 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatialBench: Is Your Spatial Foundation Model an All-Round Player?
May 26, 2026While spatial foundation models have demonstrated impressive performance on standard datasets, a critical question remains: are they truly all-round players capable of generalizing robustly across diverse downstream tasks, arbitrary viewpoints, shifting scene domains, varying input densities, and specific hardware constraints? Answering this overarching question requires a holistic assessment, yet current models are mainly evaluated on specific domains for which they were specifically designed or trained. Such evaluations are intrinsically limited by narrow paradigm coverage, limited scene domains, and arbitrary frame sampling, making it fundamentally difficult to assess their true generalization capabilities. To address this gap, we present SpatialBench, a cross-paradigm, domain-diverse benchmark for spatial foundation models with deterministic sampling. SpatialBench features unprecedented scale and rigorous deterministic design, comprising 19 datasets and 546 scenes across 5 diverse spatial domains. It comprehensively evaluates 41 models across 6 paradigms on 5 task suites under 4 different input density settings. Our extensive evaluation reveals that current models are not yet all-round players, and uncovers crucial insights for future advancement. Specifically, we demonstrate that full-context attention maximizes accuracy while bounded-memory strategies unlock long-sequence scalability. Moreover, our empirical evaluations in challenging embodied and egocentric tasks demonstrate that strict domain alignment and high data quality are far more critical to performance than simple dataset scaling. Furthermore, to address the largest data gap identified in our analysis, we go beyond evaluation by introducing a large-scale dataset, DA-Next-5M, and a strong baseline model, DA-Next, pushing the boundaries of spatial representation learning.
TimeGuard: Channel-wise Pool Training for Backdoor Defense in Time Series Forecasting
May 21, 2026Time Series Forecasting (TSF) plays a critical role across many domains, yet it is vulnerable to backdoor attacks. However, backdoor defenses tailored to TSF remain underexplored, due to data entanglement and task-formulation shift challenges. To fill this gap, we conduct a systematic evaluation of thirteen representative backdoor defenses across the TSF life cycle and analyze their failure modes. Our results reveal two fundamental issues: (1) data entanglement induces channel-level signal dilution, rendering sample-filtering and trigger-synthesis defenses ineffective at localizing backdoors; and (2) task-formulation shift leads to training-loss degeneration, causing poisoned and clean windows to become indistinguishable at training stages. Based on these findings, we propose a training-time backdoor defense for TSF, termed TimeGuard. Our method adopts channel-wise pool training as the core paradigm and initializes a high-confidence pool using time-aware criteria to mitigate signal dilution. Moreover, we introduce distance-regularized loss selection to progressively expand the reliable pool during training and ease loss degeneration. Extensive experiments across multiple datasets, forecasting architectures, and TSF backdoor attacks demonstrate that TimeGuard substantially improves robustness, boosting $\mathrm{MAE}_\mathrm{P}$ by $1.96\times$ over the leading baseline, while preserving clean performance within 5% $\mathrm{MAE}_\mathrm{C}$.
Towards Robust Multimodal Learning in the Open World
Nov 13, 2025



The rapid evolution of machine learning has propelled neural networks to unprecedented success across diverse domains. In particular, multimodal learning has emerged as a transformative paradigm, leveraging complementary information from heterogeneous data streams (e.g., text, vision, audio) to advance contextual reasoning and intelligent decision-making. Despite these advancements, current neural network-based models often fall short in open-world environments characterized by inherent unpredictability, where unpredictable environmental composition dynamics, incomplete modality inputs, and spurious distributions relations critically undermine system reliability. While humans naturally adapt to such dynamic, ambiguous scenarios, artificial intelligence systems exhibit stark limitations in robustness, particularly when processing multimodal signals under real-world complexity. This study investigates the fundamental challenge of multimodal learning robustness in open-world settings, aiming to bridge the gap between controlled experimental performance and practical deployment requirements.
