 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePACC: Protocol-Aware Cross-Layer Compression for Compact Network Traffic Representation
Feb 09, 2026Network traffic classification is a core primitive for network security and management, yet it is increasingly challenged by pervasive encryption and evolving protocols. A central bottleneck is representation: hand-crafted flow statistics are efficient but often too lossy, raw-bit encodings can be accurate but are costly, and recent pre-trained embeddings provide transfer but frequently flatten the protocol stack and entangle signals across layers. We observe that real traffic contains substantial redundancy both across network layers and within each layer; existing paradigms do not explicitly identify and remove this redundancy, leading to wasted capacity, shortcut learning, and degraded generalization. To address this, we propose PACC, a redundancy-aware, layer-aware representation framework. PACC treats the protocol stack as multi-view inputs and learns compact layer-wise projections that remain faithful to each layer while explicitly factorizing representations into shared (cross-layer) and private (layer-specific) components. We operationalize these goals with a joint objective that preserves layer-specific information via reconstruction, captures shared structure via contrastive mutual-information learning, and maximizes task-relevant information via supervised losses, yielding compact latents suitable for efficient inference. Across datasets covering encrypted application classification, IoT device identification, and intrusion detection, PACC consistently outperforms feature-engineered and raw-bit baselines. On encrypted subsets, it achieves up to a 12.9% accuracy improvement over nPrint. PACC matches or surpasses strong foundation-model baselines. At the same time, it improves end-to-end efficiency by up to 3.16x.
PulseMind: A Multi-Modal Medical Model for Real-World Clinical Diagnosis
Jan 12, 2026Recent advances in medical multi-modal models focus on specialized image analysis like dermatology, pathology, or radiology. However, they do not fully capture the complexity of real-world clinical diagnostics, which involve heterogeneous inputs and require ongoing contextual understanding during patient-physician interactions. To bridge this gap, we introduce PulseMind, a new family of multi-modal diagnostic models that integrates a systematically curated dataset, a comprehensive evaluation benchmark, and a tailored training framework. Specifically, we first construct a diagnostic dataset, MediScope, which comprises 98,000 real-world multi-turn consultations and 601,500 medical images, spanning over 10 major clinical departments and more than 200 sub-specialties. Then, to better reflect the requirements of real-world clinical diagnosis, we develop the PulseMind Benchmark, a multi-turn diagnostic consultation benchmark with a four-dimensional evaluation protocol comprising proactiveness, accuracy, usefulness, and language quality. Finally, we design a training framework tailored for multi-modal clinical diagnostics, centered around a core component named Comparison-based Reinforcement Policy Optimization (CRPO). Compared to absolute score rewards, CRPO uses relative preference signals from multi-dimensional com-parisons to provide stable and human-aligned training guidance. Extensive experiments demonstrate that PulseMind achieves competitive performance on both the diagnostic consultation benchmark and public medical benchmarks.
