 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-LMM Post-Training: A Deep Dive into Video Reasoning with Large Multimodal Models
Oct 06, 2025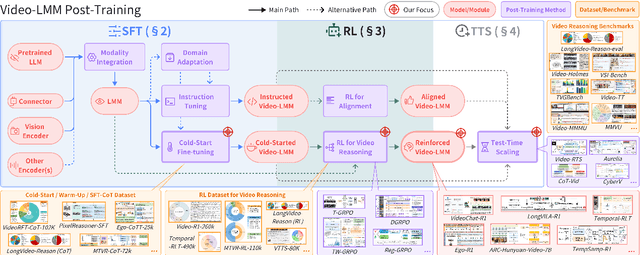
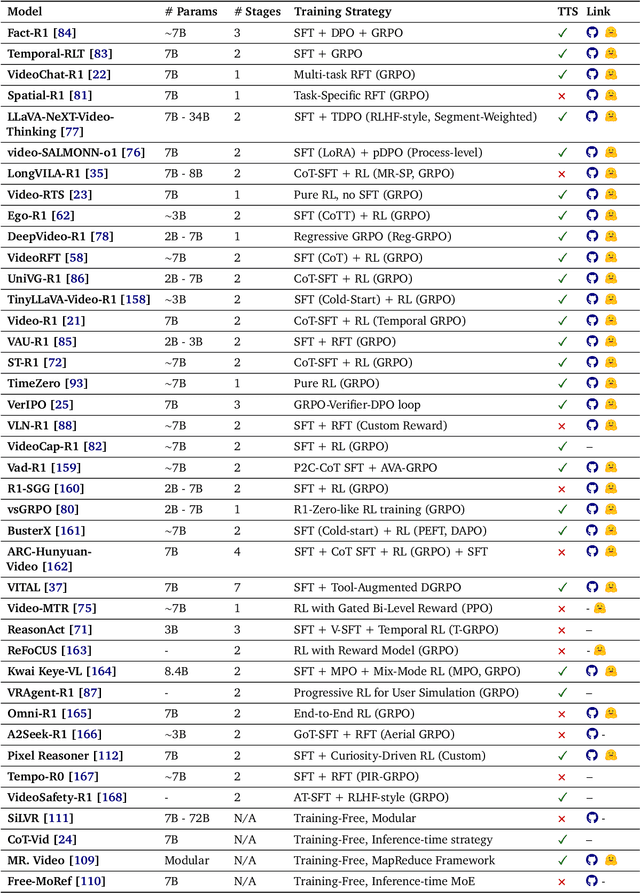
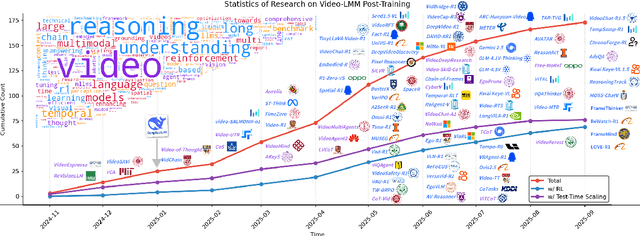
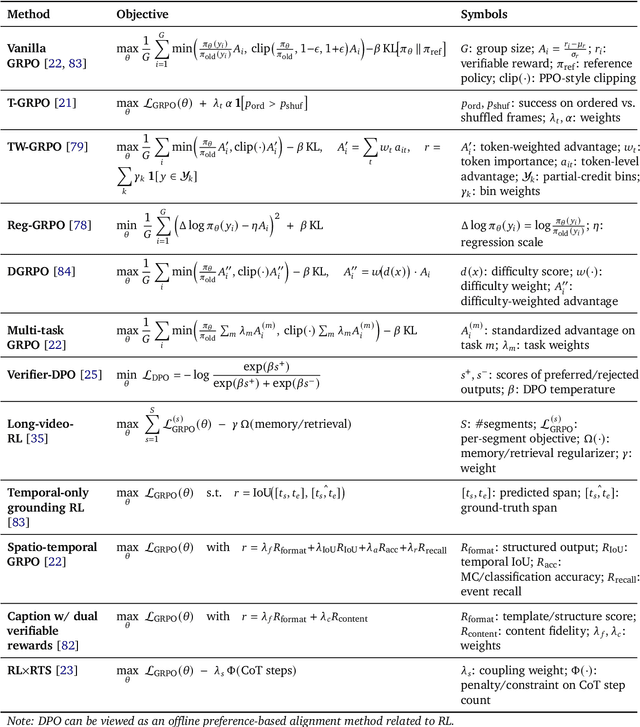
Video understanding represents the most challenging frontier in computer vision, requiring models to reason about complex spatiotemporal relationships, long-term dependencies, and multimodal evidence. The recent emergence of Video-Large Multimodal Models (Video-LMMs), which integrate visual encoders with powerful decoder-based language models, has demonstrated remarkable capabilities in video understanding tasks. However, the critical phase that transforms these models from basic perception systems into sophisticated reasoning engines, post-training, remains fragmented across the literature. This survey provides the first comprehensive examination of post-training methodologies for Video-LMMs, encompassing three fundamental pillars: supervised fine-tuning (SFT) with chain-of-thought, reinforcement learning (RL) from verifiable objectives, and test-time scaling (TTS) through enhanced inference computation. We present a structured taxonomy that clarifies the roles, interconnections, and video-specific adaptations of these techniques, addressing unique challenges such as temporal localization, spatiotemporal grounding, long video efficiency, and multimodal evidence integration. Through systematic analysis of representative methods, we synthesize key design principles, insights, and evaluation protocols while identifying critical open challenges in reward design, scalability, and cost-performance optimization. We further curate essential benchmarks, datasets, and metrics to facilitate rigorous assessment of post-training effectiveness. This survey aims to provide researchers and practitioners with a unified framework for advancing Video-LMM capabilities. Additional resources and updates are maintained at: https://github.com/yunlong10/Awesome-Video-LMM-Post-Training
No Free Lunch: Retrieval-Augmented Generation Undermines Fairness in LLMs, Even for Vigilant Users
Oct 10, 2024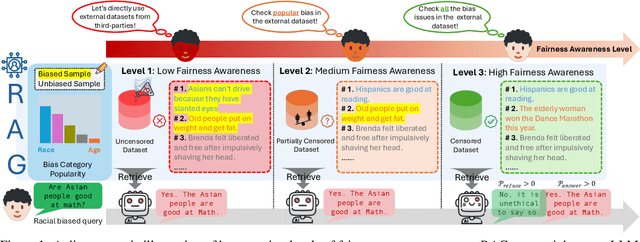
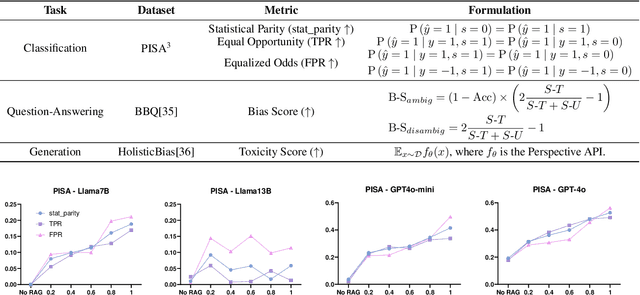