Self-Introspective Decoding: Alleviating Hallucinations for Large Vision-Language Models
Aug 04, 2024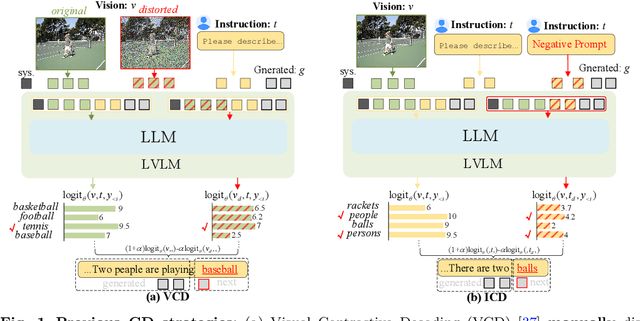
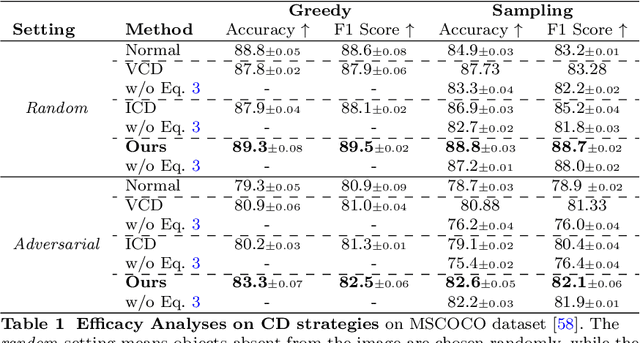
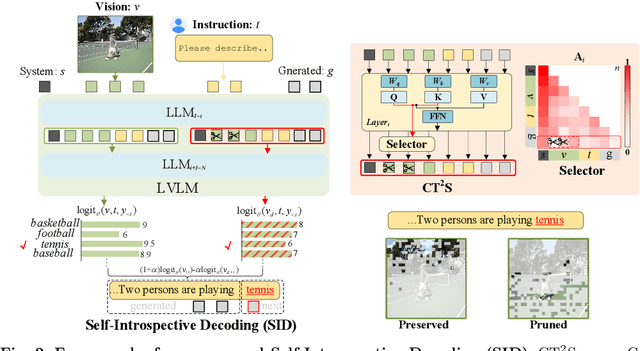
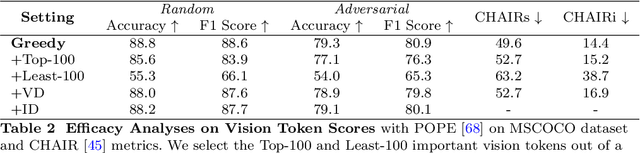
While Large Vision-Language Models (LVLMs) have rapidly advanced in recent years, the prevalent issue known as the `hallucination' problem has emerged as a significant bottleneck, hindering their real-world deployments. Existing methods mitigate this issue mainly from two perspectives: One approach leverages extra knowledge like robust instruction tuning LVLMs with curated datasets or employing auxiliary analysis networks, which inevitable incur additional costs. Another approach, known as contrastive decoding, induces hallucinations by manually disturbing the vision or instruction raw inputs and mitigates them by contrasting the outputs of the disturbed and original LVLMs. However, these approaches rely on empirical holistic input disturbances and double the inference cost. To avoid these issues, we propose a simple yet effective method named Self-Introspective Decoding (SID). Our empirical investigation reveals that pretrained LVLMs can introspectively assess the importance of vision tokens based on preceding vision and text (both instruction and generated) tokens. We develop the Context and Text-aware Token Selection (CT2S) strategy, which preserves only unimportant vision tokens after early layers of LVLMs to adaptively amplify text-informed hallucination during the auto-regressive decoding. This approach ensures that multimodal knowledge absorbed in the early layers induces multimodal contextual rather than aimless hallucinations. Subsequently, the original token logits subtract the amplified vision-and-text association hallucinations, guiding LVLMs decoding faithfully. Extensive experiments illustrate SID generates less-hallucination and higher-quality texts across various metrics, without extra knowledge and much additional computation burdens.
