 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithmic Data Minimization for Machine Learning over Internet-of-Things Data Streams
Mar 07, 2025
Machine learning can analyze vast amounts of data generated by IoT devices to identify patterns, make predictions, and enable real-time decision-making. By processing sensor data, machine learning models can optimize processes, improve efficiency, and enhance personalized user experiences in smart systems. However, IoT systems are often deployed in sensitive environments such as households and offices, where they may inadvertently expose identifiable information, including location, habits, and personal identifiers. This raises significant privacy concerns, necessitating the application of data minimization -- a foundational principle in emerging data regulations, which mandates that service providers only collect data that is directly relevant and necessary for a specified purpose. Despite its importance, data minimization lacks a precise technical definition in the context of sensor data, where collections of weak signals make it challenging to apply a binary "relevant and necessary" rule. This paper provides a technical interpretation of data minimization in the context of sensor streams, explores practical methods for implementation, and addresses the challenges involved. Through our approach, we demonstrate that our framework can reduce user identifiability by up to 16.7% while maintaining accuracy loss below 1%, offering a viable path toward privacy-preserving IoT data processing.
ServeFlow: A Fast-Slow Model Architecture for Network Traffic Analysis
Feb 06, 2024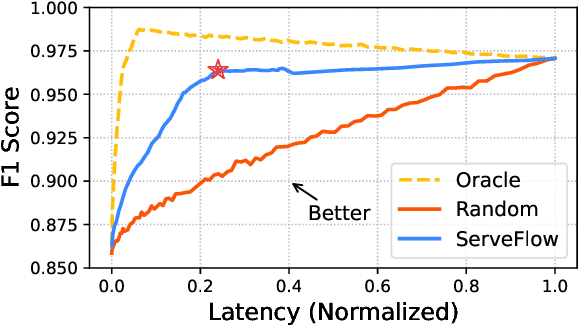
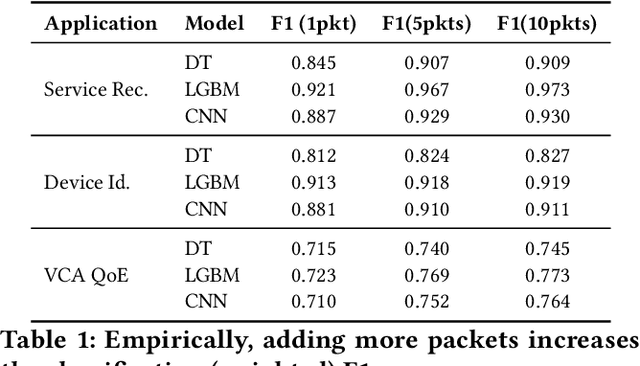
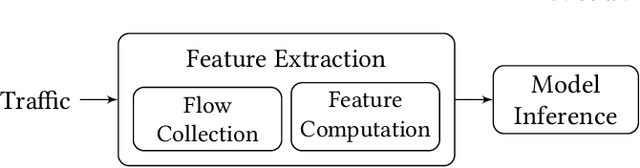
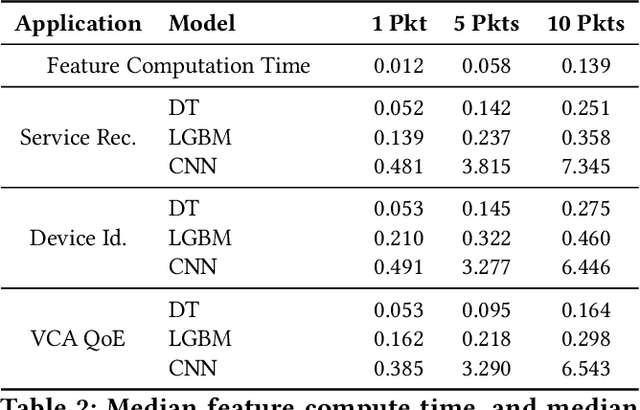
Network traffic analysis increasingly uses complex machine learning models as the internet consolidates and traffic gets more encrypted. However, over high-bandwidth networks, flows can easily arrive faster than model inference rates. The temporal nature of network flows limits simple scale-out approaches leveraged in other high-traffic machine learning applications. Accordingly, this paper presents ServeFlow, a solution for machine-learning model serving aimed at network traffic analysis tasks, which carefully selects the number of packets to collect and the models to apply for individual flows to achieve a balance between minimal latency, high service rate, and high accuracy. We identify that on the same task, inference time across models can differ by 2.7x-136.3x, while the median inter-packet waiting time is often 6-8 orders of magnitude higher than the inference time! ServeFlow is able to make inferences on 76.3% flows in under 16ms, which is a speed-up of 40.5x on the median end-to-end serving latency while increasing the service rate and maintaining similar accuracy. Even with thousands of features per flow, it achieves a service rate of over 48.5k new flows per second on a 16-core CPU commodity server, which matches the order of magnitude of flow rates observed on city-level network backbones.