 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvery Step Evolves: Scaling Reinforcement Learning for Trillion-Scale Thinking Model
Oct 21, 2025



We present Ring-1T, the first open-source, state-of-the-art thinking model with a trillion-scale parameter. It features 1 trillion total parameters and activates approximately 50 billion per token. Training such models at a trillion-parameter scale introduces unprecedented challenges, including train-inference misalignment, inefficiencies in rollout processing, and bottlenecks in the RL system. To address these, we pioneer three interconnected innovations: (1) IcePop stabilizes RL training via token-level discrepancy masking and clipping, resolving instability from training-inference mismatches; (2) C3PO++ improves resource utilization for long rollouts under a token budget by dynamically partitioning them, thereby obtaining high time efficiency; and (3) ASystem, a high-performance RL framework designed to overcome the systemic bottlenecks that impede trillion-parameter model training. Ring-1T delivers breakthrough results across critical benchmarks: 93.4 on AIME-2025, 86.72 on HMMT-2025, 2088 on CodeForces, and 55.94 on ARC-AGI-v1. Notably, it attains a silver medal-level result on the IMO-2025, underscoring its exceptional reasoning capabilities. By releasing the complete 1T parameter MoE model to the community, we provide the research community with direct access to cutting-edge reasoning capabilities. This contribution marks a significant milestone in democratizing large-scale reasoning intelligence and establishes a new baseline for open-source model performance.
Ring-lite: Scalable Reasoning via C3PO-Stabilized Reinforcement Learning for LLMs
Jun 18, 2025We present Ring-lite, a Mixture-of-Experts (MoE)-based large language model optimized via reinforcement learning (RL) to achieve efficient and robust reasoning capabilities. Built upon the publicly available Ling-lite model, a 16.8 billion parameter model with 2.75 billion activated parameters, our approach matches the performance of state-of-the-art (SOTA) small-scale reasoning models on challenging benchmarks (e.g., AIME, LiveCodeBench, GPQA-Diamond) while activating only one-third of the parameters required by comparable models. To accomplish this, we introduce a joint training pipeline integrating distillation with RL, revealing undocumented challenges in MoE RL training. First, we identify optimization instability during RL training, and we propose Constrained Contextual Computation Policy Optimization(C3PO), a novel approach that enhances training stability and improves computational throughput via algorithm-system co-design methodology. Second, we empirically demonstrate that selecting distillation checkpoints based on entropy loss for RL training, rather than validation metrics, yields superior performance-efficiency trade-offs in subsequent RL training. Finally, we develop a two-stage training paradigm to harmonize multi-domain data integration, addressing domain conflicts that arise in training with mixed dataset. We will release the model, dataset, and code.
Holistic Capability Preservation: Towards Compact Yet Comprehensive Reasoning Models
Apr 09, 2025This technical report presents Ring-Lite-Distill, a lightweight reasoning model derived from our open-source Mixture-of-Experts (MoE) Large Language Models (LLMs) Ling-Lite. This study demonstrates that through meticulous high-quality data curation and ingenious training paradigms, the compact MoE model Ling-Lite can be further trained to achieve exceptional reasoning capabilities, while maintaining its parameter-efficient architecture with only 2.75 billion activated parameters, establishing an efficient lightweight reasoning architecture. In particular, in constructing this model, we have not merely focused on enhancing advanced reasoning capabilities, exemplified by high-difficulty mathematical problem solving, but rather aimed to develop a reasoning model with more comprehensive competency coverage. Our approach ensures coverage across reasoning tasks of varying difficulty levels while preserving generic capabilities, such as instruction following, tool use, and knowledge retention. We show that, Ring-Lite-Distill's reasoning ability reaches a level comparable to DeepSeek-R1-Distill-Qwen-7B, while its general capabilities significantly surpass those of DeepSeek-R1-Distill-Qwen-7B. The models are accessible at https://huggingface.co/inclusionAI
DiPrompT: Disentangled Prompt Tuning for Multiple Latent Domain Generalization in Federated Learning
Mar 11, 2024Federated learning (FL) has emerged as a powerful paradigm for learning from decentralized data, and federated domain generalization further considers the test dataset (target domain) is absent from the decentralized training data (source domains). However, most existing FL methods assume that domain labels are provided during training, and their evaluation imposes explicit constraints on the number of domains, which must strictly match the number of clients. Because of the underutilization of numerous edge devices and additional cross-client domain annotations in the real world, such restrictions may be impractical and involve potential privacy leaks. In this paper, we propose an efficient and novel approach, called Disentangled Prompt Tuning (DiPrompT), a method that tackles the above restrictions by learning adaptive prompts for domain generalization in a distributed manner. Specifically, we first design two types of prompts, i.e., global prompt to capture general knowledge across all clients and domain prompts to capture domain-specific knowledge. They eliminate the restriction on the one-to-one mapping between source domains and local clients. Furthermore, a dynamic query metric is introduced to automatically search the suitable domain label for each sample, which includes two-substep text-image alignments based on prompt tuning without labor-intensive annotation. Extensive experiments on multiple datasets demonstrate that our DiPrompT achieves superior domain generalization performance over state-of-the-art FL methods when domain labels are not provided, and even outperforms many centralized learning methods using domain labels.