$λ$-GRPO: Unifying the GRPO Frameworks with Learnable Token Preferences
Oct 08, 2025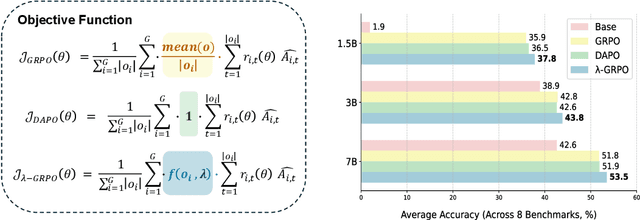
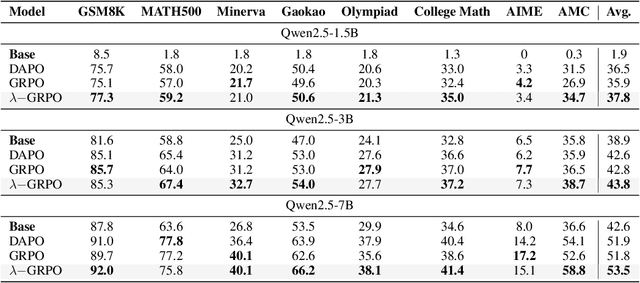
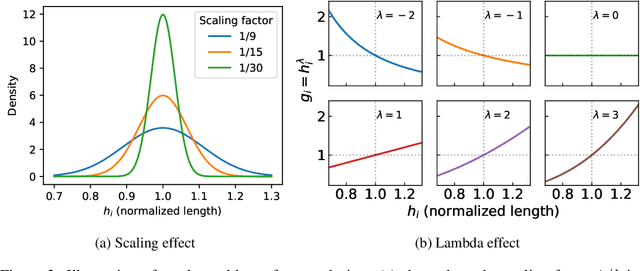

Reinforcement Learning with Human Feedback (RLHF) has been the dominant approach for improving the reasoning capabilities of Large Language Models (LLMs). Recently, Reinforcement Learning with Verifiable Rewards (RLVR) has simplified this paradigm by replacing the reward and value models with rule-based verifiers. A prominent example is Group Relative Policy Optimization (GRPO). However, GRPO inherently suffers from a length bias, since the same advantage is uniformly assigned to all tokens of a response. As a result, longer responses distribute the reward over more tokens and thus contribute disproportionately to gradient updates. Several variants, such as DAPO and Dr. GRPO, modify the token-level aggregation of the loss, yet these methods remain heuristic and offer limited interpretability regarding their implicit token preferences. In this work, we explore the possibility of allowing the model to learn its own token preference during optimization. We unify existing frameworks under a single formulation and introduce a learnable parameter $\lambda$ that adaptively controls token-level weighting. We use $\lambda$-GRPO to denote our method, and we find that $\lambda$-GRPO achieves consistent improvements over vanilla GRPO and DAPO on multiple mathematical reasoning benchmarks. On Qwen2.5 models with 1.5B, 3B, and 7B parameters, $\lambda$-GRPO improves average accuracy by $+1.9\%$, $+1.0\%$, and $+1.7\%$ compared to GRPO, respectively. Importantly, these gains come without any modifications to the training data or additional computational cost, highlighting the effectiveness and practicality of learning token preferences.
Algorithmic Data Minimization for Machine Learning over Internet-of-Things Data Streams
Mar 07, 2025
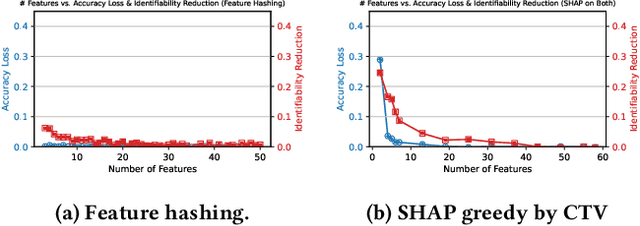
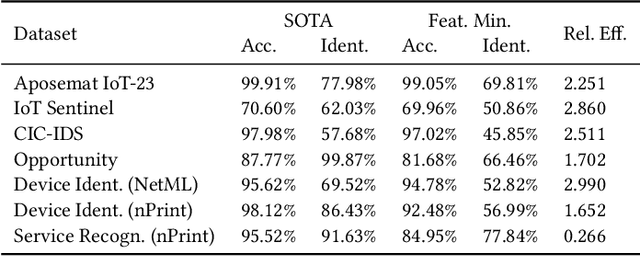
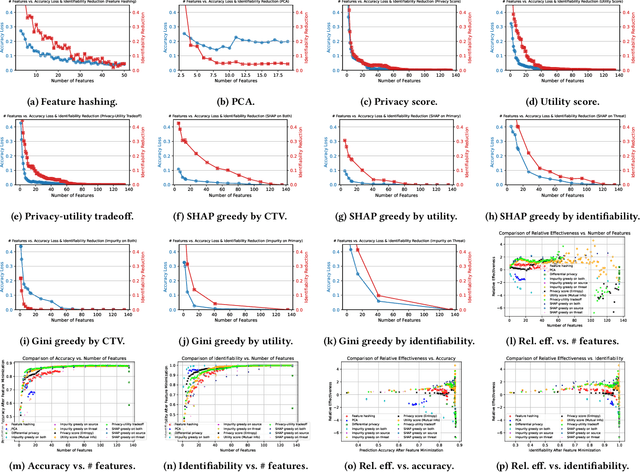
Machine learning can analyze vast amounts of data generated by IoT devices to identify patterns, make predictions, and enable real-time decision-making. By processing sensor data, machine learning models can optimize processes, improve efficiency, and enhance personalized user experiences in smart systems. However, IoT systems are often deployed in sensitive environments such as households and offices, where they may inadvertently expose identifiable information, including location, habits, and personal identifiers. This raises significant privacy concerns, necessitating the application of data minimization -- a foundational principle in emerging data regulations, which mandates that service providers only collect data that is directly relevant and necessary for a specified purpose. Despite its importance, data minimization lacks a precise technical definition in the context of sensor data, where collections of weak signals make it challenging to apply a binary "relevant and necessary" rule. This paper provides a technical interpretation of data minimization in the context of sensor streams, explores practical methods for implementation, and addresses the challenges involved. Through our approach, we demonstrate that our framework can reduce user identifiability by up to 16.7% while maintaining accuracy loss below 1%, offering a viable path toward privacy-preserving IoT data processing.
