 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat You Think is What You See: Driving Exploration in VLM Agents via Visual-Linguistic Curiosity
May 05, 2026To navigate partially observable visual environments, recent VLM agents increasingly internalize world modeling capabilities into their policies via explicit CoT reasoning, enabling them to mentally simulate futures before acting. However, relying solely on passive reasoning over visited states is insufficient for sparse-reward tasks, as it lacks the epistemic drive to actively uncover the ``known unknown'' required for robust generalization. We ask: Can VLM agents actively find signals that challenge and refine their internal world model through curiosity-driven exploration? In this work, we propose GLANCE, a unified framework that bridges reasoning and exploration by grounding the agent's linguistic world model into the stable visual representations of an evolving target network. Crucially, GLANCE leverages the discrepancy between linguistic prediction and visual reality as an intrinsic curiosity signal within reinforcement learning, steering the agent to actively explore areas where its internal model is uncertain. Extensive experiments across a series of agentic tasks show the effectiveness of GLANCE, and demonstrate that aligning ``what the agent thinks'' with ``what the agent sees'' is key to solving complex or sparse agentic tasks.
TTVS: Boosting Self-Exploring Reinforcement Learning via Test-time Variational Synthesis
Apr 09, 2026Despite significant advances in Large Reasoning Models (LRMs) driven by reinforcement learning with verifiable rewards (RLVR), this paradigm is fundamentally limited in specialized or novel domains where such supervision is prohibitively expensive or unavailable, posing a key challenge for test-time adaptation. While existing test-time methods offer a potential solution, they are constrained by learning from static query sets, risking overfitting to textual patterns. To address this gap, we introduce Test-Time Variational Synthesis (TTVS), a novel framework that enables LRMs to self-evolve by dynamically augmenting the training stream from unlabeled test queries. TTVS comprises two synergistic modules: (1) Online Variational Synthesis, which transforms static test queries into a dynamic stream of diverse, semantically-equivalent variations, enforcing the model to learn underlying problem logic rather than superficial patterns; (2) Test-time Hybrid Exploration, which balances accuracy-driven exploitation with consistency-driven exploration across synthetic variants. Extensive experiments show TTVS yields superior performance across eight model architectures. Notably, using only unlabeled test-time data, TTVS not only surpasses other test-time adaptation methods but also outperforms state-of-the-art supervised RL-based techniques trained on vast, high-quality labeled data.
DiEP: Adaptive Mixture-of-Experts Compression through Differentiable Expert Pruning
Sep 19, 2025Despite the significant breakthrough of Mixture-of-Experts (MoE), the increasing scale of these MoE models presents huge memory and storage challenges. Existing MoE pruning methods, which involve reducing parameter size with a uniform sparsity across all layers, often lead to suboptimal outcomes and performance degradation due to varying expert redundancy in different MoE layers. To address this, we propose a non-uniform pruning strategy, dubbed \textbf{Di}fferentiable \textbf{E}xpert \textbf{P}runing (\textbf{DiEP}), which adaptively adjusts pruning rates at the layer level while jointly learning inter-layer importance, effectively capturing the varying redundancy across different MoE layers. By transforming the global discrete search space into a continuous one, our method handles exponentially growing non-uniform expert combinations, enabling adaptive gradient-based pruning. Extensive experiments on five advanced MoE models demonstrate the efficacy of our method across various NLP tasks. Notably, \textbf{DiEP} retains around 92\% of original performance on Mixtral 8$\times$7B with only half the experts, outperforming other pruning methods by up to 7.1\% on the challenging MMLU dataset.
CoRE: Enhancing Metacognition with Label-free Self-evaluation in LRMs
Jul 08, 2025Large reasoning models (LRMs) have demonstrated impressive capabilities in domains like mathematics and program synthesis. Despite their strong performance, LRMs often exhibit overthinking -- excessive and redundant reasoning steps that introduce inefficiencies during inference. This phenomenon raises an important question for LRM self-evaluation: How can a model autonomously assess the correctness of its own reasoning trajectory without external labels? To address this, we propose Chain-of-Reasoning Embedding (CoRE), a series of hidden states in latent space to enable label-free self-evaluation on intermediate reasoning steps of LRMs, so as to enhance metacognition abilities for improved reasoning efficiency. By analyzing the geometric properties of the CoRE trajectories, we reveal that redundant reasoning usually presents cyclical fluctuations, which correspond to repetitive and unconscious reflection/exploration. Leveraging this insight, we further introduce a training-free, label-free self-evaluation framework, CoRE-Eval, to detect such patterns and dynamically determine whether to terminate reasoning early. Extensive experiments on mathematical reasoning benchmarks (GSM8K, MATH-500, and AIME) and across model sizes from 7B to 32B demonstrate that CoRE-Eval reduces chain-of-thought length by 13.7% to 33.2% while improving answer accuracy by around 10%, achieving 70.0% accuracy on the challenging AIME benchmark with the 32B model.
