 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Recipes for Efficient and Compact Vision-Language Models
Mar 17, 2026Deploying vision-language models (VLMs) in resource-constrained settings demands low latency and high throughput, yet existing compact VLMs often fall short of the inference speedups their smaller parameter counts suggest. To explain this discrepancy, we conduct an empirical end-to-end efficiency analysis and systematically profile inference to identify the dominant bottlenecks. Based on these findings, we develop optimization recipes tailored to compact VLMs that substantially reduce latency while preserving accuracy. These techniques cut time to first token (TTFT) by 53% on InternVL3-2B and by 93% on SmolVLM-256M. Our recipes are broadly applicable across both VLM architectures and common serving frameworks, providing practical guidance for building efficient VLM systems. Beyond efficiency, we study how to extend compact VLMs with structured perception outputs and introduce the resulting model family, ArgusVLM. Across diverse benchmarks, ArgusVLM achieves strong performance while maintaining a compact and efficient design.
UniCompress: Token Compression for Unified Vision-Language Understanding and Generation
Mar 11, 2026Unified models aim to support both understanding and generation by encoding images into discrete tokens and processing them alongside text within a single autoregressive framework. This unified design offers architectural simplicity and cross-modal synergy, which facilitates shared parameterization, consistent training objectives, and seamless transfer between modalities. However, the large number of visual tokens required by such models introduces substantial computation and memory overhead, and this inefficiency directly hinders deployment in resource constrained scenarios such as embodied AI systems. In this work, we propose a unified token compression algorithm UniCompress that significantly reduces visual token count while preserving performance on both image understanding and generation tasks. Our method introduces a plug-in compression and decompression mechanism guided with learnable global meta tokens. The framework is lightweight and modular, enabling efficient integration into existing models without full retraining. Experimental results show that our approach reduces image tokens by up to 4 times, achieves substantial gains in inference latency and training cost, and incurs only minimal performance degradation, which demonstrates the promise of token-efficient unified modeling for real world multimodal applications.