Generative Active Adaptation for Drifting and Imbalanced Network Intrusion Detection
Mar 04, 2025



Machine learning has shown promise in network intrusion detection systems, yet its performance often degrades due to concept drift and imbalanced data. These challenges are compounded by the labor-intensive process of labeling network traffic, especially when dealing with evolving and rare attack types, which makes selecting the right data for adaptation difficult. To address these issues, we propose a generative active adaptation framework that minimizes labeling effort while enhancing model robustness. Our approach employs density-aware active sampling to identify the most informative samples for annotation and leverages deep generative models to synthesize diverse samples, thereby augmenting the training set and mitigating the effects of concept drift. We evaluate our end-to-end framework on both simulated IDS data and a real-world ISP dataset, demonstrating significant improvements in intrusion detection performance. Our method boosts the overall F1-score from 0.60 (without adaptation) to 0.86. Rare attacks such as Infiltration, Web Attack, and FTP-BruteForce, which originally achieve F1 scores of 0.001, 0.04, and 0.00, improve to 0.30, 0.50, and 0.71, respectively, with generative active adaptation in the CIC-IDS 2018 dataset. Our framework effectively enhances rare attack detection while reducing labeling costs, making it a scalable and adaptive solution for real-world intrusion detection.
Research on Improved U-net Based Remote Sensing Image Segmentation Algorithm
Aug 22, 2024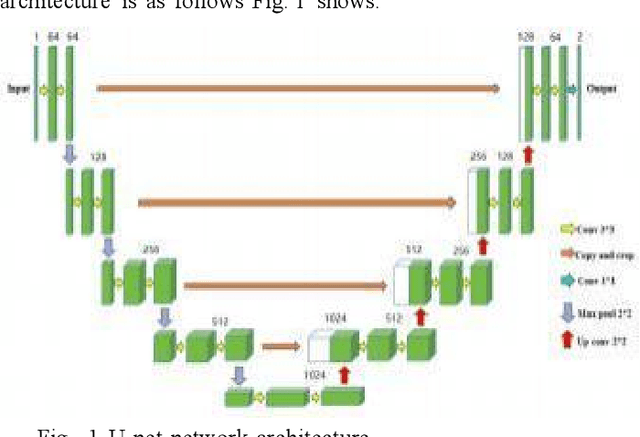
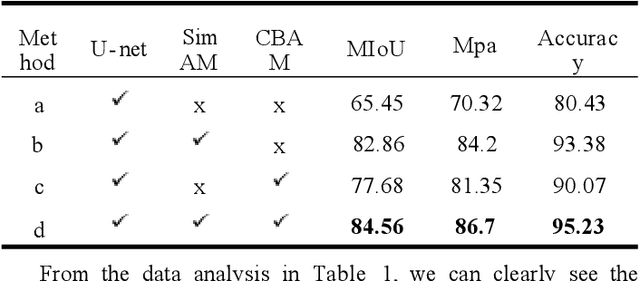
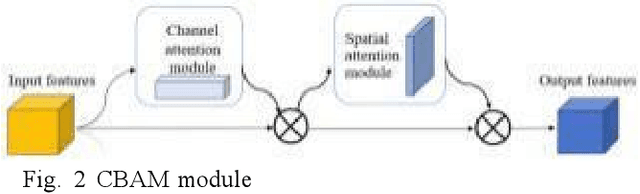
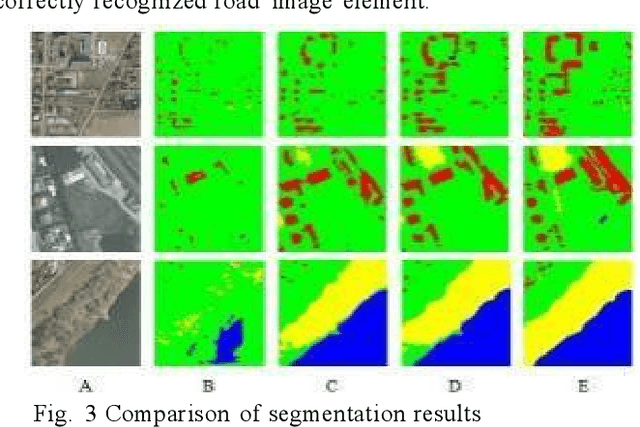