DiPrompT: Disentangled Prompt Tuning for Multiple Latent Domain Generalization in Federated Learning
Mar 11, 2024Federated learning (FL) has emerged as a powerful paradigm for learning from decentralized data, and federated domain generalization further considers the test dataset (target domain) is absent from the decentralized training data (source domains). However, most existing FL methods assume that domain labels are provided during training, and their evaluation imposes explicit constraints on the number of domains, which must strictly match the number of clients. Because of the underutilization of numerous edge devices and additional cross-client domain annotations in the real world, such restrictions may be impractical and involve potential privacy leaks. In this paper, we propose an efficient and novel approach, called Disentangled Prompt Tuning (DiPrompT), a method that tackles the above restrictions by learning adaptive prompts for domain generalization in a distributed manner. Specifically, we first design two types of prompts, i.e., global prompt to capture general knowledge across all clients and domain prompts to capture domain-specific knowledge. They eliminate the restriction on the one-to-one mapping between source domains and local clients. Furthermore, a dynamic query metric is introduced to automatically search the suitable domain label for each sample, which includes two-substep text-image alignments based on prompt tuning without labor-intensive annotation. Extensive experiments on multiple datasets demonstrate that our DiPrompT achieves superior domain generalization performance over state-of-the-art FL methods when domain labels are not provided, and even outperforms many centralized learning methods using domain labels.
Combating Data Imbalances in Federated Semi-supervised Learning with Dual Regulators
Jul 16, 2023



Federated learning has become a popular method to learn from decentralized heterogeneous data. Federated semi-supervised learning (FSSL) emerges to train models from a small fraction of labeled data due to label scarcity on decentralized clients. Existing FSSL methods assume independent and identically distributed (IID) labeled data across clients and consistent class distribution between labeled and unlabeled data within a client. This work studies a more practical and challenging scenario of FSSL, where data distribution is different not only across clients but also within a client between labeled and unlabeled data. To address this challenge, we propose a novel FSSL framework with dual regulators, FedDure.} FedDure lifts the previous assumption with a coarse-grained regulator (C-reg) and a fine-grained regulator (F-reg): C-reg regularizes the updating of the local model by tracking the learning effect on labeled data distribution; F-reg learns an adaptive weighting scheme tailored for unlabeled instances in each client. We further formulate the client model training as bi-level optimization that adaptively optimizes the model in the client with two regulators. Theoretically, we show the convergence guarantee of the dual regulators. Empirically, we demonstrate that FedDure is superior to the existing methods across a wide range of settings, notably by more than 11% on CIFAR-10 and CINIC-10 datasets.
DRPT: Disentangled and Recurrent Prompt Tuning for Compositional Zero-Shot Learning
May 02, 2023



Compositional Zero-shot Learning (CZSL) aims to recognize novel concepts composed of known knowledge without training samples. Standard CZSL either identifies visual primitives or enhances unseen composed entities, and as a result, entanglement between state and object primitives cannot be fully utilized. Admittedly, vision-language models (VLMs) could naturally cope with CZSL through tuning prompts, while uneven entanglement leads prompts to be dragged into local optimum. In this paper, we take a further step to introduce a novel Disentangled and Recurrent Prompt Tuning framework termed DRPT to better tap the potential of VLMs in CZSL. Specifically, the state and object primitives are deemed as learnable tokens of vocabulary embedded in prompts and tuned on seen compositions. Instead of jointly tuning state and object, we devise a disentangled and recurrent tuning strategy to suppress the traction force caused by entanglement and gradually optimize the token parameters, leading to a better prompt space. Notably, we develop a progressive fine-tuning procedure that allows for incremental updates to the prompts, optimizing the object first, then the state, and vice versa. Meanwhile, the optimization of state and object is independent, thus clearer features can be learned to further alleviate the issue of entangling misleading optimization. Moreover, we quantify and analyze the entanglement in CZSL and supplement entanglement rebalancing optimization schemes. DRPT surpasses representative state-of-the-art methods on extensive benchmark datasets, demonstrating superiority in both accuracy and efficiency.
