 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete to Continuous: Generating Smooth Transition Poses from Sign Language Observation
Paper and Code
Nov 25, 2024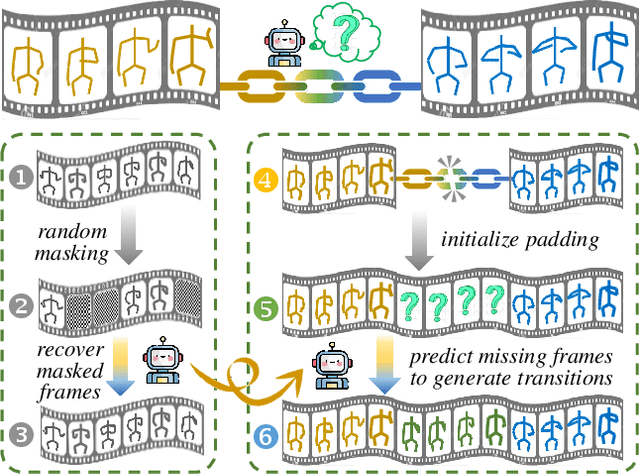
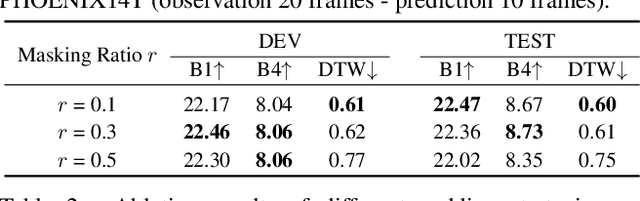
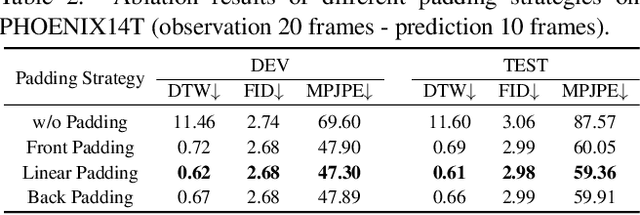
Generating continuous sign language videos from discrete segments is challenging due to the need for smooth transitions that preserve natural flow and meaning. Traditional approaches that simply concatenate isolated signs often result in abrupt transitions, disrupting video coherence. To address this, we propose a novel framework, Sign-D2C, that employs a conditional diffusion model to synthesize contextually smooth transition frames, enabling the seamless construction of continuous sign language sequences. Our approach transforms the unsupervised problem of transition frame generation into a supervised training task by simulating the absence of transition frames through random masking of segments in long-duration sign videos. The model learns to predict these masked frames by denoising Gaussian noise, conditioned on the surrounding sign observations, allowing it to handle complex, unstructured transitions. During inference, we apply a linearly interpolating padding strategy that initializes missing frames through interpolation between boundary frames, providing a stable foundation for iterative refinement by the diffusion model. Extensive experiments on the PHOENIX14T, USTC-CSL100, and USTC-SLR500 datasets demonstrate the effectiveness of our method in producing continuous, natural sign language videos.