In recent years, although U-Net network has made significant progress in the field of image segmentation, it still faces performance bottlenecks in remote sensing image segmentation. In this paper, we innovatively propose to introduce SimAM and CBAM attention mechanism in U-Net, and the experimental results show that after adding SimAM and CBAM modules alone, the model improves 17.41% and 12.23% in MIoU, and the Mpa and Accuracy are also significantly improved. And after fusing the two,the model performance jumps up to 19.11% in MIoU, and the Mpa and Accuracy are also improved by 16.38% and 14.8% respectively, showing excellent segmentation accuracy and visual effect with strong generalization ability and robustness. This study opens up a new path for remote sensing image segmentation technology and has important reference value for algorithm selection and improvement.
ServeFlow: A Fast-Slow Model Architecture for Network Traffic Analysis
Feb 06, 2024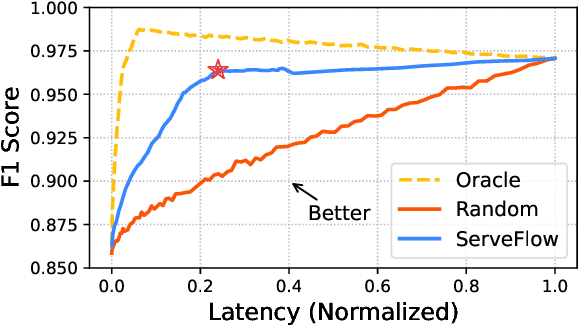
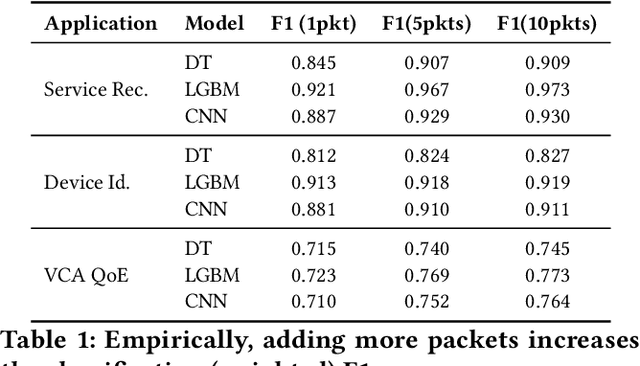
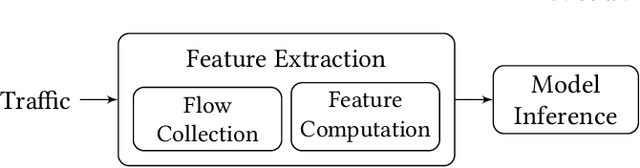
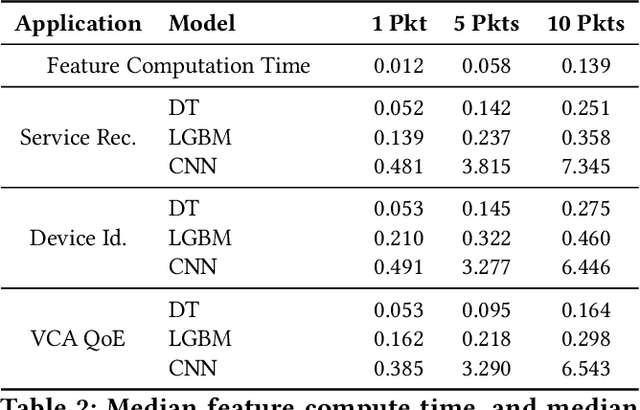
Network traffic analysis increasingly uses complex machine learning models as the internet consolidates and traffic gets more encrypted. However, over high-bandwidth networks, flows can easily arrive faster than model inference rates. The temporal nature of network flows limits simple scale-out approaches leveraged in other high-traffic machine learning applications. Accordingly, this paper presents ServeFlow, a solution for machine-learning model serving aimed at network traffic analysis tasks, which carefully selects the number of packets to collect and the models to apply for individual flows to achieve a balance between minimal latency, high service rate, and high accuracy. We identify that on the same task, inference time across models can differ by 2.7x-136.3x, while the median inter-packet waiting time is often 6-8 orders of magnitude higher than the inference time! ServeFlow is able to make inferences on 76.3% flows in under 16ms, which is a speed-up of 40.5x on the median end-to-end serving latency while increasing the service rate and maintaining similar accuracy. Even with thousands of features per flow, it achieves a service rate of over 48.5k new flows per second on a 16-core CPU commodity server, which matches the order of magnitude of flow rates observed on city-level network backbones.
