 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Fundamentally Scalable Model Selection: Asymptotically Fast Update and Selection
Paper and Code
Jun 11, 2024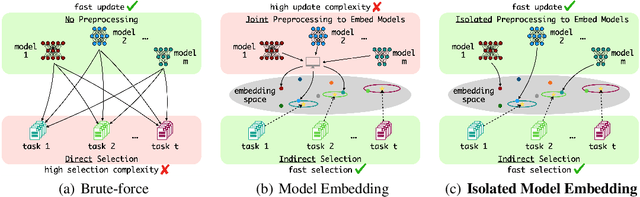

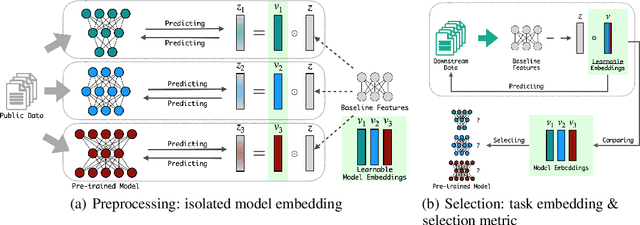
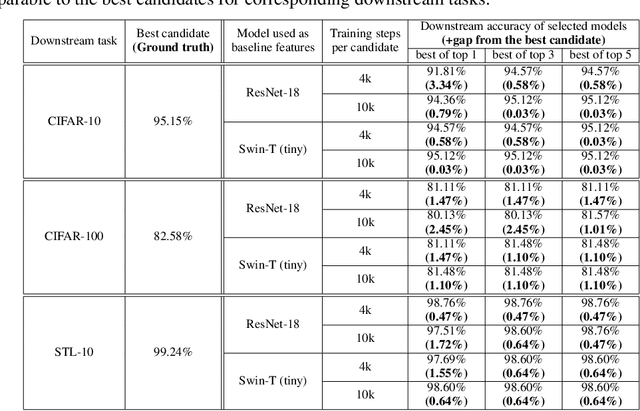
The advancement of deep learning technologies is bringing new models every day, motivating the study of scalable model selection. An ideal model selection scheme should minimally support two operations efficiently over a large pool of candidate models: update, which involves either adding a new candidate model or removing an existing candidate model, and selection, which involves locating highly performing models for a given task. However, previous solutions to model selection require high computational complexity for at least one of these two operations. In this work, we target fundamentally (more) scalable model selection that supports asymptotically fast update and asymptotically fast selection at the same time. Firstly, we define isolated model embedding, a family of model selection schemes supporting asymptotically fast update and selection: With respect to the number of candidate models $m$, the update complexity is O(1) and the selection consists of a single sweep over $m$ vectors in addition to O(1) model operations. Isolated model embedding also implies several desirable properties for applications. Secondly, we present Standardized Embedder, an empirical realization of isolated model embedding. We assess its effectiveness by using it to select representations from a pool of 100 pre-trained vision models for classification tasks and measuring the performance gaps between the selected models and the best candidates with a linear probing protocol. Experiments suggest our realization is effective in selecting models with competitive performances and highlight isolated model embedding as a promising direction towards model selection that is fundamentally (more) scalable.