Combating Data Imbalances in Federated Semi-supervised Learning with Dual Regulators
Jul 16, 2023



Federated learning has become a popular method to learn from decentralized heterogeneous data. Federated semi-supervised learning (FSSL) emerges to train models from a small fraction of labeled data due to label scarcity on decentralized clients. Existing FSSL methods assume independent and identically distributed (IID) labeled data across clients and consistent class distribution between labeled and unlabeled data within a client. This work studies a more practical and challenging scenario of FSSL, where data distribution is different not only across clients but also within a client between labeled and unlabeled data. To address this challenge, we propose a novel FSSL framework with dual regulators, FedDure.} FedDure lifts the previous assumption with a coarse-grained regulator (C-reg) and a fine-grained regulator (F-reg): C-reg regularizes the updating of the local model by tracking the learning effect on labeled data distribution; F-reg learns an adaptive weighting scheme tailored for unlabeled instances in each client. We further formulate the client model training as bi-level optimization that adaptively optimizes the model in the client with two regulators. Theoretically, we show the convergence guarantee of the dual regulators. Empirically, we demonstrate that FedDure is superior to the existing methods across a wide range of settings, notably by more than 11% on CIFAR-10 and CINIC-10 datasets.
Probing Visual-Audio Representation for Video Highlight Detection via Hard-Pairs Guided Contrastive Learning
Jun 21, 2022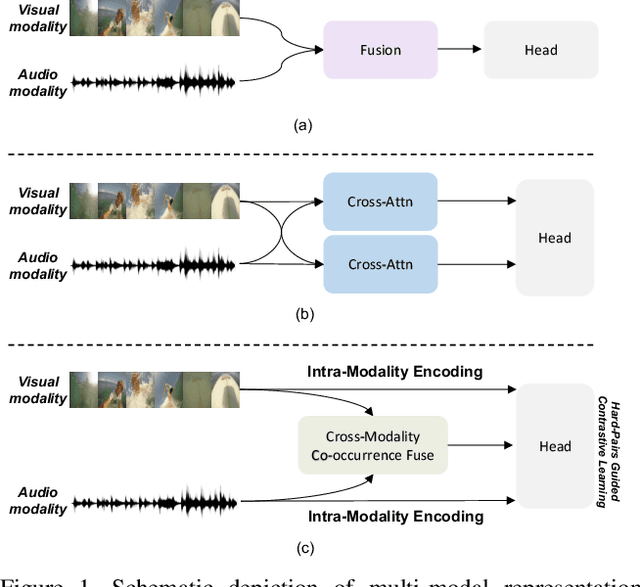

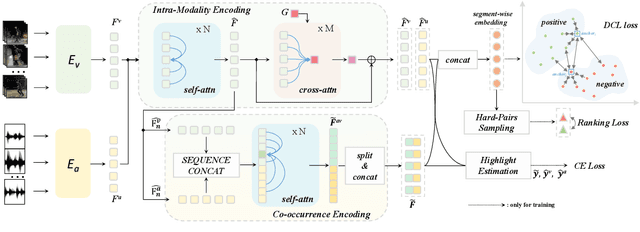
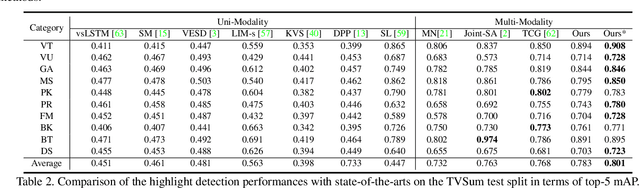
Video highlight detection is a crucial yet challenging problem that aims to identify the interesting moments in untrimmed videos. The key to this task lies in effective video representations that jointly pursue two goals, \textit{i.e.