Probing Visual-Audio Representation for Video Highlight Detection via Hard-Pairs Guided Contrastive Learning
Jun 21, 2022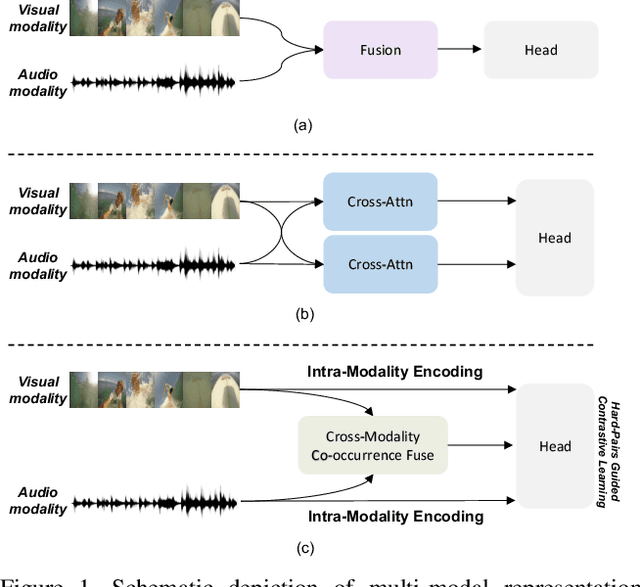

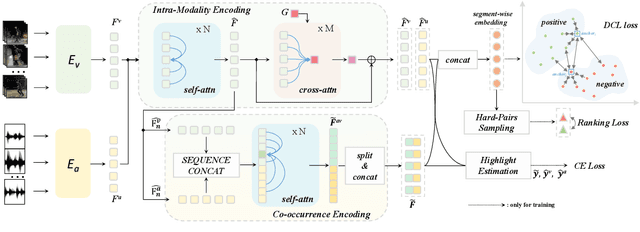
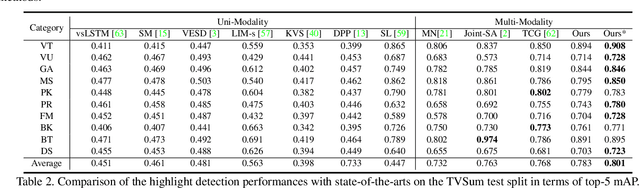
Video highlight detection is a crucial yet challenging problem that aims to identify the interesting moments in untrimmed videos. The key to this task lies in effective video representations that jointly pursue two goals, \textit{i.e.}, cross-modal representation learning and fine-grained feature discrimination. In this paper, these two challenges are tackled by not only enriching intra-modality and cross-modality relations for representation modeling but also shaping the features in a discriminative manner. Our proposed method mainly leverages the intra-modality encoding and cross-modality co-occurrence encoding for fully representation modeling. Specifically, intra-modality encoding augments the modality-wise features and dampens irrelevant modality via within-modality relation learning in both audio and visual signals. Meanwhile, cross-modality co-occurrence encoding focuses on the co-occurrence inter-modality relations and selectively captures effective information among multi-modality. The multi-modal representation is further enhanced by the global information abstracted from the local context. In addition, we enlarge the discriminative power of feature embedding with a hard-pairs guided contrastive learning (HPCL) scheme. A hard-pairs sampling strategy is further employed to mine the hard samples for improving feature discrimination in HPCL. Extensive experiments conducted on two benchmarks demonstrate the effectiveness and superiority of our proposed methods compared to other state-of-the-art methods.
