 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Guided and Motion-Aware Gait Representation for Generalizable Recognition
Jan 17, 2026Gait recognition is emerging as a promising technology and an innovative field within computer vision. However, existing methods typically rely on complex architectures to directly extract features from images and apply pooling operations to obtain sequence-level representations. Such designs often lead to overfitting on static noise (e.g., clothing), while failing to effectively capture dynamic motion regions.To address the above challenges, we present a Language guided and Motion-aware gait recognition framework, named LMGait.In particular, we utilize designed gait-related language cues to capture key motion features in gait sequences.
Holistic Capability Preservation: Towards Compact Yet Comprehensive Reasoning Models
Apr 09, 2025This technical report presents Ring-Lite-Distill, a lightweight reasoning model derived from our open-source Mixture-of-Experts (MoE) Large Language Models (LLMs) Ling-Lite. This study demonstrates that through meticulous high-quality data curation and ingenious training paradigms, the compact MoE model Ling-Lite can be further trained to achieve exceptional reasoning capabilities, while maintaining its parameter-efficient architecture with only 2.75 billion activated parameters, establishing an efficient lightweight reasoning architecture. In particular, in constructing this model, we have not merely focused on enhancing advanced reasoning capabilities, exemplified by high-difficulty mathematical problem solving, but rather aimed to develop a reasoning model with more comprehensive competency coverage. Our approach ensures coverage across reasoning tasks of varying difficulty levels while preserving generic capabilities, such as instruction following, tool use, and knowledge retention. We show that, Ring-Lite-Distill's reasoning ability reaches a level comparable to DeepSeek-R1-Distill-Qwen-7B, while its general capabilities significantly surpass those of DeepSeek-R1-Distill-Qwen-7B. The models are accessible at https://huggingface.co/inclusionAI
DAGait: Generalized Skeleton-Guided Data Alignment for Gait Recognition
Mar 24, 2025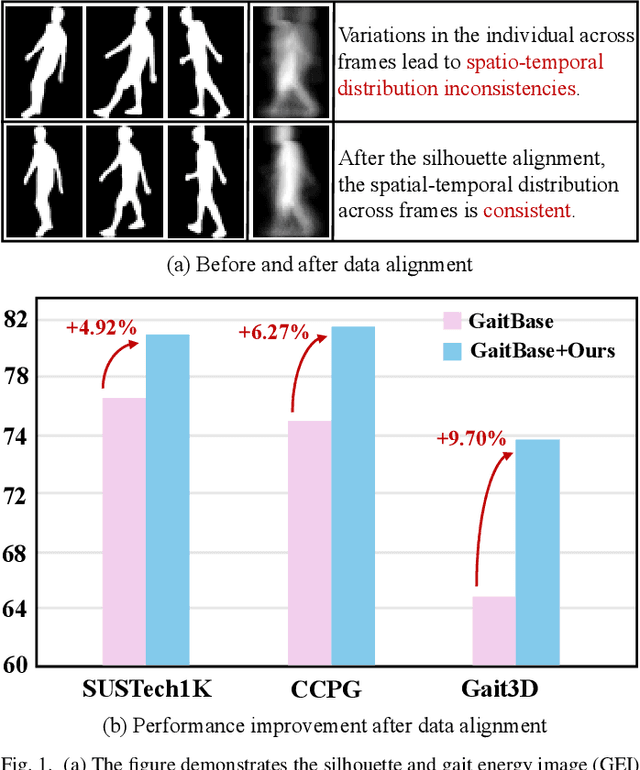
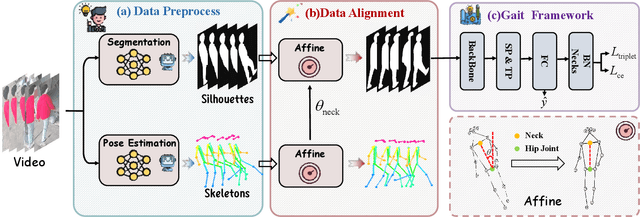
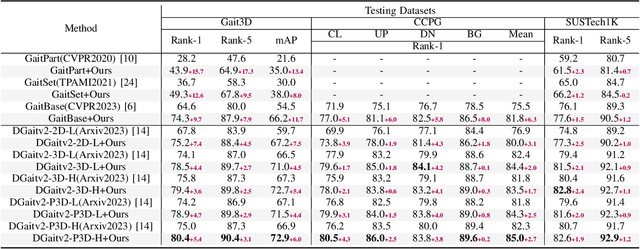
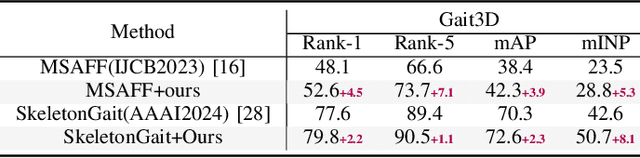
Gait recognition is emerging as a promising and innovative area within the field of computer vision, widely applied to remote person identification. Although existing gait recognition methods have achieved substantial success in controlled laboratory datasets, their performance often declines significantly when transitioning to wild datasets.We argue that the performance gap can be primarily attributed to the spatio-temporal distribution inconsistencies present in wild datasets, where subjects appear at varying angles, positions, and distances across the frames. To achieve accurate gait recognition in the wild, we propose a skeleton-guided silhouette alignment strategy, which uses prior knowledge of the skeletons to perform affine transformations on the corresponding silhouettes.To the best of our knowledge, this is the first study to explore the impact of data alignment on gait recognition. We conducted extensive experiments across multiple datasets and network architectures, and the results demonstrate the significant advantages of our proposed alignment strategy.Specifically, on the challenging Gait3D dataset, our method achieved an average performance improvement of 7.9% across all evaluated networks. Furthermore, our method achieves substantial improvements on cross-domain datasets, with accuracy improvements of up to 24.0%.