Unsupervised Domain Adaptive Learning via Synthetic Data for Person Re-identification
Sep 12, 2021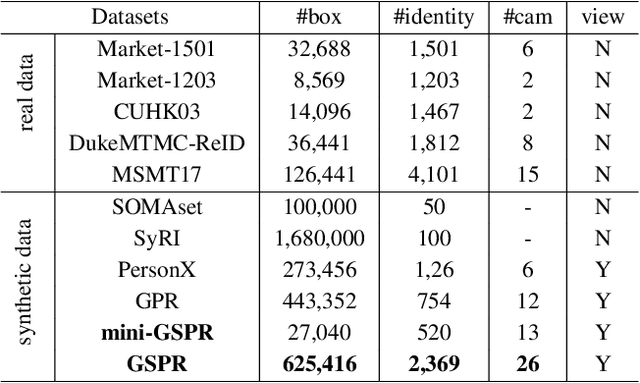
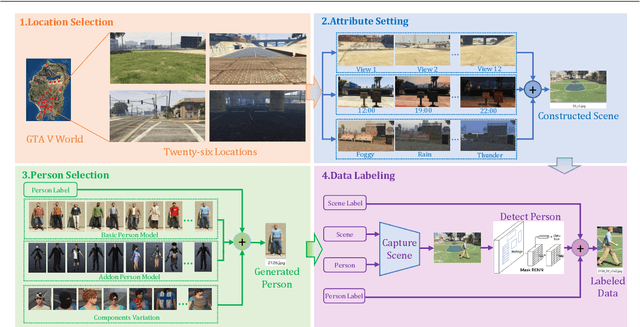
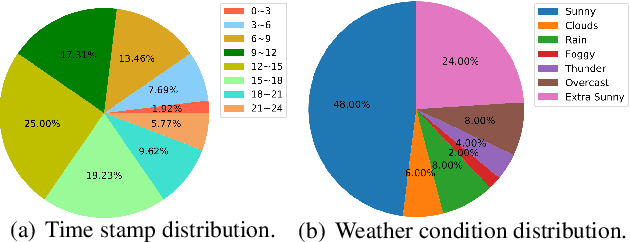
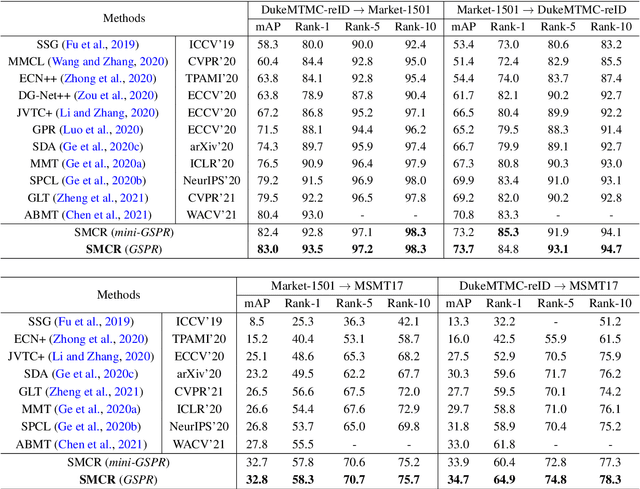
Person re-identification (re-ID) has gained more and more attention due to its widespread applications in intelligent video surveillance. Unfortunately, the mainstream deep learning methods still need a large quantity of labeled data to train models, and annotating data is an expensive work in real-world scenarios. In addition, due to domain gaps between different datasets, the performance is dramatically decreased when re-ID models pre-trained on label-rich datasets (source domain) are directly applied to other unlabeled datasets (target domain). In this paper, we attempt to remedy these problems from two aspects, namely data and methodology. Firstly, we develop a data collector to automatically generate synthetic re-ID samples in a computer game, and construct a data labeler to simultaneously annotate them, which free humans from heavy data collections and annotations. Based on them, we build two synthetic person re-ID datasets with different scales, "GSPR" and "mini-GSPR" datasets. Secondly, we propose a synthesis-based multi-domain collaborative refinement (SMCR) network, which contains a synthetic pretraining module and two collaborative-refinement modules to implement sufficient learning for the valuable knowledge from multiple domains. Extensive experiments show that our proposed framework obtains significant performance improvements over the state-of-the-art methods on multiple unsupervised domain adaptation tasks of person re-ID.