlessly integrated into existing MLLMs, offering significant accuracy improvements through adaptive compression. Meanwhile, to balance the results derived from both global and compressed visual input, we further introduce a novel collaborative decoding mechanism, enabling optimal performance. Extensive experiments validate the effectiveness of our method, demonstrating consistent performance improvements across various MLLMs. The code will be publicly available.
Contrast-augmented Diffusion Model with Fine-grained Sequence Alignment for Markup-to-Image Generation
Aug 02, 2023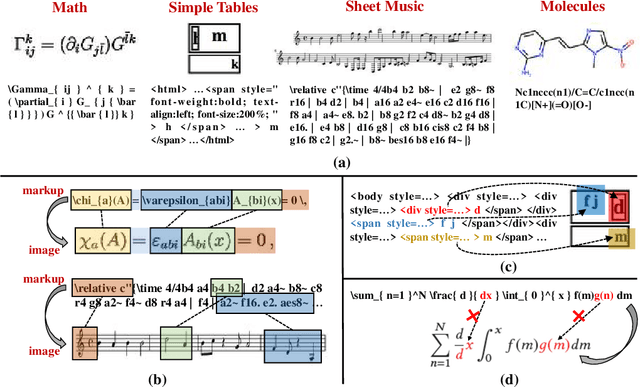



The recently rising markup-to-image generation poses greater challenges as compared to natural image generation, due to its low tolerance for errors as well as the complex sequence and context correlations between markup and rendered image. This paper proposes a novel model named "Contrast-augmented Diffusion Model with Fine-grained Sequence Alignment" (FSA-CDM), which introduces contrastive positive/negative samples into the diffusion model to boost performance for markup-to-image generation. Technically, we design a fine-grained cross-modal alignment module to well explore the sequence similarity between the two modalities for learning robust feature representations. To improve the generalization ability, we propose a contrast-augmented diffusion model to explicitly explore positive and negative samples by maximizing a novel contrastive variational objective, which is mathematically inferred to provide a tighter bound for the model's optimization. Moreover, the context-aware cross attention module is developed to capture the contextual information within markup language during the denoising process, yielding better noise prediction results. Extensive experiments are conducted on four benchmark datasets from different domains, and the experimental results demonstrate the effectiveness of the proposed components in FSA-CDM, significantly exceeding state-of-the-art performance by about 2%-12% DTW improvements. The code will be released at https://github.com/zgj77/FSACDM.