 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Domain Adaptive Learning via Synthetic Data for Person Re-identification
Paper and Code
Sep 12, 2021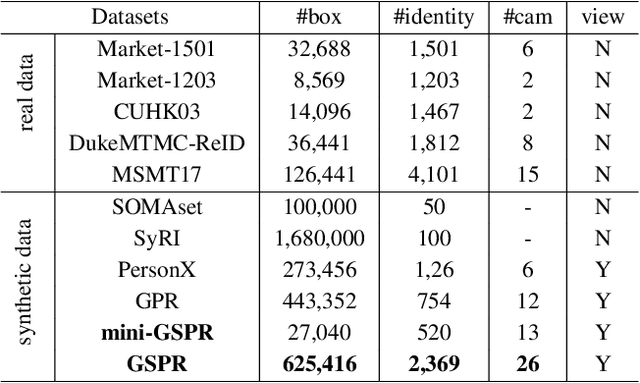
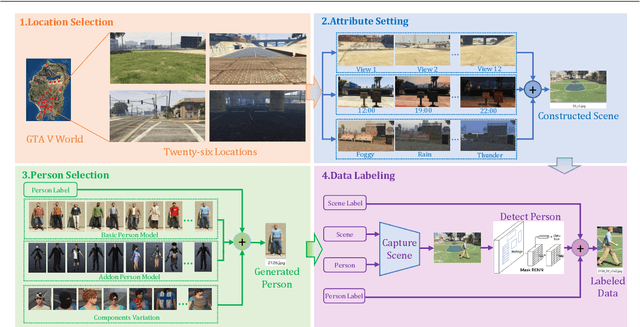
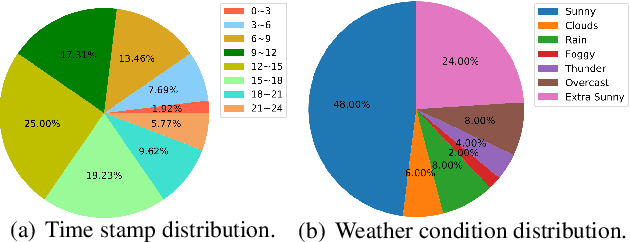
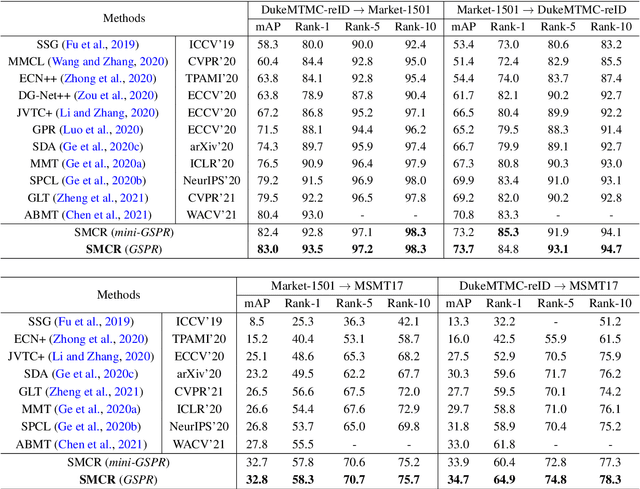
Person re-identification (re-ID) has gained more and more attention due to its widespread applications in intelligent video surveillance. Unfortunately, the mainstream deep learning methods still need a large quantity of labeled data to train models, and annotating data is an expensive work in real-world scenarios. In addition, due to domain gaps between different datasets, the performance is dramatically decreased when re-ID models pre-trained on label-rich datasets (source domain) are directly applied to other unlabeled datasets (target domain). In this paper, we attempt to remedy these problems from two aspects, namely data and methodology. Firstly, we develop a data collector to automatically generate synthetic re-ID samples in a computer game, and construct a data labeler to simultaneously annotate them, which free humans from heavy data collections and annotations. Based on them, we build two synthetic person re-ID datasets with different scales, "GSPR" and "mini-GSPR" datasets. Secondly, we propose a synthesis-based multi-domain collaborative refinement (SMCR) network, which contains a synthetic pretraining module and two collaborative-refinement modules to implement sufficient learning for the valuable knowledge from multiple domains. Extensive experiments show that our proposed framework obtains significant performance improvements over the state-of-the-art methods on multiple unsupervised domain adaptation tasks of person re-ID.