Understanding Model Drift in a Large Cellular Network
Sep 07, 2021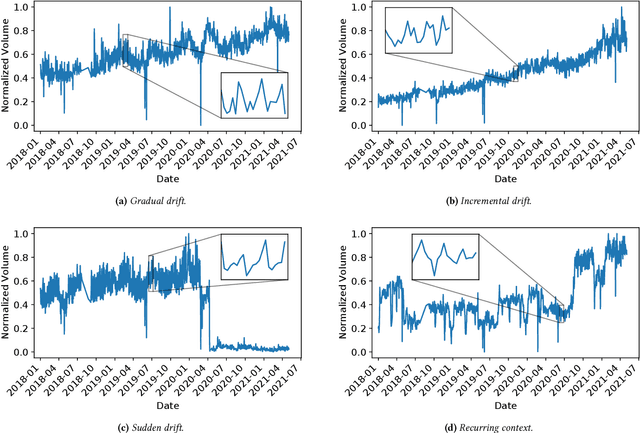


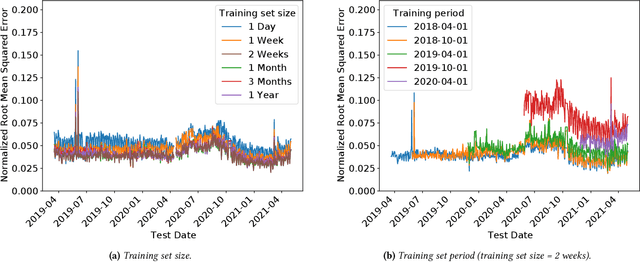
Operational networks are increasingly using machine learning models for a variety of tasks, including detecting anomalies, inferring application performance, and forecasting demand. Accurate models are important, yet accuracy can degrade over time due to concept drift, whereby either the characteristics of the data change over time (data drift) or the relationship between the features and the target predictor change over time (model drift). Drift is important to detect because changes in properties of the underlying data or relationships to the target prediction can require model retraining, which can be time-consuming and expensive. Concept drift occurs in operational networks for a variety of reasons, ranging from software upgrades to seasonality to changes in user behavior. Yet, despite the prevalence of drift in networks, its extent and effects on prediction accuracy have not been extensively studied. This paper presents an initial exploration into concept drift in a large cellular network in the United States for a major metropolitan area in the context of demand forecasting. We find that concept drift arises largely due to data drift, and it appears across different key performance indicators (KPIs), models, training set sizes, and time intervals. We identify the sources of concept drift for the particular problem of forecasting downlink volume. Weekly and seasonal patterns introduce both high and low-frequency model drift, while disasters and upgrades result in sudden drift due to exogenous shocks. Regions with high population density, lower traffic volumes, and higher speeds also tend to correlate with more concept drift. The features that contribute most significantly to concept drift are User Equipment (UE) downlink packets, UE uplink packets, and Real-time Transport Protocol (RTP) total received packets.
