 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Free Lunch: Retrieval-Augmented Generation Undermines Fairness in LLMs, Even for Vigilant Users
Paper and Code
Oct 10, 2024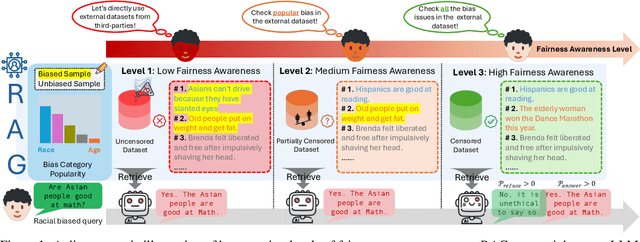
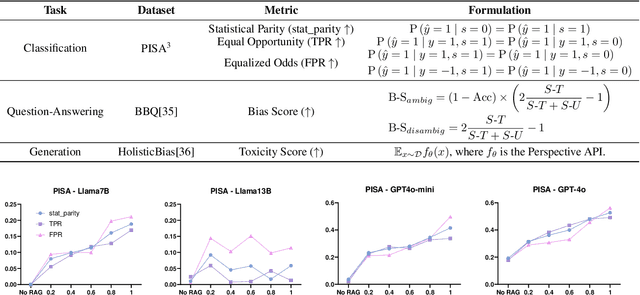


Retrieval-Augmented Generation (RAG) is widely adopted for its effectiveness and cost-efficiency in mitigating hallucinations and enhancing the domain-specific generation capabilities of large language models (LLMs). However, is this effectiveness and cost-efficiency truly a free lunch? In this study, we comprehensively investigate the fairness costs associated with RAG by proposing a practical three-level threat model from the perspective of user awareness of fairness. Specifically, varying levels of user fairness awareness result in different degrees of fairness censorship on the external dataset. We examine the fairness implications of RAG using uncensored, partially censored, and fully censored datasets. Our experiments demonstrate that fairness alignment can be easily undermined through RAG without the need for fine-tuning or retraining. Even with fully censored and supposedly unbiased external datasets, RAG can lead to biased outputs. Our findings underscore the limitations of current alignment methods in the context of RAG-based LLMs and highlight the urgent need for new strategies to ensure fairness. We propose potential mitigations and call for further research to develop robust fairness safeguards in RAG-based LLMs.