 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe USTC-NERCSLIP Systems for the CHiME-8 NOTSOFAR-1 Challenge
Sep 03, 2024
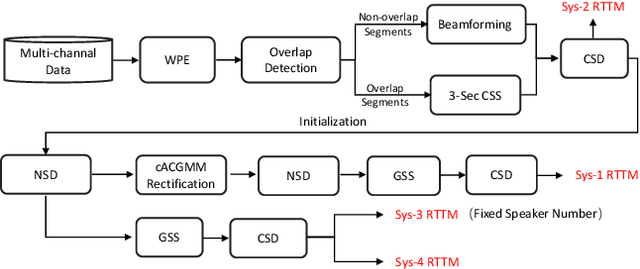
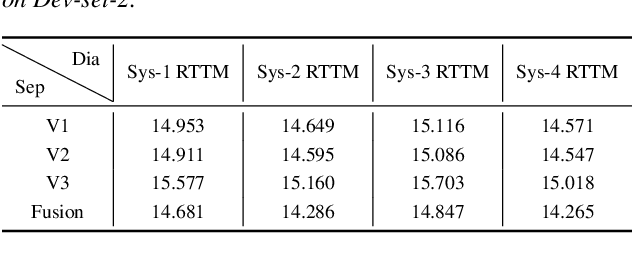
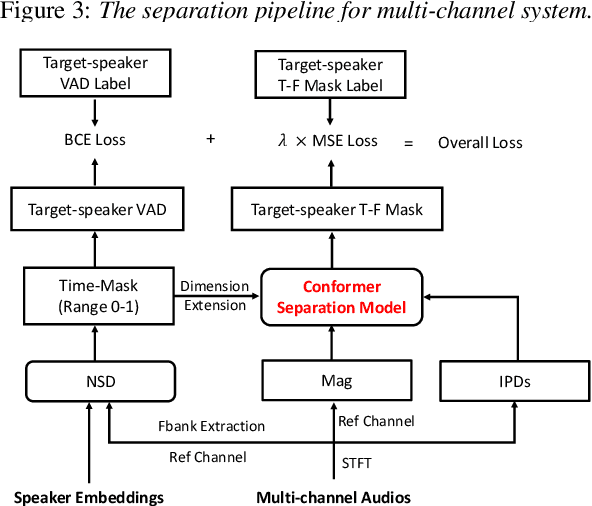
This technical report outlines our submission system for the CHiME-8 NOTSOFAR-1 Challenge. The primary difficulty of this challenge is the dataset recorded across various conference rooms, which captures real-world complexities such as high overlap rates, background noises, a variable number of speakers, and natural conversation styles. To address these issues, we optimized the system in several aspects: For front-end speech signal processing, we introduced a data-driven joint training method for diarization and separation (JDS) to enhance audio quality. Additionally, we also integrated traditional guided source separation (GSS) for multi-channel track to provide complementary information for the JDS. For back-end speech recognition, we enhanced Whisper with WavLM, ConvNeXt, and Transformer innovations, applying multi-task training and Noise KLD augmentation, to significantly advance ASR robustness and accuracy. Our system attained a Time-Constrained minimum Permutation Word Error Rate (tcpWER) of 14.265% and 22.989% on the CHiME-8 NOTSOFAR-1 Dev-set-2 multi-channel and single-channel tracks, respectively.
Reconstruction of compressed spectral imaging based on global structure and spectral correlation
Oct 27, 2022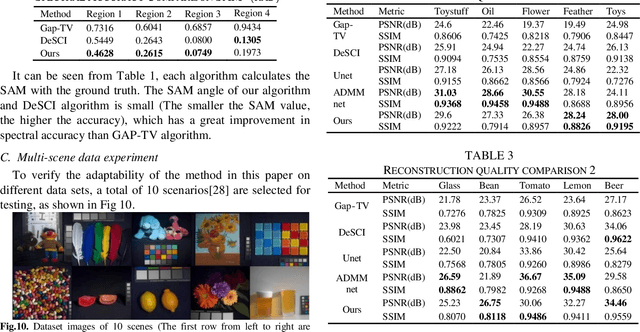
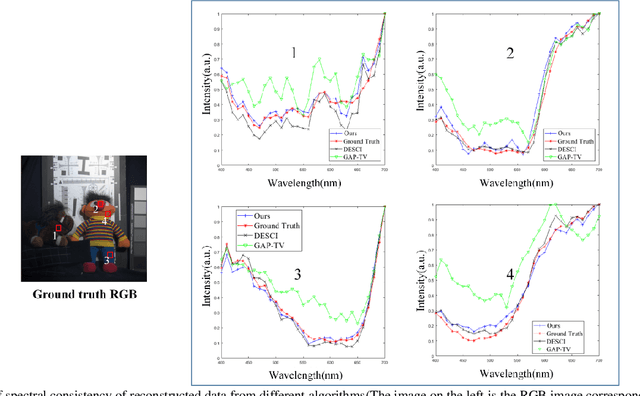
In this paper, a convolution sparse coding method based on global structure characteristics and spectral correlation is proposed for the reconstruction of compressive spectral images. The proposed method uses the convolution kernel to operate the global image, which can better preserve image structure information in the spatial dimension. To take full exploration of the constraints between spectra, the coefficients corresponding to the convolution kernel are constrained by the norm to improve spectral accuracy. And, to solve the problem that convolutional sparse coding is insensitive to low frequency, the global total-variation (TV) constraint is added to estimate the low-frequency components. It not only ensures the effective estimation of the low-frequency but also transforms the convolutional sparse coding into a de-noising process, which makes the reconstructing process simpler. Simulations show that compared with the current mainstream optimization methods (DeSCI and Gap-TV), the proposed method improves the reconstruction quality by up to 7 dB in PSNR and 10% in SSIM, and has a great improvement in the details of the reconstructed image.