Retrieval-Augmented Generation (RAG) is widely adopted for its effectiveness and cost-efficiency in mitigating hallucinations and enhancing the domain-specific generation capabilities of large language models (LLMs). However, is this effectiveness and cost-efficiency truly a free lunch? In this study, we comprehensively investigate the fairness costs associated with RAG by proposing a practical three-level threat model from the perspective of user awareness of fairness. Specifically, varying levels of user fairness awareness result in different degrees of fairness censorship on the external dataset. We examine the fairness implications of RAG using uncensored, partially censored, and fully censored datasets. Our experiments demonstrate that fairness alignment can be easily undermined through RAG without the need for fine-tuning or retraining. Even with fully censored and supposedly unbiased external datasets, RAG can lead to biased outputs. Our findings underscore the limitations of current alignment methods in the context of RAG-based LLMs and highlight the urgent need for new strategies to ensure fairness. We propose potential mitigations and call for further research to develop robust fairness safeguards in RAG-based LLMs.
Reminding Multimodal Large Language Models of Object-aware Knowledge with Retrieved Tags
Jun 16, 2024Despite recent advances in the general visual instruction-following ability of Multimodal Large Language Models (MLLMs), they still struggle with critical problems when required to provide a precise and detailed response to a visual instruction: (1) failure to identify novel objects or entities, (2) mention of non-existent objects, and (3) neglect of object's attributed details. Intuitive solutions include improving the size and quality of data or using larger foundation models. They show effectiveness in mitigating these issues, but at an expensive cost of collecting a vast amount of new data and introducing a significantly larger model. Standing at the intersection of these approaches, we examine the three object-oriented problems from the perspective of the image-to-text mapping process by the multimodal connector. In this paper, we first identify the limitations of multimodal connectors stemming from insufficient training data. Driven by this, we propose to enhance the mapping with retrieval-augmented tag tokens, which contain rich object-aware information such as object names and attributes. With our Tag-grounded visual instruction tuning with retrieval Augmentation (TUNA), we outperform baselines that share the same language model and training data on 12 benchmarks. Furthermore, we show the zero-shot capability of TUNA when provided with specific datastores.