}, cross-modal representation learning and fine-grained feature discrimination. In this paper, these two challenges are tackled by not only enriching intra-modality and cross-modality relations for representation modeling but also shaping the features in a discriminative manner. Our proposed method mainly leverages the intra-modality encoding and cross-modality co-occurrence encoding for fully representation modeling. Specifically, intra-modality encoding augments the modality-wise features and dampens irrelevant modality via within-modality relation learning in both audio and visual signals. Meanwhile, cross-modality co-occurrence encoding focuses on the co-occurrence inter-modality relations and selectively captures effective information among multi-modality. The multi-modal representation is further enhanced by the global information abstracted from the local context. In addition, we enlarge the discriminative power of feature embedding with a hard-pairs guided contrastive learning (HPCL) scheme. A hard-pairs sampling strategy is further employed to mine the hard samples for improving feature discrimination in HPCL. Extensive experiments conducted on two benchmarks demonstrate the effectiveness and superiority of our proposed methods compared to other state-of-the-art methods.
Pyramid Region-based Slot Attention Network for Temporal Action Proposal Generation
Jun 21, 2022
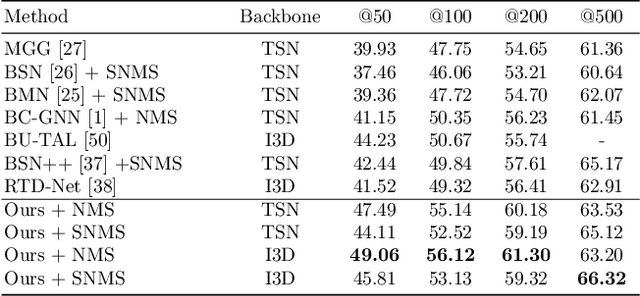
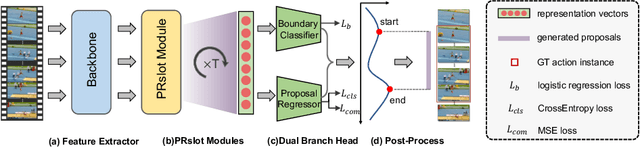

It has been found that temporal action proposal generation, which aims to discover the temporal action instances within the range of the start and end frames in the untrimmed videos, can largely benefit from proper temporal and semantic context exploitation. The latest efforts were dedicated to considering the temporal context and similarity-based semantic contexts through self-attention modules. However, they still suffer from cluttered background information and limited contextual feature learning. In this paper, we propose a novel Pyramid Region-based Slot Attention (PRSlot) module to address these issues. Instead of using the similarity computation, our PRSlot module directly learns the local relations in an encoder-decoder manner and generates the representation of a local region enhanced based on the attention over input features called \textit{slot}. Specifically, upon the input snippet-level features, PRSlot module takes the target snippet as \textit{query}, its surrounding region as \textit{key} and then generates slot representations for each \textit{query-key} slot by aggregating the local snippet