DRPT: Disentangled and Recurrent Prompt Tuning for Compositional Zero-Shot Learning
May 02, 2023



Compositional Zero-shot Learning (CZSL) aims to recognize novel concepts composed of known knowledge without training samples. Standard CZSL either identifies visual primitives or enhances unseen composed entities, and as a result, entanglement between state and object primitives cannot be fully utilized. Admittedly, vision-language models (VLMs) could naturally cope with CZSL through tuning prompts, while uneven entanglement leads prompts to be dragged into local optimum. In this paper, we take a further step to introduce a novel Disentangled and Recurrent Prompt Tuning framework termed DRPT to better tap the potential of VLMs in CZSL. Specifically, the state and object primitives are deemed as learnable tokens of vocabulary embedded in prompts and tuned on seen compositions. Instead of jointly tuning state and object, we devise a disentangled and recurrent tuning strategy to suppress the traction force caused by entanglement and gradually optimize the token parameters, leading to a better prompt space. Notably, we develop a progressive fine-tuning procedure that allows for incremental updates to the prompts, optimizing the object first, then the state, and vice versa. Meanwhile, the optimization of state and object is independent, thus clearer features can be learned to further alleviate the issue of entangling misleading optimization. Moreover, we quantify and analyze the entanglement in CZSL and supplement entanglement rebalancing optimization schemes. DRPT surpasses representative state-of-the-art methods on extensive benchmark datasets, demonstrating superiority in both accuracy and efficiency.
Offline-Online Class-incremental Continual Learning via Dual-prototype Self-augment and Refinement
Mar 20, 2023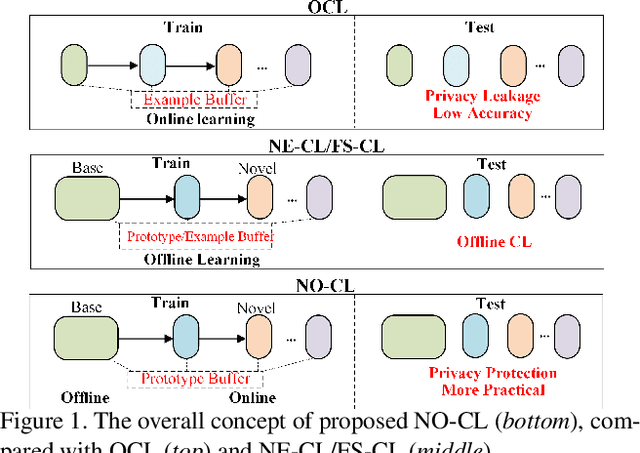

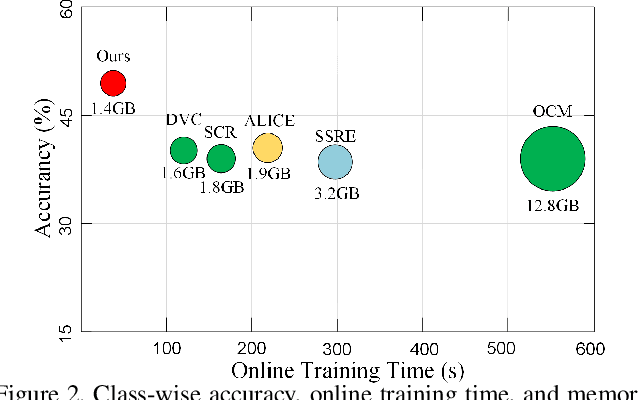

This paper investigates a new, practical, but challenging problem named Offline-Online Class-incremental Continual Learning (O$^2$CL), which aims to preserve the discernibility of pre-trained (i.e., offline) base classes without buffering data examples, and efficiently learn novel classes continuously in a single-pass (i.e., online) data stream. The challenges of this task are mainly two-fold: 1) Both base and novel classes suffer from severe catastrophic forgetting as no previous samples are available for replay. 2) As the online data can only be observed once, there is no way to fully re-train the whole model, e.g., re-calibrate the decision boundaries via prototype alignment or feature distillation. In this paper, we propose a novel Dual-prototype Self-augment and Refinement method (DSR) for O$^2$CL problem, which consists of two strategies: 1) Dual class prototypes: Inner and hyper-dimensional prototypes are exploited to utilize the pre-trained information and obtain robust quasi-orthogonal representations rather than example buffers for both privacy preservation and memory reduction. 2) Self-augment and refinement: Instead of updating the whole network, we jointly optimize the extra projection module with the self-augment inner prototypes from base and novel classes, gradually refining the hyper-dimensional prototypes to obtain accurate decision boundaries for learned classes. Extensive experiments demonstrate the effectiveness and superiority of the proposed DSR in O$^2$CL.