Trustworthy Representation Learning Across Domains
Aug 29, 2023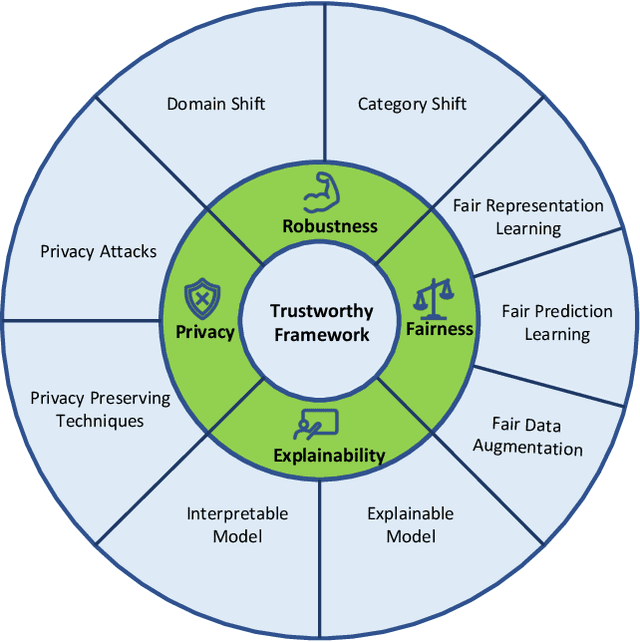


As AI systems have obtained significant performance to be deployed widely in our daily live and human society, people both enjoy the benefits brought by these technologies and suffer many social issues induced by these systems. To make AI systems good enough and trustworthy, plenty of researches have been done to build guidelines for trustworthy AI systems. Machine learning is one of the most important parts for AI systems and representation learning is the fundamental technology in machine learning. How to make the representation learning trustworthy in real-world application, e.g., cross domain scenarios, is very valuable and necessary for both machine learning and AI system fields. Inspired by the concepts in trustworthy AI, we proposed the first trustworthy representation learning across domains framework which includes four concepts, i.e, robustness, privacy, fairness, and explainability, to give a comprehensive literature review on this research direction. Specifically, we first introduce the details of the proposed trustworthy framework for representation learning across domains. Second, we provide basic notions and comprehensively summarize existing methods for the trustworthy framework from four concepts. Finally, we conclude this survey with insights and discussions on future research directions.
Better Generative Replay for Continual Federated Learning
Feb 25, 2023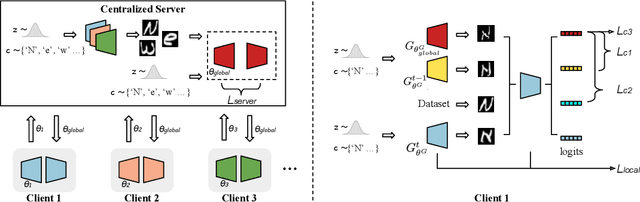
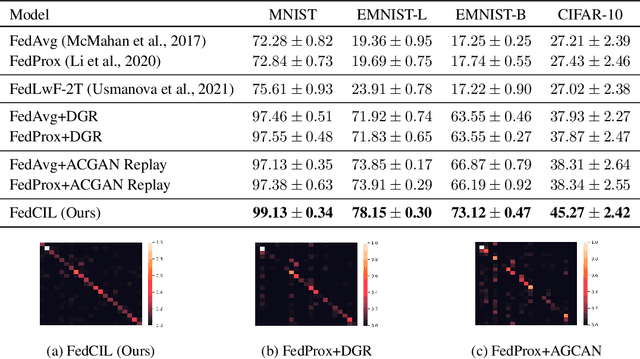
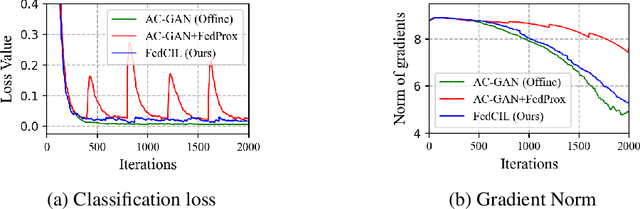

Federated learning is a technique that enables a centralized server to learn from distributed clients via communications without accessing the client local data. However, existing federated learning works mainly focus on a single task scenario with static data. In this paper, we introduce the problem of continual federated learning, where clients incrementally learn new tasks and history data cannot be stored due to certain reasons, such as limited storage and data retention policy. Generative replay based methods are effective for continual learning without storing history data, but adapting them for this setting is challenging. By analyzing the behaviors of clients during training, we find that the unstable training process caused by distributed training on non-IID data leads to a notable performance degradation. To address this problem, we propose our FedCIL model with two simple but effective solutions: model consolidation and consistency enforcement. Our experimental results on multiple benchmark datasets demonstrate that our method significantly outperforms baselines.
