 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeServeFlow: A Fast-Slow Model Architecture for Network Traffic Analysis
Paper and Code
Feb 06, 2024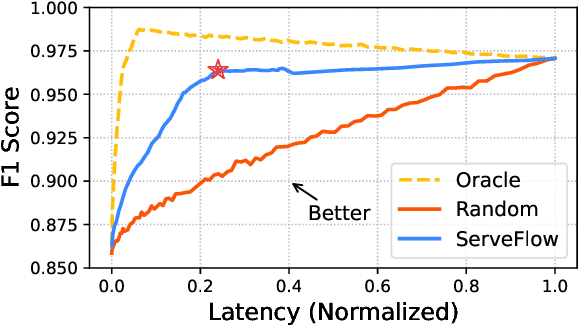
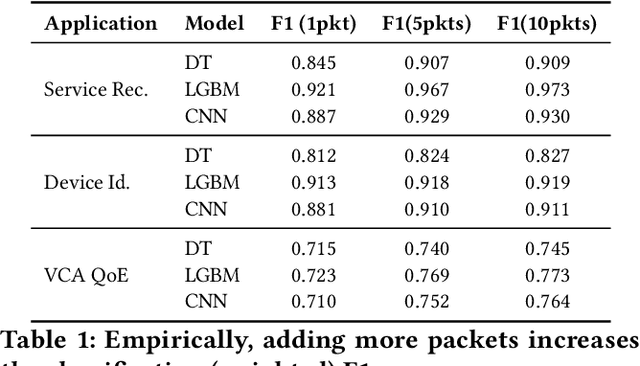
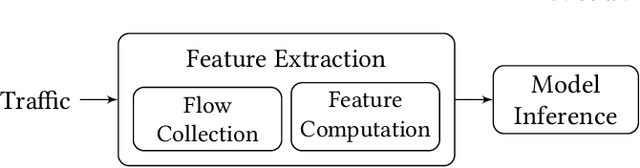
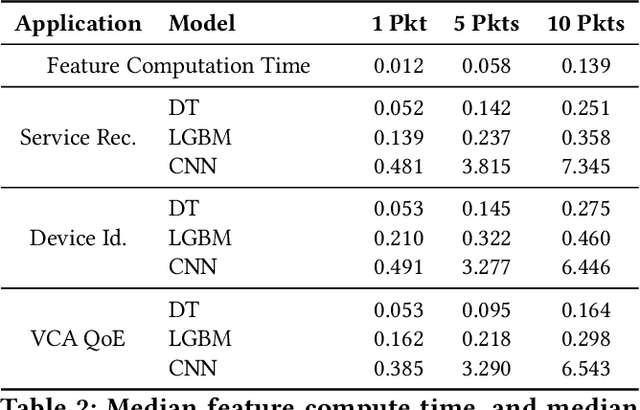
Network traffic analysis increasingly uses complex machine learning models as the internet consolidates and traffic gets more encrypted. However, over high-bandwidth networks, flows can easily arrive faster than model inference rates. The temporal nature of network flows limits simple scale-out approaches leveraged in other high-traffic machine learning applications. Accordingly, this paper presents ServeFlow, a solution for machine-learning model serving aimed at network traffic analysis tasks, which carefully selects the number of packets to collect and the models to apply for individual flows to achieve a balance between minimal latency, high service rate, and high accuracy. We identify that on the same task, inference time across models can differ by 2.7x-136.3x, while the median inter-packet waiting time is often 6-8 orders of magnitude higher than the inference time! ServeFlow is able to make inferences on 76.3% flows in under 16ms, which is a speed-up of 40.5x on the median end-to-end serving latency while increasing the service rate and maintaining similar accuracy. Even with thousands of features per flow, it achieves a service rate of over 48.5k new flows per second on a 16-core CPU commodity server, which matches the order of magnitude of flow rates observed on city-level network backbones.