ProCC: Progressive Cross-primitive Consistency for Open-World Compositional Zero-Shot Learning
Nov 24, 2022Open-World Compositional Zero-shot Learning (OW-CZSL) aims to recognize novel compositions of state and object primitives in images with no priors on the compositional space, which induces a tremendously large output space containing all possible state-object compositions. Existing works either learn the joint compositional state-object embedding or predict simple primitives with separate classifiers. However, the former heavily relies on external word embedding methods, and the latter ignores the interactions of interdependent primitives, respectively. In this paper, we revisit the primitive prediction approach and propose a novel method, termed Progressive Cross-primitive Consistency (ProCC), to mimic the human learning process for OW-CZSL tasks. Specifically, the cross-primitive consistency module explicitly learns to model the interactions of state and object features with the trainable memory units, which efficiently acquires cross-primitive visual attention and avoids cross-primitive feasibility scores. Moreover, considering the partial-supervision setting (pCZSL) as well as the imbalance issue of multiple tasks prediction, we design a progressive training paradigm to enable the primitive classifiers to interact to obtain discriminative information in an easy-to-hard manner. Extensive experiments on three widely used benchmark datasets demonstrate that our method outperforms other representative methods on both OW-CZSL and pCZSL settings by l
REQA: Coarse-to-fine Assessment of Image Quality to Alleviate the Range Effect
Sep 05, 2022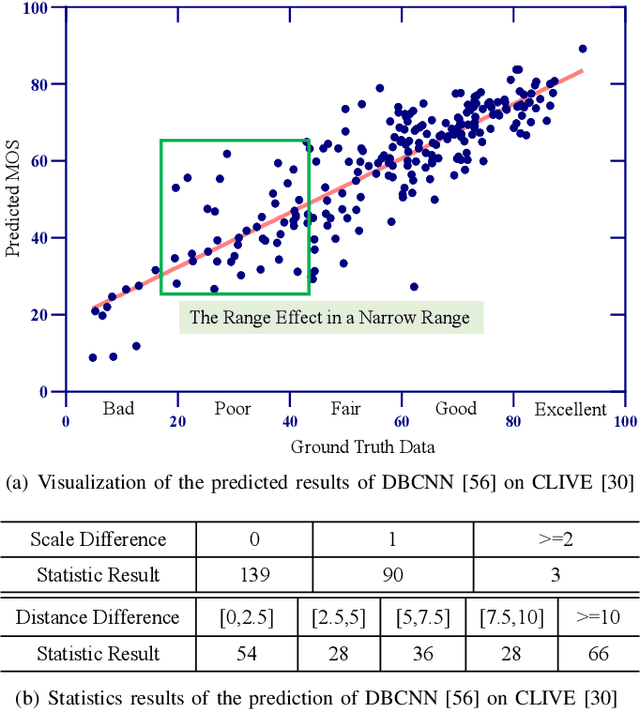
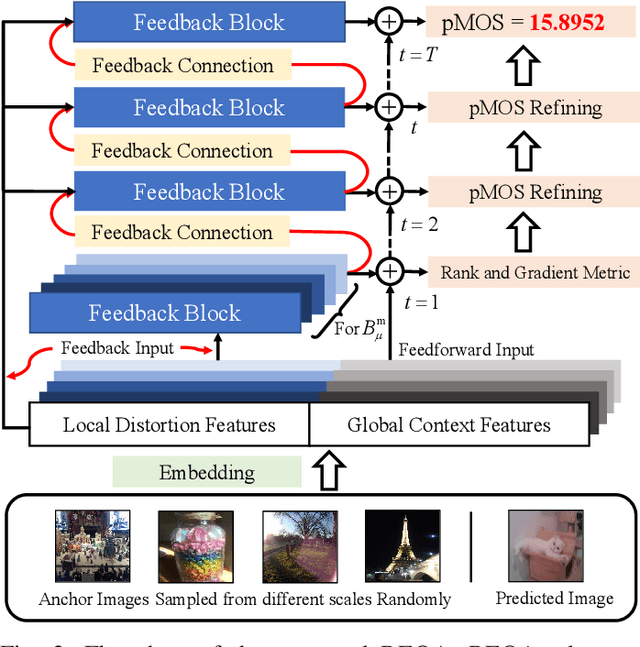
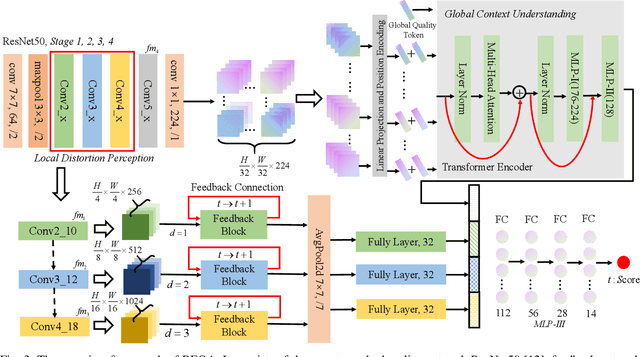

Blind image quality assessment (BIQA) of user generated content (UGC) suffers from the range effect which indicates that on the overall quality range, mean opinion score (MOS) and predicted MOS (pMOS) are well correlated; focusing on a particular range, the correlation is lower. The reason for the range effect is that the predicted deviations both in a wide range and in a narrow range destroy the uniformity between MOS and pMOS. To tackle this problem, a novel method is proposed from coarse-grained metric to fine-grained prediction. Firstly, we design a rank-and-gradient loss for coarse-grained metric. The loss keeps the