 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgenncase: An End-to-End Compiler for Efficient LLM Deployment on Heterogeneous Storage Architectures
Dec 25, 2025The efficient deployment of large language models (LLMs) is hindered by memory architecture heterogeneity, where traditional compilers suffer from fragmented workflows and high adaptation costs. We present nncase, an open-source, end-to-end compilation framework designed to unify optimization across diverse targets. Central to nncase is an e-graph-based term rewriting engine that mitigates the phase ordering problem, enabling global exploration of computation and data movement strategies. The framework integrates three key modules: Auto Vectorize for adapting to heterogeneous computing units, Auto Distribution for searching parallel strategies with cost-aware communication optimization, and Auto Schedule for maximizing on-chip cache locality. Furthermore, a buffer-aware Codegen phase ensures efficient kernel instantiation. Evaluations show that nncase outperforms mainstream frameworks like MLC LLM and Intel IPEX on Qwen3 series models and achieves performance comparable to the hand-optimized llama.cpp on CPUs, demonstrating the viability of automated compilation for high-performance LLM deployment. The source code is available at https://github.com/kendryte/nncase.
BalancEdit: Dynamically Balancing the Generality-Locality Trade-off in Multi-modal Model Editing
May 02, 2025Large multi-modal models inevitably decay over time as facts change and previously learned information becomes outdated. Traditional approaches such as fine-tuning are often impractical for updating these models due to their size and complexity. Instead, direct knowledge editing within the models presents a more viable solution. Current model editing techniques, however, typically overlook the unique influence ranges of different facts, leading to compromised model performance in terms of both generality and locality. To address this issue, we introduce the concept of the generality-locality trade-off in multi-modal model editing. We develop a new model editing dataset named OKEDIT, specifically designed to effectively evaluate this trade-off. Building on this foundation, we propose BalancEdit, a novel method for balanced model editing that dynamically achieves an optimal balance between generality and locality. BalancEdit utilizes a unique mechanism that generates both positive and negative samples for each fact to accurately determine its influence scope and incorporates these insights into the model's latent space using a discrete, localized codebook of edits, without modifying the underlying model weights. To our knowledge, this is the first approach explicitly addressing the generality-locality trade-off in multi-modal model editing. Our comprehensive results confirm the effectiveness of BalancEdit, demonstrating minimal trade-offs while maintaining robust editing capabilities. Our code and dataset will be available.
Ensemble of Large Language Models for Curated Labeling and Rating of Free-text Data
Jan 14, 2025



Free-text responses are commonly collected in psychological studies, providing rich qualitative insights that quantitative measures may not capture. Labeling curated topics of research interest in free-text data by multiple trained human coders is typically labor-intensive and time-consuming. Though large language models (LLMs) excel in language processing, LLM-assisted labeling techniques relying on closed-source LLMs cannot be directly applied to free-text data, without explicit consent for external use. In this study, we propose a framework of assembling locally-deployable LLMs to enhance the labeling of predetermined topics in free-text data under privacy constraints. Analogous to annotation by multiple human raters, this framework leverages the heterogeneity of diverse open-source LLMs. The ensemble approach seeks a balance between the agreement and disagreement across LLMs, guided by a relevancy scoring methodology that utilizes embedding distances between topic descriptions and LLMs' reasoning. We evaluated the ensemble approach using both publicly accessible Reddit data from eating disorder related forums, and free-text responses from eating disorder patients, both complemented by human annotations. We found that: (1) there is heterogeneity in the performance of labeling among same-sized LLMs, with some showing low sensitivity but high precision, while others exhibit high sensitivity but low precision. (2) Compared to individual LLMs, the ensemble of LLMs achieved the highest accuracy and optimal precision-sensitivity trade-off in predicting human annotations. (3) The relevancy scores across LLMs showed greater agreement than dichotomous labels, indicating that the relevancy scoring method effectively mitigates the heterogeneity in LLMs' labeling.
Backdoor in Seconds: Unlocking Vulnerabilities in Large Pre-trained Models via Model Editing
Oct 23, 2024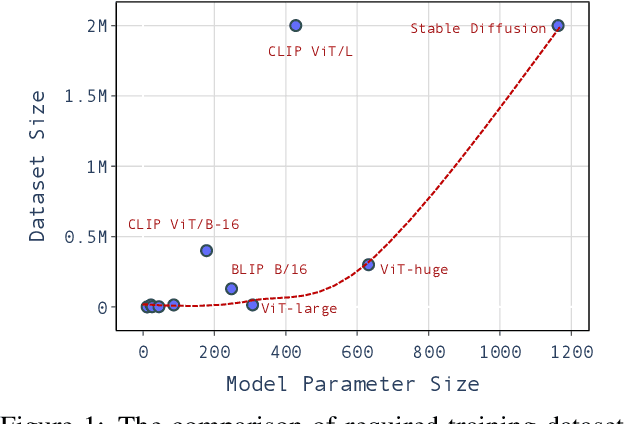
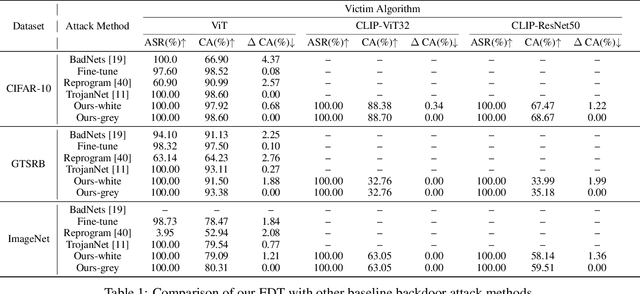
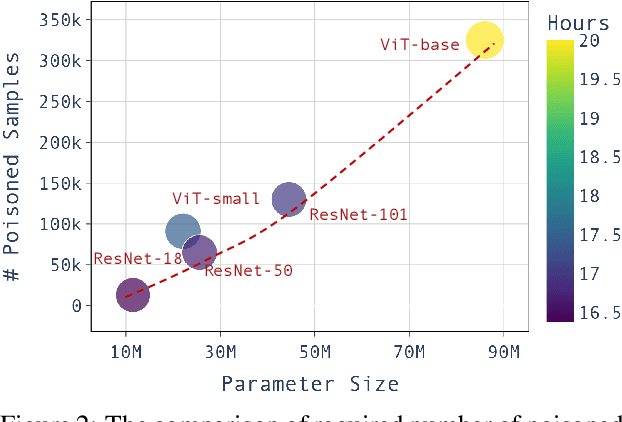

