 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Performance of Federated Person Re-identification: Benchmarking and Analysis
May 24, 2022
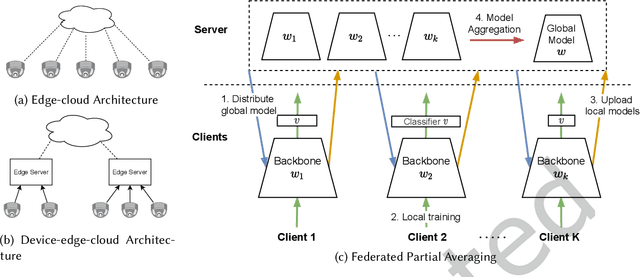


The increasingly stringent data privacy regulations limit the development of person re-identification (ReID) because person ReID training requires centralizing an enormous amount of data that contains sensitive personal information. To address this problem, we introduce federated person re-identification (FedReID) -- implementing federated learning, an emerging distributed training method, to person ReID. FedReID preserves data privacy by aggregating model updates, instead of raw data, from clients to a central server. Furthermore, we optimize the performance of FedReID under statistical heterogeneity via benchmark analysis. We first construct a benchmark with an enhanced algorithm, two architectures, and nine person ReID datasets with large variances to simulate the real-world statistical heterogeneity. The benchmark results present insights and bottlenecks of FedReID under statistical heterogeneity, including challenges in convergence and poor performance on datasets with large volumes. Based on these insights, we propose three optimization approaches: (1) We adopt knowledge distillation to facilitate the convergence of FedReID by better transferring knowledge from clients to the server; (2) We introduce client clustering to improve the performance of large datasets by aggregating clients with similar data distributions; (3) We propose cosine distance weight to elevate performance by dynamically updating the weights for aggregation depending on how well models are trained in clients. Extensive experiments demonstrate that these approaches achieve satisfying convergence with much better performance on all datasets. We believe that FedReID will shed light on implementing and optimizing federated learning on more computer vision applications.
Federated Unsupervised Domain Adaptation for Face Recognition
Apr 09, 2022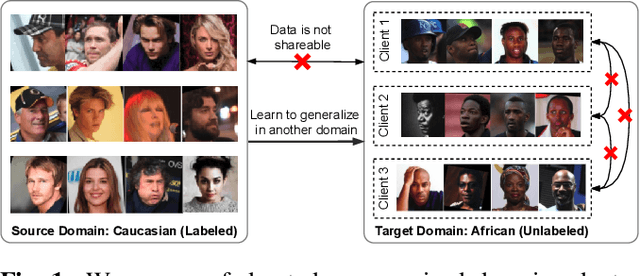

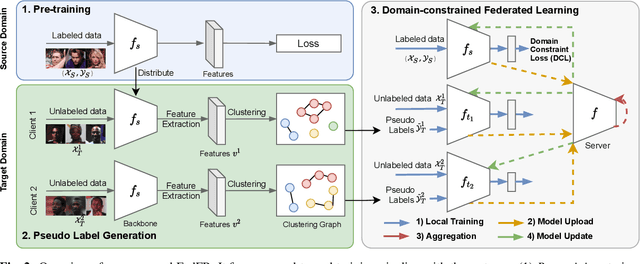
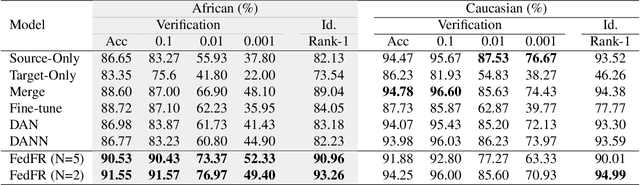
Given labeled data in a source domain, unsupervised domain adaptation has been widely adopted to generalize models for unlabeled data in a target domain, whose data distributions are different. However, existing works are inapplicable to face recognition under privacy constraints because they require sharing of sensitive face images between domains. To address this problem, we propose federated unsupervised domain adaptation for face recognition, FedFR. FedFR jointly optimizes clustering-based domain adaptation and federated learning to elevate performance on the target domain. Specifically, for unlabeled data in the target domain, we enhance a clustering algorithm with distance constrain to improve the quality of predicted pseudo labels. Besides, we propose a new domain constraint loss (DCL) to regularize source domain training in federated learning. Extensive experiments on a newly constructed benchmark demonstrate that FedFR outperforms the baseline and classic methods on the target domain by 3% to 14% on different evaluation metrics.
Collaborative Unsupervised Visual Representation Learning from Decentralized Data
Aug 14, 2021