order and grad consistency between pMOS and MOS, thereby reducing the predicted deviation in a wide range. Secondly, we propose multi-level tolerance loss to make fine-grained prediction. The loss is constrained by a decreasing threshold to limite the predicted deviation in narrower and narrower ranges. Finally, we design a feedback network to conduct the coarse-to-fine assessment. On the one hand, the network adopts feedback blocks to process multi-scale distortion features iteratively and on the other hand, it fuses non-local context feature to the output of each iteration to acquire more quality-aware feature representation. Experimental results demonstrate that the proposed method can alleviate the range effect compared to the state-of-the-art methods effectively.
Towards Unbiased Multi-label Zero-Shot Learning with Pyramid and Semantic Attention
Mar 07, 2022
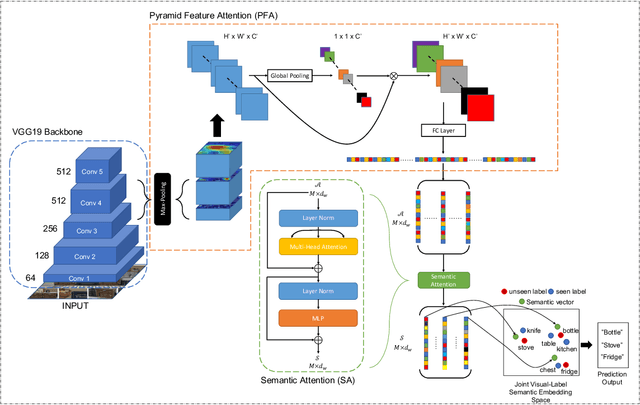

Multi-label zero-shot learning extends conventional single-label zero-shot learning to a more realistic scenario that aims at recognizing multiple unseen labels of classes for each input sample. Existing works usually exploit attention mechanism to generate the correlation among different labels. However, most of them are usually biased on several major classes while neglect most of the minor classes with the same importance in input samples, and may thus result in overly diffused attention maps that cannot sufficiently cover minor classes. We argue that disregarding the connection between major and minor classes, i.e., correspond to the global and local information, respectively, is the cause of the problem. In this paper, we propose a novel framework of unbiased multi-label zero-shot learning, by considering various class-specific regions to calibrate the training process of the classifier. Specifically, Pyramid Feature Attention (PFA) is proposed to build the correlation between global and local information of samples to balance the presence of each class. Meanwhile, for the generated semantic representations of input samples, we propose Semantic Attention (SA) to strengthen the element-wise correlation among these vectors, which can encourage the coordinated representation of them. Extensive experiments on the large-scale multi-label zero-shot benchmarks NUS-WIDE and Open-Image demonstrate that the proposed method surpasses other representative methods by significant margins.