UNIFORM: Unifying Knowledge from Large-scale and Diverse Pre-trained Models
Aug 27, 2025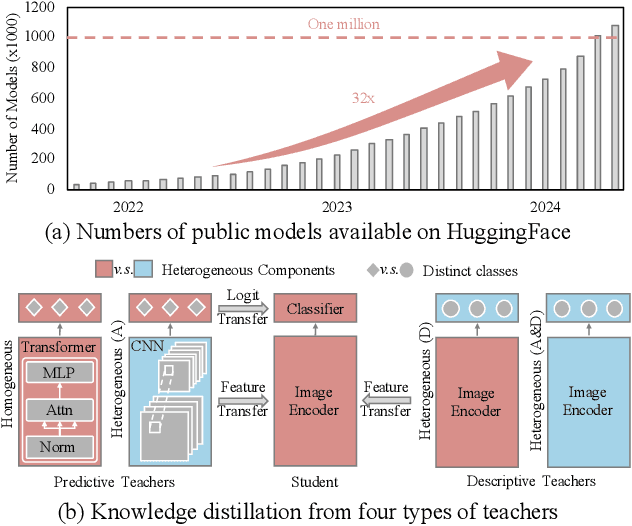
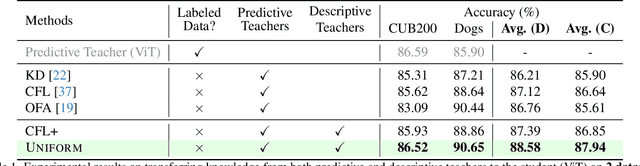
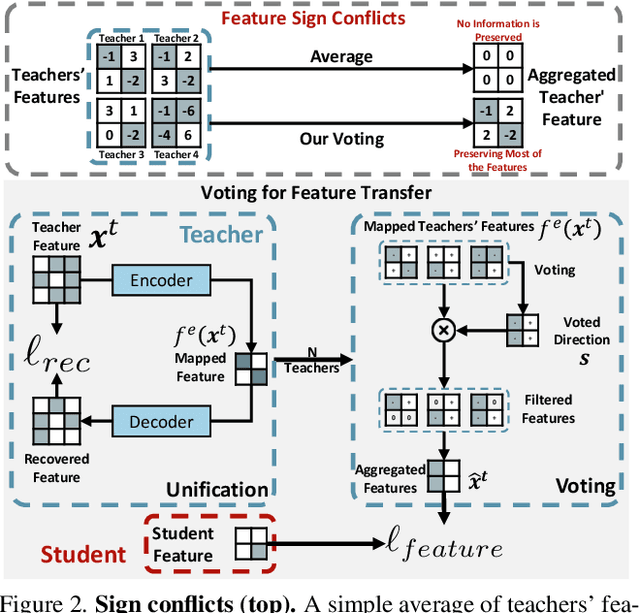
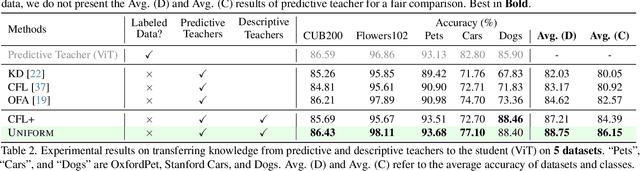
In the era of deep learning, the increasing number of pre-trained models available online presents a wealth of knowledge. These models, developed with diverse architectures and trained on varied datasets for different tasks, provide unique interpretations of the real world. Their collective consensus is likely universal and generalizable to unseen data. However, effectively harnessing this collective knowledge poses a fundamental challenge due to the heterogeneity of pre-trained models. Existing knowledge integration solutions typically rely on strong assumptions about training data distributions and network architectures, limiting them to learning only from specific types of models and resulting in data and/or inductive biases. In this work, we introduce a novel framework, namely UNIFORM, for knowledge transfer from a diverse set of off-the-shelf models into one student model without such constraints. Specifically, we propose a dedicated voting mechanism to capture the consensus of knowledge both at the logit level -- incorporating teacher models that are capable of predicting target classes of interest -- and at the feature level, utilizing visual representations learned on arbitrary label spaces. Extensive experiments demonstrate that UNIFORM effectively enhances unsupervised object recognition performance compared to strong knowledge transfer baselines. Notably, it exhibits remarkable scalability by benefiting from over one hundred teachers, while existing methods saturate at a much smaller scale.
Investigating the Design Space of Visual Grounding in Multimodal Large Language Model
Aug 11, 2025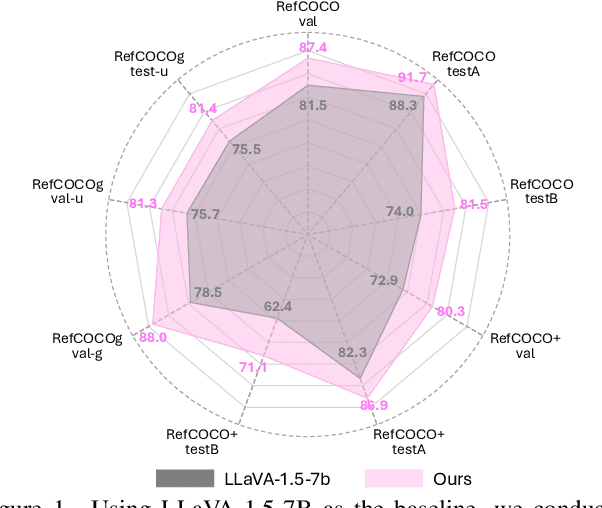
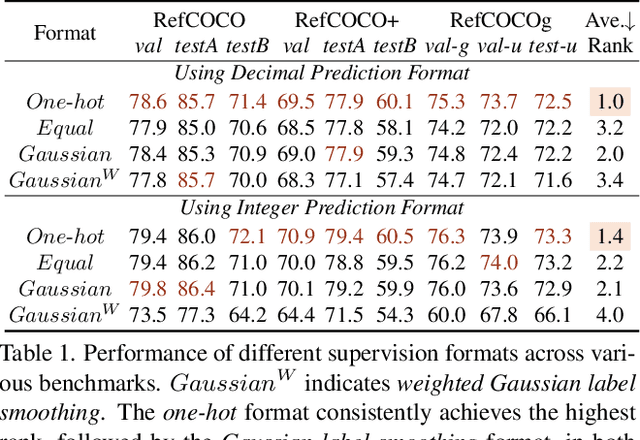
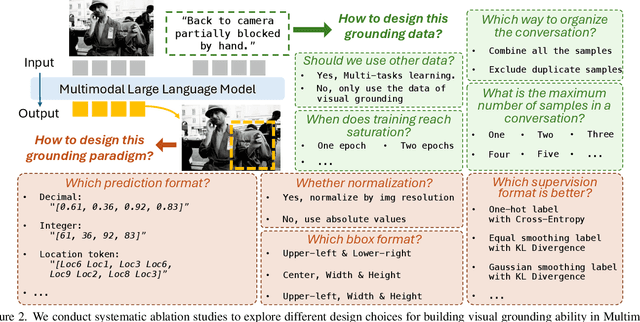
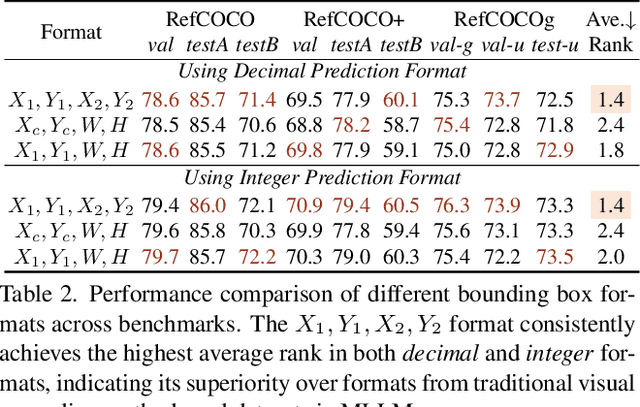
