 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Optimization for Federated Person Re-identification via Benchmark Analysis
Paper and Code

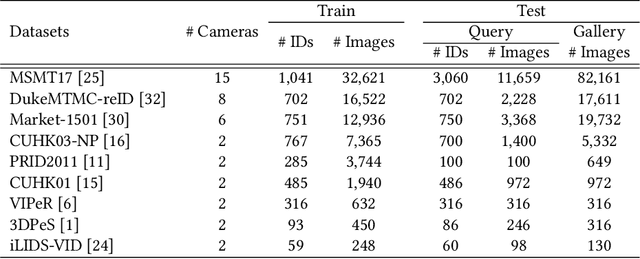
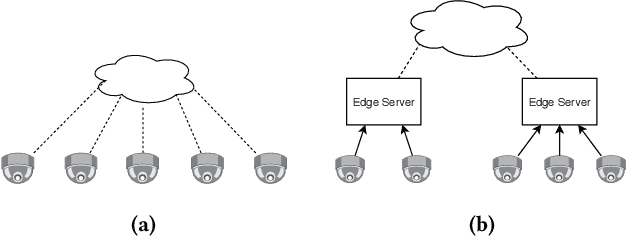
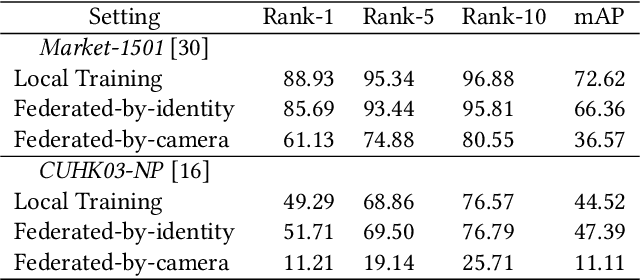
Federated learning is a privacy-preserving machine learning technique that learns a shared model across decentralized clients. It can alleviate privacy concerns of personal re-identification, an important computer vision task. In this work, we implement federated learning to person re-identification (FedReID) and optimize its performance affected by statistical heterogeneity in the real-world scenario. We first construct a new benchmark to investigate the performance of FedReID. This benchmark consists of (1) nine datasets with different volumes sourced from different domains to simulate the heterogeneous situation in reality, (2) two federated scenarios, and (3) an enhanced federated algorithm for FedReID. The benchmark analysis shows that the client-edge-cloud architecture, represented by the federated-by-dataset scenario, has better performance than client-server architecture in FedReID. It also reveals the bottlenecks of FedReID under the real-world scenario, including poor performance of large datasets caused by unbalanced weights in model aggregation and challenges in convergence. Then we propose two optimization methods: (1) To address the unbalanced weight problem, we propose a new method to dynamically change the weights according to the scale of model changes in clients in each training round; (2) To facilitate convergence, we adopt knowledge distillation to refine the server model with knowledge generated from client models on a public dataset. Experiment results demonstrate that our strategies can achieve much better convergence with superior performance on all datasets. We believe that our work will inspire the community to further explore the implementation of federated learning on more computer vision tasks in real-world scenarios.