 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrast-augmented Diffusion Model with Fine-grained Sequence Alignment for Markup-to-Image Generation
Paper and Code
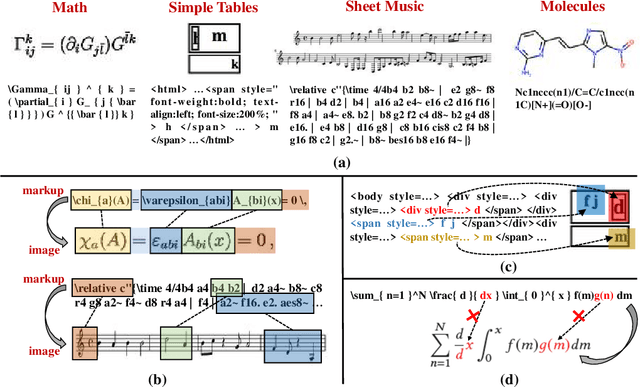



The recently rising markup-to-image generation poses greater challenges as compared to natural image generation, due to its low tolerance for errors as well as the complex sequence and context correlations between markup and rendered image. This paper proposes a novel model named "Contrast-augmented Diffusion Model with Fine-grained Sequence Alignment" (FSA-CDM), which introduces contrastive positive/negative samples into the diffusion model to boost performance for markup-to-image generation. Technically, we design a fine-grained cross-modal alignment module to well explore the sequence similarity between the two modalities for learning robust feature representations. To improve the generalization ability, we propose a contrast-augmented diffusion model to explicitly explore positive and negative samples by maximizing a novel contrastive variational objective, which is mathematically inferred to provide a tighter bound for the model's optimization. Moreover, the context-aware cross attention module is developed to capture the contextual information within markup language during the denoising process, yielding better noise prediction results. Extensive experiments are conducted on four benchmark datasets from different domains, and the experimental results demonstrate the effectiveness of the proposed components in FSA-CDM, significantly exceeding state-of-the-art performance by about 2%-12% DTW improvements. The code will be released at https://github.com/zgj77/FSACDM.