Fine-grained multimodal capability in Multimodal Large Language Models (MLLMs) has emerged as a critical research direction, particularly for tackling the visual grounding (VG) problem. Despite the strong performance achieved by existing approaches, they often employ disparate design choices when fine-tuning MLLMs for VG, lacking systematic verification to support these designs. To bridge this gap, this paper presents a comprehensive study of various design choices that impact the VG performance of MLLMs. We conduct our analysis using LLaVA-1.5, which has been widely adopted in prior empirical studies of MLLMs. While more recent models exist, we follow this convention to ensure our findings remain broadly applicable and extendable to other architectures. We cover two key aspects: (1) exploring different visual grounding paradigms in MLLMs, identifying the most effective design, and providing our insights; and (2) conducting ablation studies on the design of grounding data to optimize MLLMs' fine-tuning for the VG task. Finally, our findings contribute to a stronger MLLM for VG, achieving improvements of +5.6% / +6.9% / +7.0% on RefCOCO/+/g over the LLaVA-1.5.
Boundary Attention Constrained Zero-Shot Layout-To-Image Generation
Nov 15, 2024



Recent text-to-image diffusion models excel at generating high-resolution images from text but struggle with precise control over spatial composition and object counting. To address these challenges, several studies developed layout-to-image (L2I) approaches that incorporate layout instructions into text-to-image models. However, existing L2I methods typically require either fine-tuning pretrained parameters or training additional control modules for the diffusion models. In this work, we propose a novel zero-shot L2I approach, BACON (Boundary Attention Constrained generation), which eliminates the need for additional modules or fine-tuning. Specifically, we use text-visual cross-attention feature maps to quantify inconsistencies between the layout of the generated images and the provided instructions, and then compute loss functions to optimize latent features during the diffusion reverse process. To enhance spatial controllability and mitigate semantic failures in complex layout instructions, we leverage pixel-to-pixel correlations in the self-attention feature maps to align cross-attention maps and combine three loss functions constrained by boundary attention to update latent features. Comprehensive experimental results on both L2I and non-L2I pretrained diffusion models demonstrate that our method outperforms existing zero-shot L2I techniuqes both quantitatively and qualitatively in terms of image composition on the DrawBench and HRS benchmarks.