PSGait: Multimodal Gait Recognition using Parsing Skeleton
Mar 15, 2025Gait recognition has emerged as a robust biometric modality due to its non-intrusive nature and resilience to occlusion. Conventional gait recognition methods typically rely on silhouettes or skeletons. Despite their success in gait recognition for controlled laboratory environments, they usually fail in real-world scenarios due to their limited information entropy for gait representations. To achieve accurate gait recognition in the wild, we propose a novel gait representation, named Parsing Skeleton. This representation innovatively introduces the skeleton-guided human parsing method to capture fine-grained body dynamics, so they have much higher information entropy to encode the shapes and dynamics of fine-grained human parts during walking. Moreover, to effectively explore the capability of the parsing skeleton representation, we propose a novel parsing skeleton-based gait recognition framework, named PSGait, which takes parsing skeletons and silhouettes as input. By fusing these two modalities, the resulting image sequences are fed into gait recognition models for enhanced individual differentiation. We conduct comprehensive benchmarks on various datasets to evaluate our model. PSGait outperforms existing state-of-the-art multimodal methods. Furthermore, as a plug-and-play method, PSGait leads to a maximum improvement of 10.9% in Rank-1 accuracy across various gait recognition models. These results demonstrate the effectiveness and versatility of parsing skeletons for gait recognition in the wild, establishing PSGait as a new state-of-the-art approach for multimodal gait recognition.
MFSR: Multi-fractal Feature for Super-resolution Reconstruction with Fine Details Recovery
Feb 27, 2025



In the process of performing image super-resolution processing, the processing of complex localized information can have a significant impact on the quality of the image generated. Fractal features can capture the rich details of both micro and macro texture structures in an image. Therefore, we propose a diffusion model-based super-resolution method incorporating fractal features of low-resolution images, named MFSR. MFSR leverages these fractal features as reinforcement conditions in the denoising process of the diffusion model to ensure accurate recovery of texture information. MFSR employs convolution as a soft assignment to approximate the fractal features of low-resolution images. This approach is also used to approximate the density feature maps of these images. By using soft assignment, the spatial layout of the image is described hierarchically, encoding the self-similarity properties of the image at different scales. Different processing methods are applied to various types of features to enrich the information acquired by the model. In addition, a sub-denoiser is integrated in the denoising U-Net to reduce the noise in the feature maps during the up-sampling process in order to improve the quality of the generated images. Experiments conducted on various face and natural image datasets demonstrate that MFSR can generate higher quality images.