context with a parallel pyramid strategy. Based on PRSlot modules, we present a novel Pyramid Region-based Slot Attention Network termed PRSA-Net to learn a unified visual representation with rich temporal and semantic context for better proposal generation. Extensive experiments are conducted on two widely adopted THUMOS14 and ActivityNet-1.3 benchmarks. Our PRSA-Net outperforms other state-of-the-art methods. In particular, we improve the AR@100 from the previous best 50.67% to 56.12% for proposal generation and raise the mAP under 0.5 tIoU from 51.9\% to 58.7\% for action detection on THUMOS14. \textit{Code is available at} \url{https://github.com/handhand123/PRSA-Net}
GroupFormer: Group Activity Recognition with Clustered Spatial-Temporal Transformer
Aug 28, 2021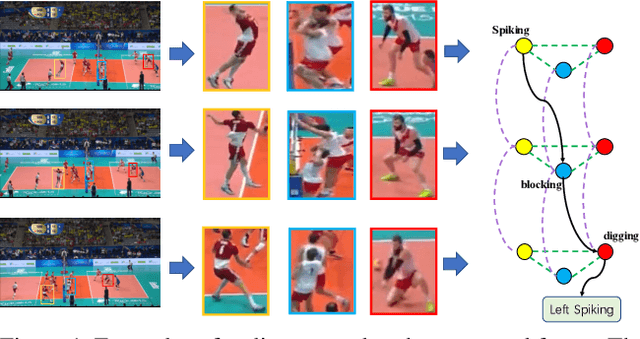
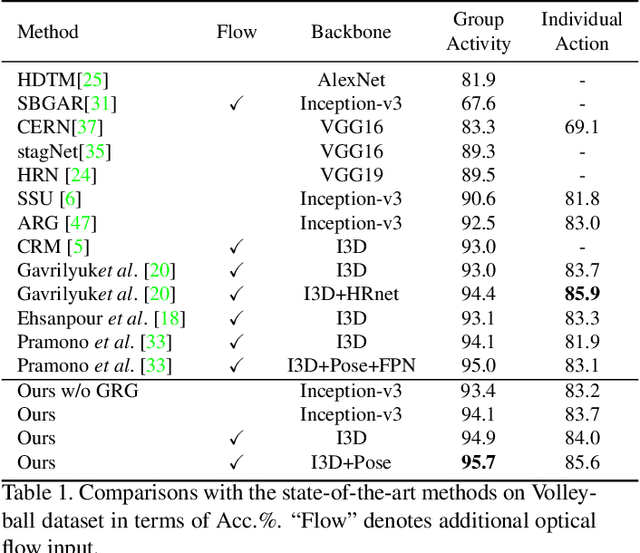
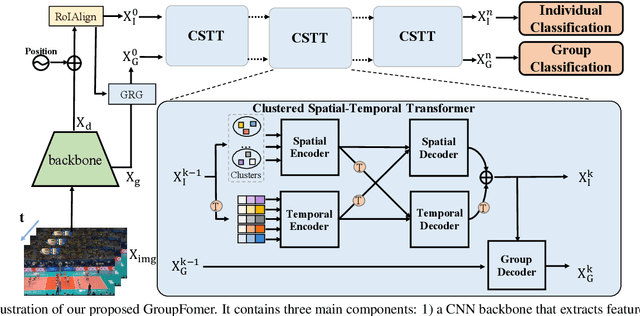
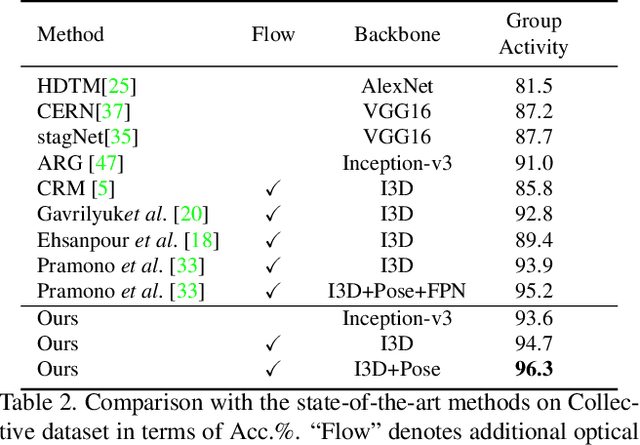
Group activity recognition is a crucial yet challenging problem, whose core lies in fully exploring spatial-temporal interactions among individuals and generating reasonable group representations. However, previous methods either model spatial and temporal information separately, or directly aggregate individual features to form group features. To address these issues, we propose a novel group activity recognition network termed GroupFormer. It captures spatial-temporal contextual information jointly to augment the individual and group representations effectively with a clustered spatial-temporal transformer. Specifically, our GroupFormer has three appealing advantages: (1) A tailor-modified Transformer, Clustered Spatial-Temporal Transformer, is proposed to enhance the individual representation and group representation. (2) It models the spatial and temporal dependencies integrally and utilizes decoders to build the bridge between the spatial and temporal information. (3) A clustered attention mechanism is utilized to dynamically divide individuals into multiple clusters for better learning activity-aware semantic representations. Moreover, experimental results show that the proposed framework outperforms state-of-the-art methods on the Volleyball dataset and Collective Activity dataset. Code is available at https://github.com/xueyee/GroupFormer.