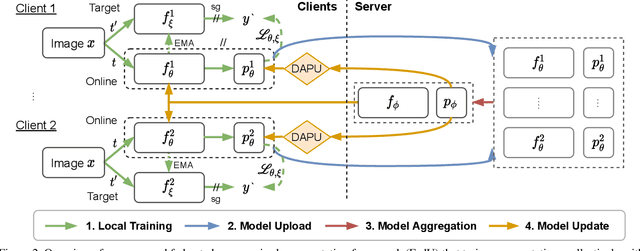

Unsupervised representation learning has achieved outstanding performances using centralized data available on the Internet. However, the increasing awareness of privacy protection limits sharing of decentralized unlabeled image data that grows explosively in multiple parties (e.g., mobile phones and cameras). As such, a natural problem is how to leverage these data to learn visual representations for downstream tasks while preserving data privacy. To address this problem, we propose a novel federated unsupervised learning framework, FedU. In this framework, each party trains models from unlabeled data independently using contrastive learning with an online network and a target network. Then, a central server aggregates trained models and updates clients' models with the aggregated model. It preserves data privacy as each party only has access to its raw data. Decentralized data among multiple parties are normally non-independent and identically distributed (non-IID), leading to performance degradation. To tackle this challenge, we propose two simple but effective methods: 1) We design the communication protocol to upload only the encoders of online networks for server aggregation and update them with the aggregated encoder; 2) We introduce a new module to dynamically decide how to update predictors based on the divergence caused by non-IID. The predictor is the other component of the online network. Extensive experiments and ablations demonstrate the effectiveness and significance of FedU. It outperforms training with only one party by over 5% and other methods by over 14% in linear and semi-supervised evaluation on non-IID data.
Towards Unsupervised Domain Adaptation for Deep Face Recognition under Privacy Constraints via Federated Learning
May 17, 2021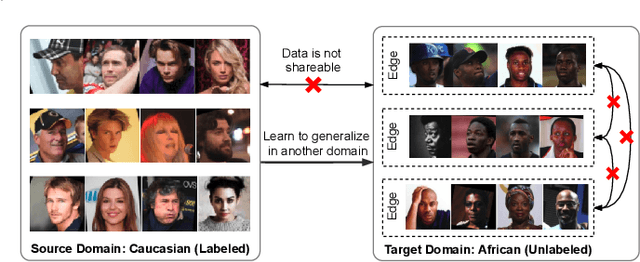

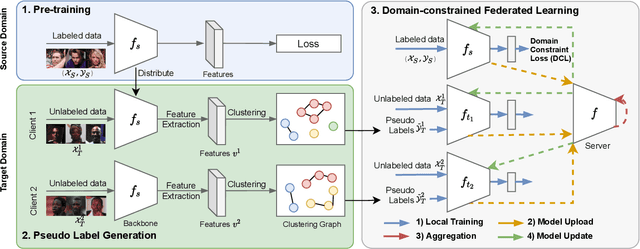
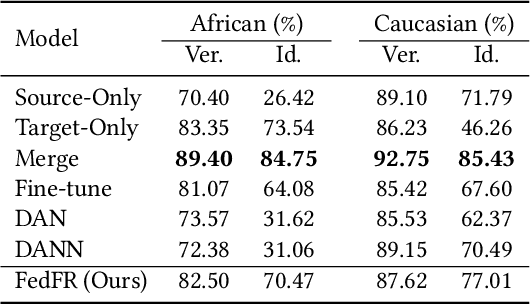
Unsupervised domain adaptation has been widely adopted to generalize models for unlabeled data in a target domain, given labeled data in a source domain, whose data distributions differ from the target domain. However, existing works are inapplicable to face recognition under privacy constraints because they require sharing sensitive face images between two domains. To address this problem, we propose a novel unsupervised federated face recognition approach (FedFR). FedFR improves the performance in the target domain by iteratively aggregating knowledge from the source domain through federated learning. It protects data privacy by transferring models instead of raw data between domains. Besides, we propose a new domain constraint loss (DCL) to regularize source domain training. DCL suppresses the data volume dominance of the source domain. We also enhance a hierarchical clustering algorithm to predict pseudo labels for the unlabeled target domain accurately. To this end, FedFR forms an end-to-end training pipeline: (1) pre-train in the source domain; (2) predict pseudo labels by clustering in the target domain; (3) conduct domain-constrained federated learning across two domains. Extensive experiments and analysis on two newly constructed benchmarks demonstrate the effectiveness of FedFR. It outperforms the baseline and classic methods in the target domain by over 4% on the more realistic benchmark. We believe that FedFR will shed light on applying federated learning to more computer vision tasks under privacy constraints.
EasyFL: A Low-code Federated Learning Platform For Dummies
May 17, 2021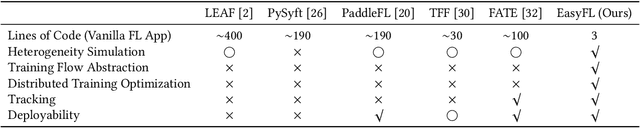