Transfer Learning in General Lensless Imaging through Scattering Media
Dec 28, 2019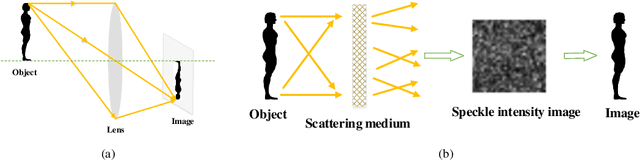
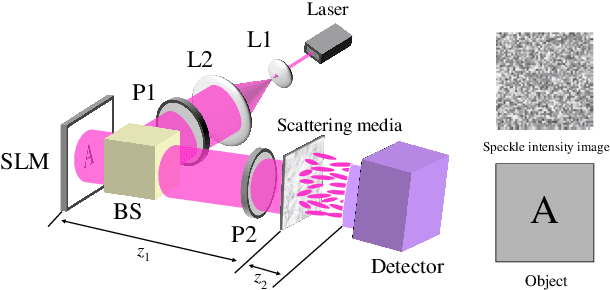
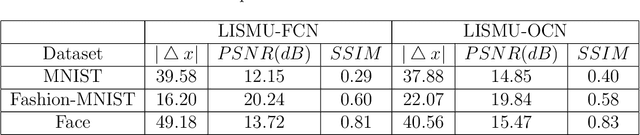

Recently deep neural networks (DNNs) have been successfully introduced to the field of lensless imaging through scattering media. By solving an inverse problem in computational imaging, DNNs can overcome several shortcomings in the conventional lensless imaging through scattering media methods, namely, high cost, poor quality, complex control, and poor anti-interference. However, for training, a large number of training samples on various datasets have to be collected, with a DNN trained on one dataset generally performing poorly for recovering images from another dataset. The underlying reason is that lensless imaging through scattering media is a high dimensional regression problem and it is difficult to obtain an analytical solution. In this work, transfer learning is proposed to address this issue. Our main idea is to train a DNN on a relatively complex dataset using a large number of training samples and fine-tune the last few layers using very few samples from other datasets. Instead of the thousands of samples required to train from scratch, transfer learning alleviates the problem of costly data acquisition. Specifically, considering the difference in sample sizes and similarity among datasets, we propose two DNN architectures, namely LISMU-FCN and LISMU-OCN, and a balance loss function designed for balancing smoothness and sharpness. LISMU-FCN, with much fewer parameters, can achieve imaging across similar datasets while LISMU-OCN can achieve imaging across significantly different datasets. What's more, we establish a set of simulation algorithms which are close to the real experiment, and it is of great significance and practical value in the research on lensless scattering imaging. In summary, this work provides a new solution for lensless imaging through scattering media using transfer learning in DNNs.
