 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Pseudo-Labeling for Image-based 3D Object Detection
Paper and Code
Aug 15, 2022


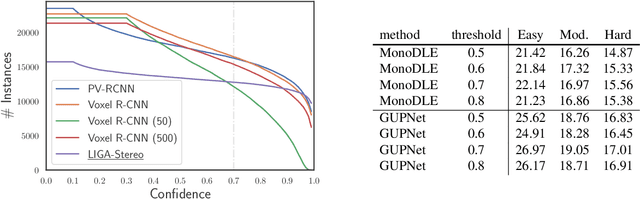
Image-based 3D detection is an indispensable component of the perception system for autonomous driving. However, it still suffers from the unsatisfying performance, one of the main reasons for which is the limited training data. Unfortunately, annotating the objects in the 3D space is extremely time/resource-consuming, which makes it hard to extend the training set arbitrarily. In this work, we focus on the semi-supervised manner and explore the feasibility of a cheaper alternative, i.e. pseudo-labeling, to leverage the unlabeled data. For this purpose, we conduct extensive experiments to investigate whether the pseudo-labels can provide effective supervision for the baseline models under varying settings. The experimental results not only demonstrate the effectiveness of the pseudo-labeling mechanism for image-based 3D detection (e.g. under monocular setting, we achieve 20.23 AP for moderate level on the KITTI-3D testing set without bells and whistles, improving the baseline model by 6.03 AP), but also show several interesting and noteworthy findings (e.g. the models trained with pseudo-labels perform better than that trained with ground-truth annotations based on the same training data). We hope this work can provide insights for the image-based 3D detection community under a semi-supervised setting. The codes, pseudo-labels, and pre-trained models will be publicly available.