 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvery Step Evolves: Scaling Reinforcement Learning for Trillion-Scale Thinking Model
Oct 21, 2025



We present Ring-1T, the first open-source, state-of-the-art thinking model with a trillion-scale parameter. It features 1 trillion total parameters and activates approximately 50 billion per token. Training such models at a trillion-parameter scale introduces unprecedented challenges, including train-inference misalignment, inefficiencies in rollout processing, and bottlenecks in the RL system. To address these, we pioneer three interconnected innovations: (1) IcePop stabilizes RL training via token-level discrepancy masking and clipping, resolving instability from training-inference mismatches; (2) C3PO++ improves resource utilization for long rollouts under a token budget by dynamically partitioning them, thereby obtaining high time efficiency; and (3) ASystem, a high-performance RL framework designed to overcome the systemic bottlenecks that impede trillion-parameter model training. Ring-1T delivers breakthrough results across critical benchmarks: 93.4 on AIME-2025, 86.72 on HMMT-2025, 2088 on CodeForces, and 55.94 on ARC-AGI-v1. Notably, it attains a silver medal-level result on the IMO-2025, underscoring its exceptional reasoning capabilities. By releasing the complete 1T parameter MoE model to the community, we provide the research community with direct access to cutting-edge reasoning capabilities. This contribution marks a significant milestone in democratizing large-scale reasoning intelligence and establishes a new baseline for open-source model performance.
RCNet: Reverse Feature Pyramid and Cross-scale Shift Network for Object Detection
Oct 23, 2021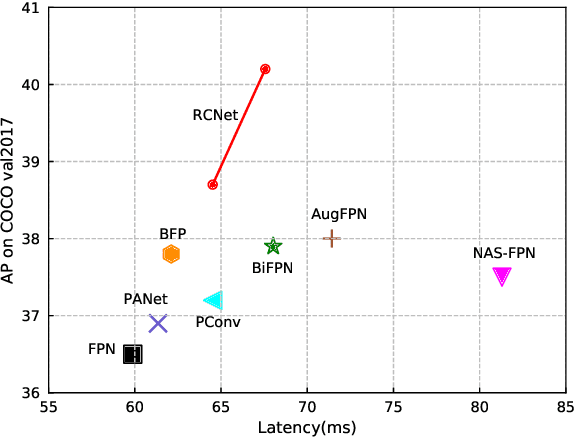
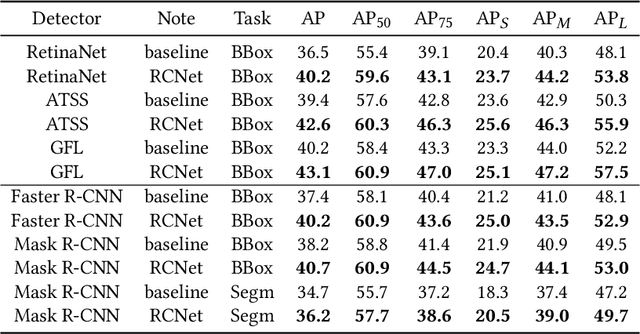
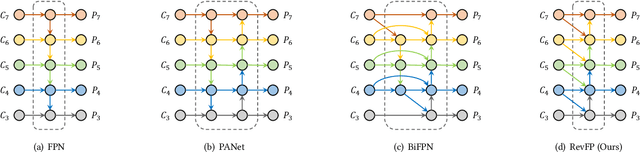
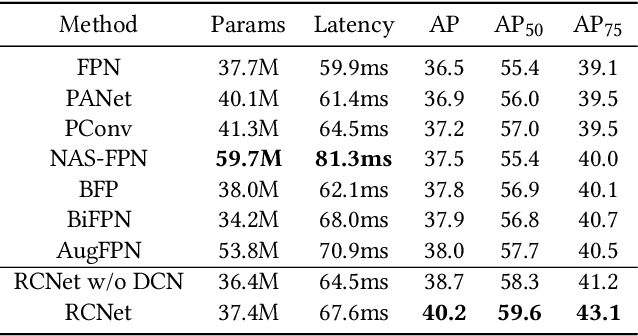
Feature pyramid networks (FPN) are widely exploited for multi-scale feature fusion in existing advanced object detection frameworks. Numerous previous works have developed various structures for bidirectional feature fusion, all of which are shown to improve the detection performance effectively. We observe that these complicated network structures require feature pyramids to be stacked in a fixed order, which introduces longer pipelines and reduces the inference speed. Moreover, semantics from non-adjacent levels are diluted in the feature pyramid since only features at adjacent pyramid levels are merged by the local fusion operation in a sequence manner. To address these issues, we propose a novel architecture named RCNet, which consists of Reverse Feature Pyramid (RevFP) and Cross-scale Shift Network (CSN). RevFP utilizes local bidirectional feature fusion to simplify the bidirectional pyramid inference pipeline. CSN directly propagates representations to both adjacent and non-adjacent levels to enable multi-scale features more correlative. Extensive experiments on the MS COCO dataset demonstrate RCNet can consistently bring significant improvements over both one-stage and two-stage detectors with subtle extra computational overhead. In particular, RetinaNet is boosted to 40.2 AP, which is 3.7 points higher than baseline, by replacing FPN with our proposed model. On COCO test-dev, RCNet can achieve very competitive performance with a single-model single-scale 50.5 AP. Codes will be made available.