GXNOR-Net: Training deep neural networks with ternary weights and activations without full-precision memory under a unified discretization framework
May 02, 2018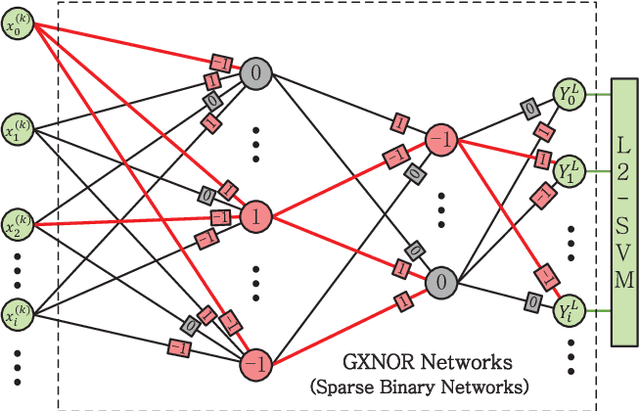
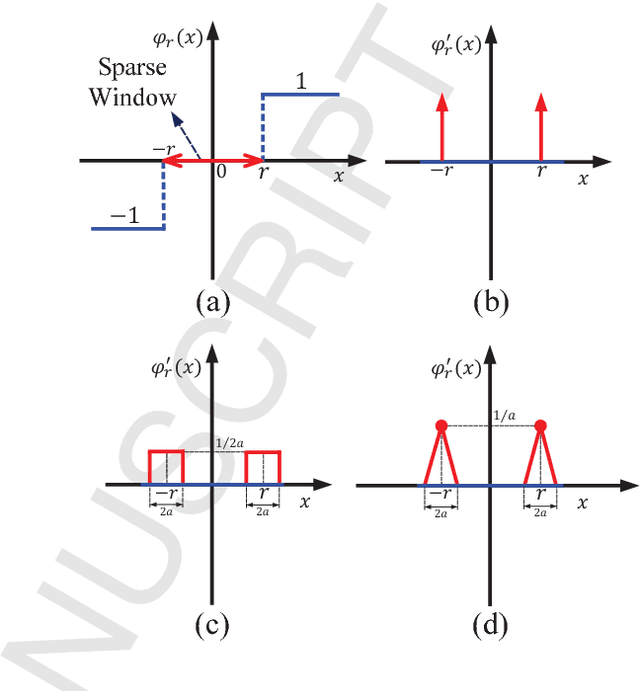
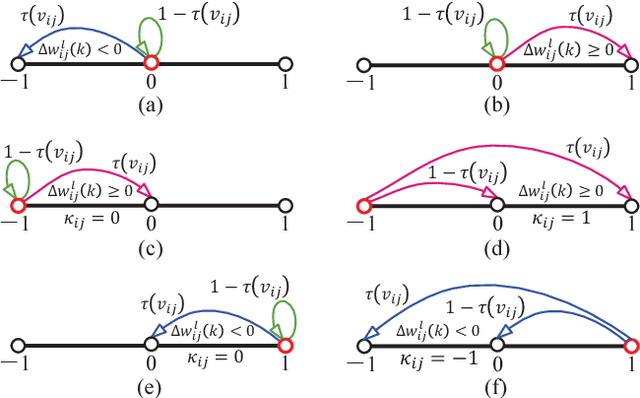
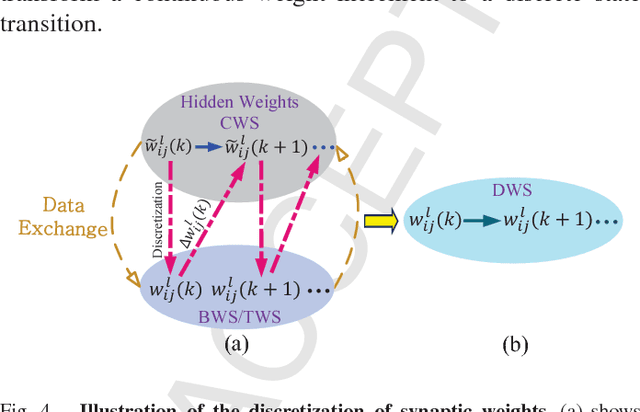
There is a pressing need to build an architecture that could subsume these networks under a unified framework that achieves both higher performance and less overhead. To this end, two fundamental issues are yet to be addressed. The first one is how to implement the back propagation when neuronal activations are discrete. The second one is how to remove the full-precision hidden weights in the training phase to break the bottlenecks of memory/computation consumption. To address the first issue, we present a multi-step neuronal activation discretization method and a derivative approximation technique that enable the implementing the back propagation algorithm on discrete DNNs. While for the second issue, we propose a discrete state transition (DST) methodology to constrain the weights in a discrete space without saving the hidden weights. Through this way, we build a unified framework that subsumes the binary or ternary networks as its special cases, and under which a heuristic algorithm is provided at the website https://github.com/AcrossV/Gated-XNOR. More particularly, we find that when both the weights and activations become ternary values, the DNNs can be reduced to sparse binary networks, termed as gated XNOR networks (GXNOR-Nets) since only the event of non-zero weight and non-zero activation enables the control gate to start the XNOR logic operations in the original binary networks. This promises the event-driven hardware design for efficient mobile intelligence. We achieve advanced performance compared with state-of-the-art algorithms. Furthermore, the computational sparsity and the number of states in the discrete space can be flexibly modified to make it suitable for various hardware platforms.
* 11 pages, 13 figures