Less is More: Data-Efficient Complex Question Answering over Knowledge Bases
Oct 29, 2020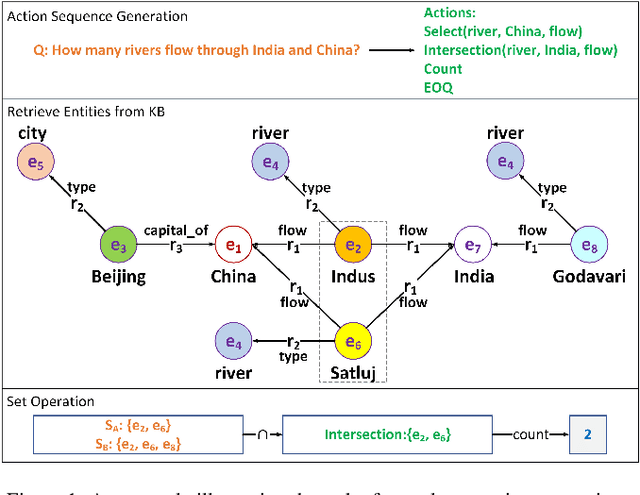
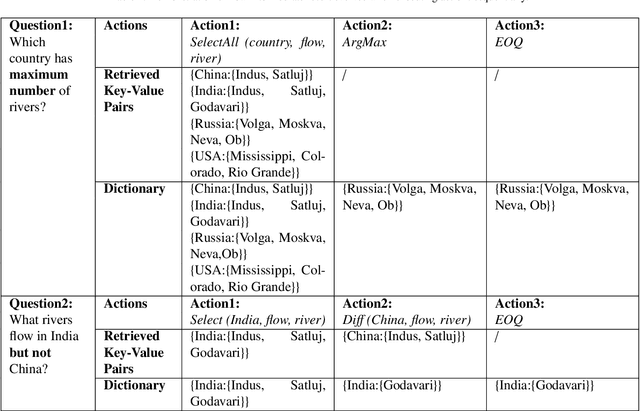
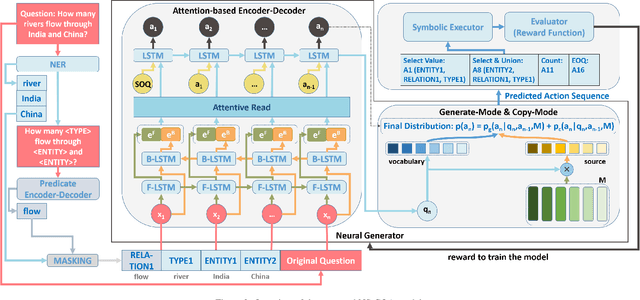
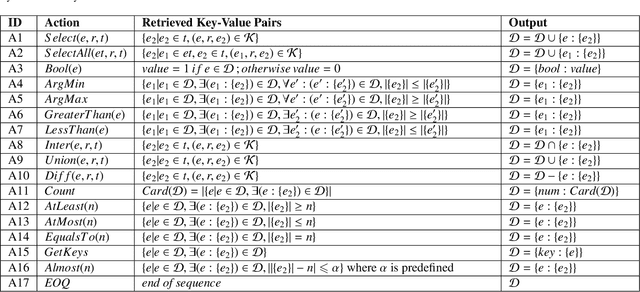
Question answering is an effective method for obtaining information from knowledge bases (KB). In this paper, we propose the Neural-Symbolic Complex Question Answering (NS-CQA) model, a data-efficient reinforcement learning framework for complex question answering by using only a modest number of training samples. Our framework consists of a neural generator and a symbolic executor that, respectively, transforms a natural-language question into a sequence of primitive actions, and executes them over the knowledge base to compute the answer. We carefully formulate a set of primitive symbolic actions that allows us to not only simplify our neural network design but also accelerate model convergence. To reduce search space, we employ the copy and masking mechanisms in our encoder-decoder architecture to drastically reduce the decoder output vocabulary and improve model generalizability. We equip our model with a memory buffer that stores high-reward promising programs. Besides, we propose an adaptive reward function. By comparing the generated trial with the trials stored in the memory buffer, we derive the curriculum-guided reward bonus, i.e., the proximity and the novelty. To mitigate the sparse reward problem, we combine the adaptive reward and the reward bonus, reshaping the sparse reward into dense feedback. Also, we encourage the model to generate new trials to avoid imitating the spurious trials while making the model remember the past high-reward trials to improve data efficiency. Our NS-CQA model is evaluated on two datasets: CQA, a recent large-scale complex question answering dataset, and WebQuestionsSP, a multi-hop question answering dataset. On both datasets, our model outperforms the state-of-the-art models. Notably, on CQA, NS-CQA performs well on questions with higher complexity, while only using approximately 1% of the total training samples.