 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Video Object Segmentation using the Global Context Module
Paper and Code
Jan 30, 2020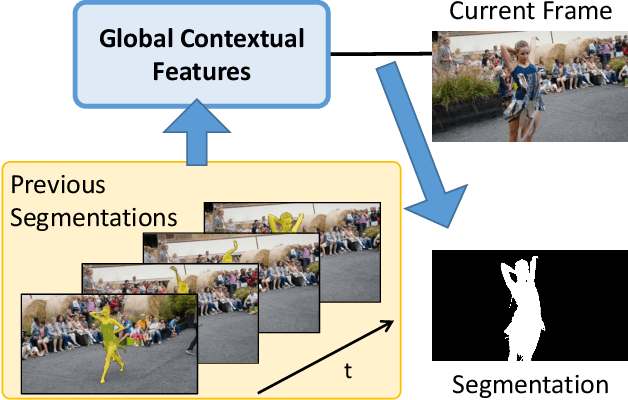
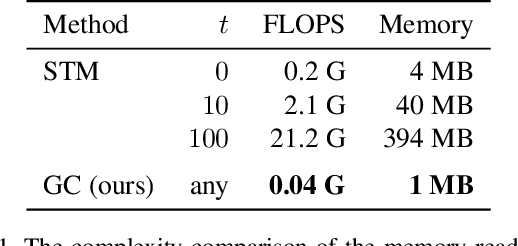
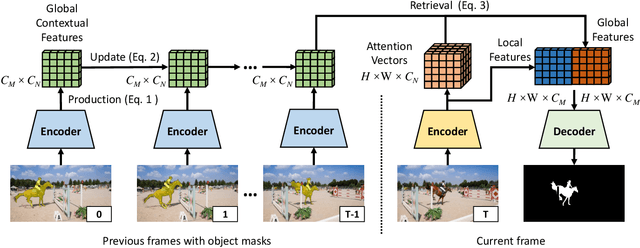

We developed a real-time, high-quality video object segmentation algorithm for semi-supervised video segmentation. Its performance is on par with the most accurate, time-consuming online-learning model, while its speed is similar to the fastest template-matching method which has sub-optimal accuracy. The core in achieving this is a novel global context module that reliably summarizes and propagates information through the entire video. Compared to previous approaches that only use the first, the last, or a select few frames to guide the segmentation of the current frame, the global context module allows us to use all past frames to guide the processing. Unlike the state-of-the-art space-time memory network that caches a memory at each spatiotemporal position, our global context module is a fixed-size representation that does not use more memory as more frames are processed. It is straightforward in implementation and has lower memory and computational costs than the space-time memory module. Equipped with the global context module, our method achieved top accuracy on DAVIS 2016 and near-state-of-the-art results on DAVIS 2017 at a real-time speed.