Dual Low-Rank Adaptation for Continual Learning with Pre-Trained Models
Nov 01, 2024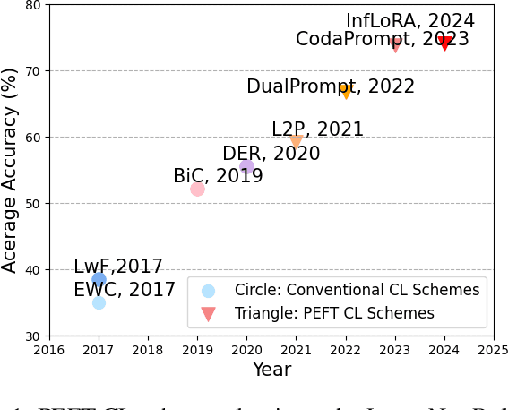
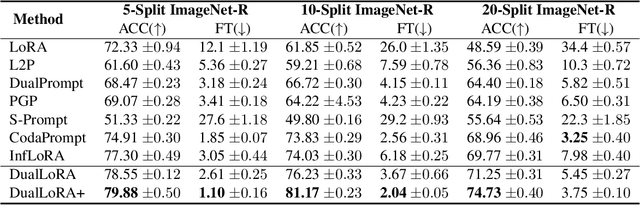
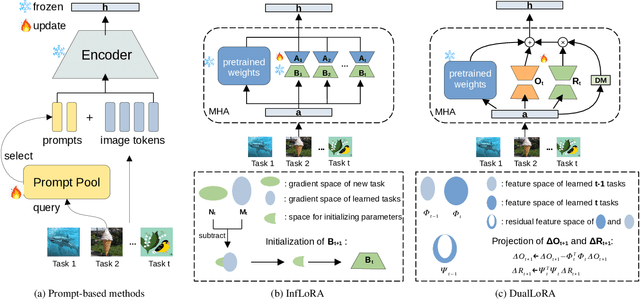
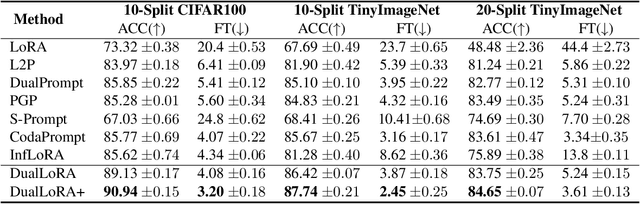
In the era of foundation models, we revisit continual learning~(CL), which aims to enable vision transformers (ViTs) to learn new tasks over time. However, as the scale of these models increases, catastrophic forgetting remains a persistent challenge, particularly in the presence of significant domain shifts across tasks. Recent studies highlight a crossover between CL techniques and parameter-efficient fine-tuning (PEFT), which focuses on fine-tuning only a small set of trainable parameters to adapt to downstream tasks, such as low-rank adaptation (LoRA). While LoRA achieves faster convergence and requires fewer trainable parameters, it has seldom been explored in the context of continual learning. To address this gap, we propose a novel PEFT-CL method called Dual Low-Rank Adaptation (DualLoRA), which introduces both an orthogonal LoRA adapter and a residual LoRA adapter parallel to pre-trained weights in each layer. These components are orchestrated by a dynamic memory mechanism to strike a balance between stability and plasticity. The orthogonal LoRA adapter's parameters are updated in an orthogonal subspace of previous tasks to mitigate catastrophic forgetting, while the residual LoRA adapter's parameters are updated in the residual subspace spanned by task-specific bases without interaction across tasks, offering complementary capabilities for fine-tuning new tasks. On ViT-based models, we demonstrate that DualLoRA offers significant advantages in accuracy, inference speed, and memory efficiency over existing CL methods across multiple benchmarks.