GroupFormer: Group Activity Recognition with Clustered Spatial-Temporal Transformer
Aug 28, 2021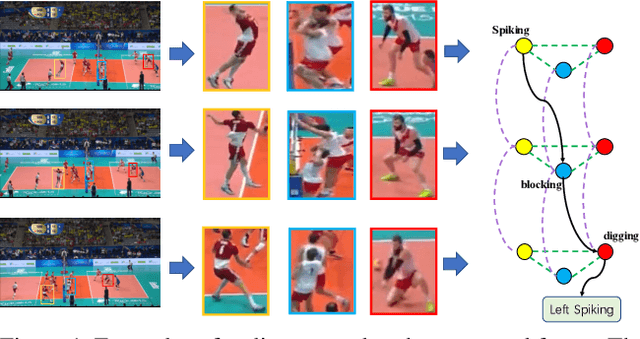
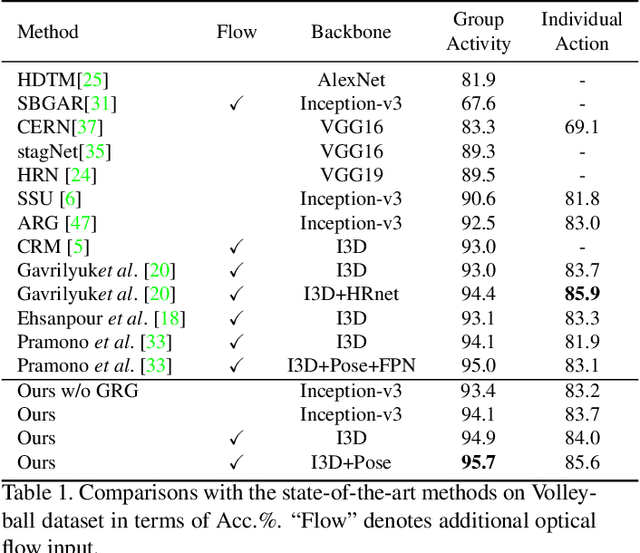
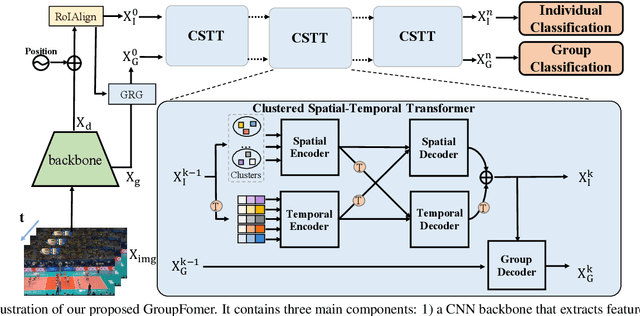
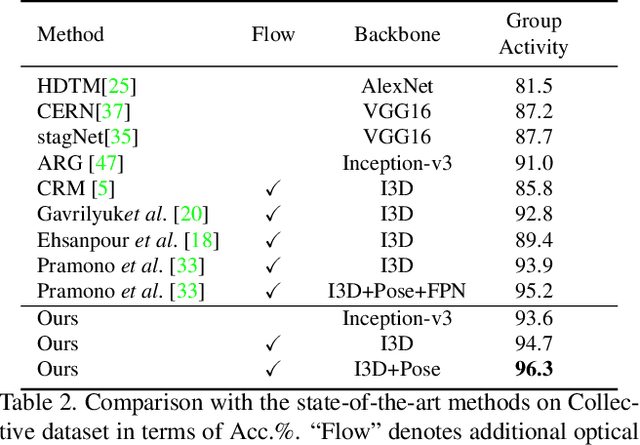
Group activity recognition is a crucial yet challenging problem, whose core lies in fully exploring spatial-temporal interactions among individuals and generating reasonable group representations. However, previous methods either model spatial and temporal information separately, or directly aggregate individual features to form group features. To address these issues, we propose a novel group activity recognition network termed GroupFormer. It captures spatial-temporal contextual information jointly to augment the individual and group representations effectively with a clustered spatial-temporal transformer. Specifically, our GroupFormer has three appealing advantages: (1) A tailor-modified Transformer, Clustered Spatial-Temporal Transformer, is proposed to enhance the individual representation and group representation. (2) It models the spatial and temporal dependencies integrally and utilizes decoders to build the bridge between the spatial and temporal information. (3) A clustered attention mechanism is utilized to dynamically divide individuals into multiple clusters for better learning activity-aware semantic representations. Moreover, experimental results show that the proposed framework outperforms state-of-the-art methods on the Volleyball dataset and Collective Activity dataset. Code is available at https://github.com/xueyee/GroupFormer.