GroupFormer: Group Activity Recognition with Clustered Spatial-Temporal Transformer
Aug 28, 2021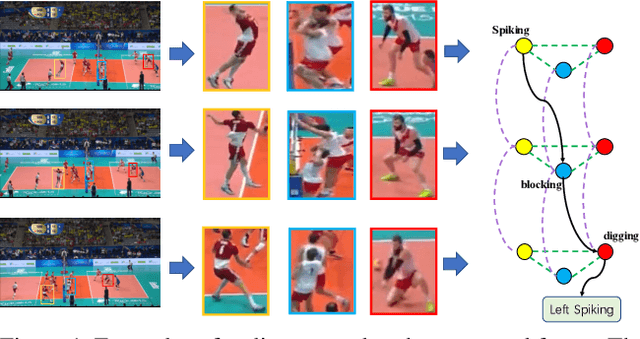
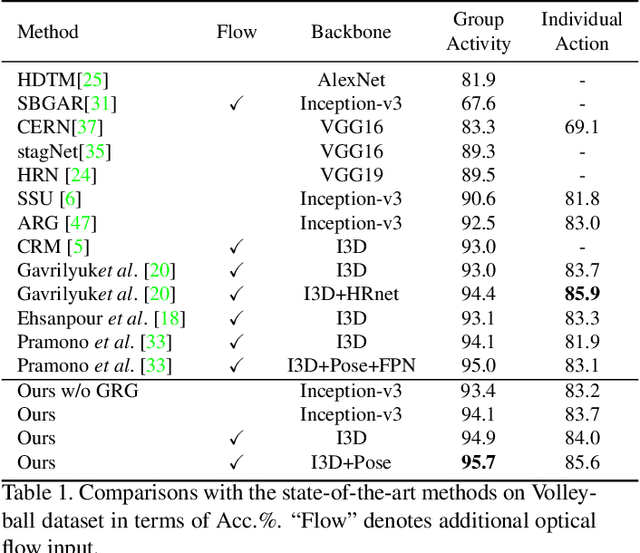
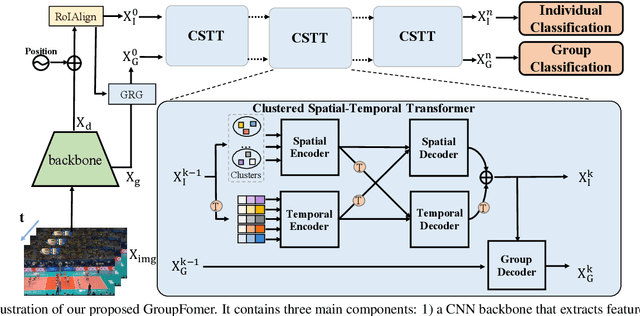
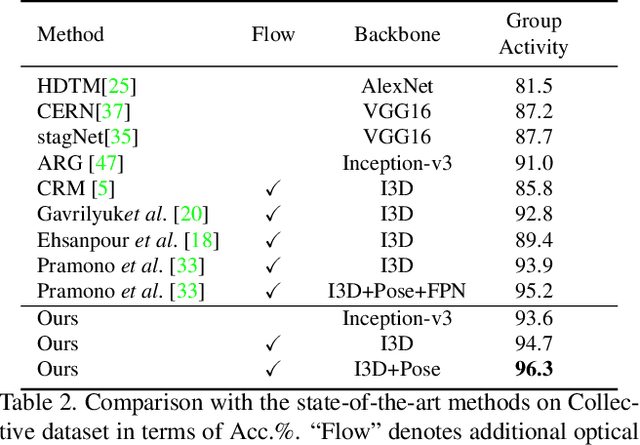
Group activity recognition is a crucial yet challenging problem, whose core lies in fully exploring spatial-temporal interactions among individuals and generating reasonable group representations. However, previous methods either model spatial and temporal information separately, or directly aggregate individual features to form group features. To address these issues, we propose a novel group activity recognition network termed GroupFormer. It captures spatial-temporal contextual information jointly to augment the individual and group representations effectively with a clustered spatial-temporal transformer. Specifically, our GroupFormer has three appealing advantages: (1) A tailor-modified Transformer, Clustered Spatial-Temporal Transformer, is proposed to enhance the individual representation and group representation. (2) It models the spatial and temporal dependencies integrally and utilizes decoders to build the bridge between the spatial and temporal information. (3) A clustered attention mechanism is utilized to dynamically divide individuals into multiple clusters for better learning activity-aware semantic representations. Moreover, experimental results show that the proposed framework outperforms state-of-the-art methods on the Volleyball dataset and Collective Activity dataset. Code is available at https://github.com/xueyee/GroupFormer.