A Simple Background Augmentation Method for Object Detection with Diffusion Model
Aug 01, 2024



In computer vision, it is well-known that a lack of data diversity will impair model performance. In this study, we address the challenges of enhancing the dataset diversity problem in order to benefit various downstream tasks such as object detection and instance segmentation. We propose a simple yet effective data augmentation approach by leveraging advancements in generative models, specifically text-to-image synthesis technologies like Stable Diffusion. Our method focuses on generating variations of labeled real images, utilizing generative object and background augmentation via inpainting to augment existing training data without the need for additional annotations. We find that background augmentation, in particular, significantly improves the models' robustness and generalization capabilities. We also investigate how to adjust the prompt and mask to ensure the generated content comply with the existing annotations. The efficacy of our augmentation techniques is validated through comprehensive evaluations of the COCO dataset and several other key object detection benchmarks, demonstrating notable enhancements in model performance across diverse scenarios. This approach offers a promising solution to the challenges of dataset enhancement, contributing to the development of more accurate and robust computer vision models.
COALA: A Practical and Vision-Centric Federated Learning Platform
Jul 23, 2024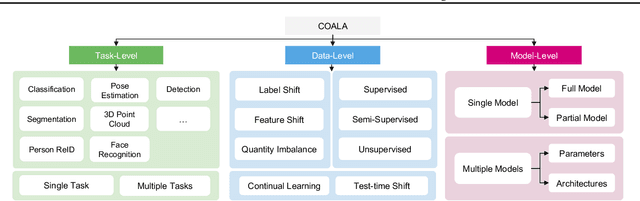

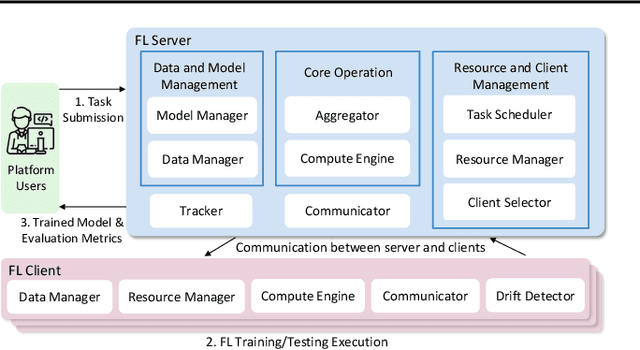
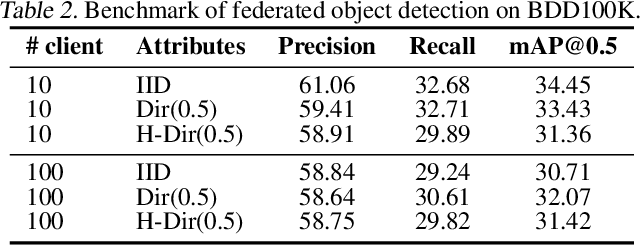
We present COALA, a vision-centric Federated Learning (FL) platform, and a suite of benchmarks for practical FL scenarios, which we categorize into three levels: task, data, and model. At the task level, COALA extends support from simple classification to 15 computer vision tasks, including object detection, segmentation, pose estimation, and more. It also facilitates federated multiple-task learning, allowing clients to tackle multiple tasks simultaneously. At the data level, COALA goes beyond supervised FL to benchmark both semi-supervised FL and unsupervised FL. It also benchmarks feature distribution shifts other than commonly considered label distribution shifts. In addition to dealing with static data, it supports federated continual learning for continuously changing data in real-world scenarios. At the model level, COALA benchmarks FL with split models and different models in different clients. COALA platform offers three degrees of customization for these practical FL scenarios, including configuration customization, components customization, and workflow customization. We conduct systematic benchmarking experiments for the practical FL scenarios and highlight potential opportunities for further advancements in FL. Codes are open sourced at https://github.com/SonyResearch/COALA.