Academia and industry have developed several platforms to support the popular privacy-preserving distributed learning method -- Federated Learning (FL). However, these platforms are complex to use and require a deep understanding of FL, which imposes high barriers to entry for beginners, limits the productivity of data scientists, and compromises deployment efficiency. In this paper, we propose the first low-code FL platform, EasyFL, to enable users with various levels of expertise to experiment and prototype FL applications with little coding. We achieve this goal while ensuring great flexibility for customization by unifying simple API design, modular design, and granular training flow abstraction. With only a few lines of code, EasyFL empowers them with many out-of-the-box functionalities to accelerate experimentation and deployment. These practical functionalities are heterogeneity simulation, distributed training optimization, comprehensive tracking, and seamless deployment. They are proposed based on challenges identified in the proposed FL life cycle. Our implementations show that EasyFL requires only three lines of code to build a vanilla FL application, at least 10x lesser than other platforms. Besides, our evaluations demonstrate that EasyFL expedites training by 1.5x. It also improves the efficiency of experiments and deployment. We believe that EasyFL will increase the productivity of data scientists and democratize FL to wider audiences.
Performance Optimization for Federated Person Re-identification via Benchmark Analysis
Aug 26, 2020
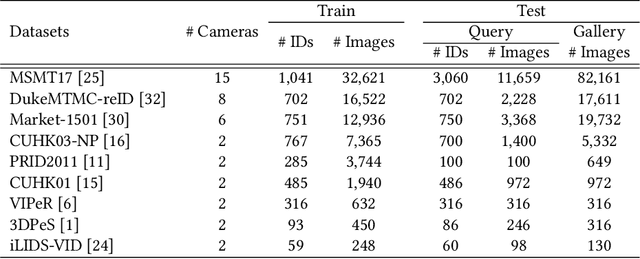
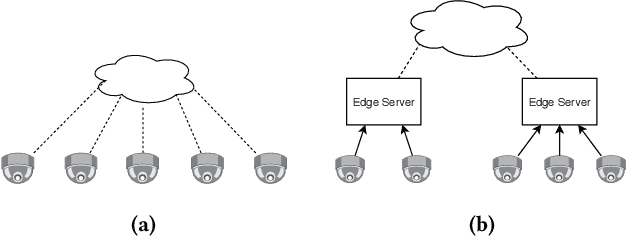
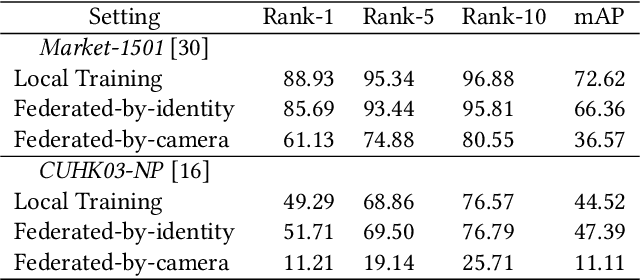
Federated learning is a privacy-preserving machine learning technique that learns a shared model across decentralized clients. It can alleviate privacy concerns of personal re-identification, an important computer vision task. In this work, we implement federated learning to person re-identification (FedReID) and optimize its performance affected by statistical heterogeneity in the real-world scenario. We first construct a new benchmark to investigate the performance of FedReID. This benchmark consists of (1) nine datasets with different volumes sourced from different domains to simulate the heterogeneous situation in reality, (2) two federated scenarios, and (3) an enhanced federated algorithm for FedReID. The benchmark analysis shows that the client-edge-cloud architecture, represented by the federated-by-dataset scenario, has better performance than client-server architecture in FedReID. It also reveals the bottlenecks of FedReID under the real-world scenario, including poor performance of large datasets caused by unbalanced weights in model aggregation and challenges in convergence. Then we propose two optimization methods: (1) To address the unbalanced weight problem, we propose a new method to dynamically change the weights according to the scale of model changes in clients in each training round; (2) To facilitate convergence, we adopt knowledge distillation to refine the server model with knowledge generated from client models on a public dataset. Experiment results demonstrate that our strategies can achieve much better convergence with superior performance on all datasets. We believe that our work will inspire the community to further explore the implementation of federated learning on more computer vision tasks in real-world scenarios.