 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Model Drift in a Large Cellular Network
Sep 07, 2021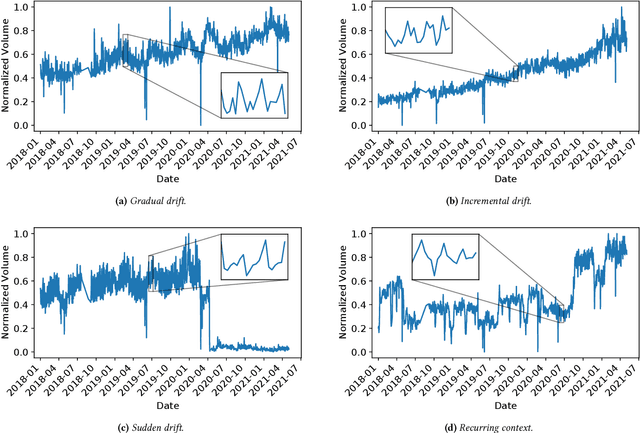


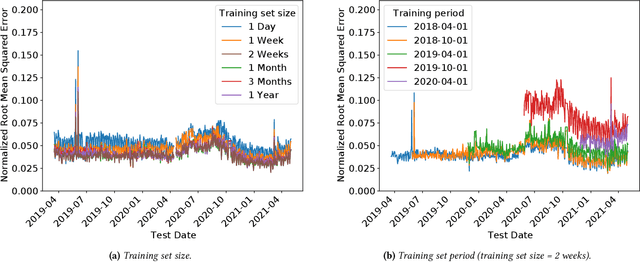
Operational networks are increasingly using machine learning models for a variety of tasks, including detecting anomalies, inferring application performance, and forecasting demand. Accurate models are important, yet accuracy can degrade over time due to concept drift, whereby either the characteristics of the data change over time (data drift) or the relationship between the features and the target predictor change over time (model drift). Drift is important to detect because changes in properties of the underlying data or relationships to the target prediction can require model retraining, which can be time-consuming and expensive. Concept drift occurs in operational networks for a variety of reasons, ranging from software upgrades to seasonality to changes in user behavior. Yet, despite the prevalence of drift in networks, its extent and effects on prediction accuracy have not been extensively studied. This paper presents an initial exploration into concept drift in a large cellular network in the United States for a major metropolitan area in the context of demand forecasting. We find that concept drift arises largely due to data drift, and it appears across different key performance indicators (KPIs), models, training set sizes, and time intervals. We identify the sources of concept drift for the particular problem of forecasting downlink volume. Weekly and seasonal patterns introduce both high and low-frequency model drift, while disasters and upgrades result in sudden drift due to exogenous shocks. Regions with high population density, lower traffic volumes, and higher speeds also tend to correlate with more concept drift. The features that contribute most significantly to concept drift are User Equipment (UE) downlink packets, UE uplink packets, and Real-time Transport Protocol (RTP) total received packets.