Towards Fundamentally Scalable Model Selection: Asymptotically Fast Update and Selection
Jun 11, 2024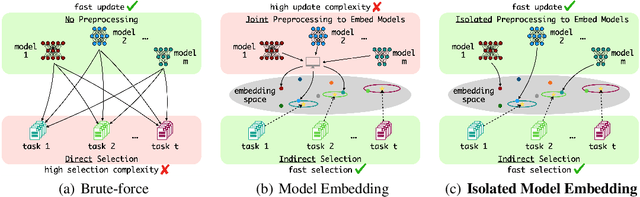

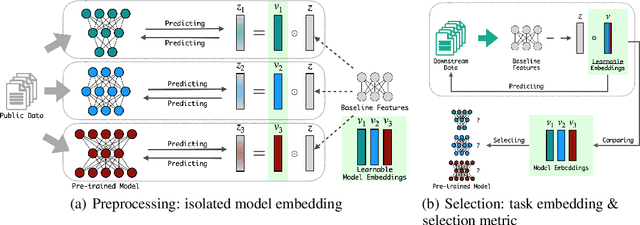
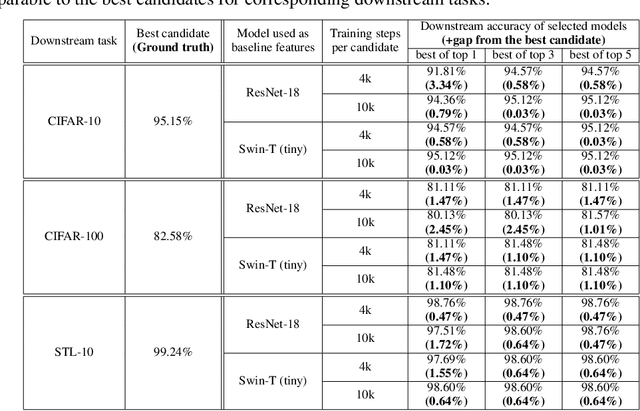
The advancement of deep learning technologies is bringing new models every day, motivating the study of scalable model selection. An ideal model selection scheme should minimally support two operations efficiently over a large pool of candidate models: update, which involves either adding a new candidate model or removing an existing candidate model, and selection, which involves locating highly performing models for a given task. However, previous solutions to model selection require high computational complexity for at least one of these two operations. In this work, we target fundamentally (more) scalable model selection that supports asymptotically fast update and asymptotically fast selection at the same time. Firstly, we define isolated model embedding, a family of model selection schemes supporting asymptotically fast update and selection: With respect to the number of candidate models $m$, the update complexity is O(1) and the selection consists of a single sweep over $m$ vectors in addition to O(1) model operations. Isolated model embedding also implies several desirable properties for applications. Secondly, we present Standardized Embedder, an empirical realization of isolated model embedding. We assess its effectiveness by using it to select representations from a pool of 100 pre-trained vision models for classification tasks and measuring the performance gaps between the selected models and the best candidates with a linear probing protocol. Experiments suggest our realization is effective in selecting models with competitive performances and highlight isolated model embedding as a promising direction towards model selection that is fundamentally (more) scalable.
FedMef: Towards Memory-efficient Federated Dynamic Pruning
Mar 21, 2024Federated learning (FL) promotes decentralized training while prioritizing data confidentiality. However, its application on resource-constrained devices is challenging due to the high demand for computation and memory resources to train deep learning models. Neural network pruning techniques, such as dynamic pruning, could enhance model efficiency, but directly adopting them in FL still poses substantial challenges, including post-pruning performance degradation, high activation memory usage, etc. To address these challenges, we propose FedMef, a novel and memory-efficient federated dynamic pruning framework. FedMef comprises two key components. First, we introduce the budget-aware extrusion that maintains pruning efficiency while preserving post-pruning performance by salvaging crucial information from parameters marked for pruning within a given budget. Second, we propose scaled activation pruning to effectively reduce activation memory footprints, which is particularly beneficial for deploying FL to memory-limited devices. Extensive experiments demonstrate the effectiveness of our proposed FedMef. In particular, it achieves a significant reduction of 28.5% in memory footprint compared to state-of-the-art methods while obtaining superior accuracy.