Large pre-trained models have achieved notable success across a range of downstream tasks. However, recent research shows that a type of adversarial attack ($\textit{i.e.,}$ backdoor attack) can manipulate the behavior of machine learning models through contaminating their training dataset, posing significant threat in the real-world application of large pre-trained model, especially for those customized models. Therefore, addressing the unique challenges for exploring vulnerability of pre-trained models is of paramount importance. Through empirical studies on the capability for performing backdoor attack in large pre-trained models ($\textit{e.g.,}$ ViT), we find the following unique challenges of attacking large pre-trained models: 1) the inability to manipulate or even access large training datasets, and 2) the substantial computational resources required for training or fine-tuning these models. To address these challenges, we establish new standards for an effective and feasible backdoor attack in the context of large pre-trained models. In line with these standards, we introduce our EDT model, an \textbf{E}fficient, \textbf{D}ata-free, \textbf{T}raining-free backdoor attack method. Inspired by model editing techniques, EDT injects an editing-based lightweight codebook into the backdoor of large pre-trained models, which replaces the embedding of the poisoned image with the target image without poisoning the training dataset or training the victim model. Our experiments, conducted across various pre-trained models such as ViT, CLIP, BLIP, and stable diffusion, and on downstream tasks including image classification, image captioning, and image generation, demonstrate the effectiveness of our method. Our code is available in the supplementary material.
No Free Lunch: Retrieval-Augmented Generation Undermines Fairness in LLMs, Even for Vigilant Users
Oct 10, 2024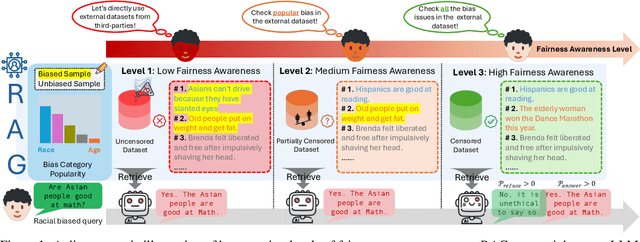
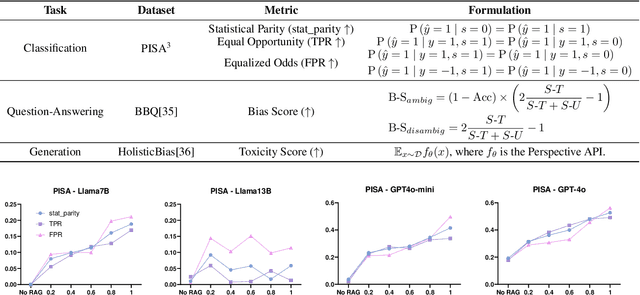


Retrieval-Augmented Generation (RAG) is widely adopted for its effectiveness and cost-efficiency in mitigating hallucinations and enhancing the domain-specific generation capabilities of large language models (LLMs). However, is this effectiveness and cost-efficiency truly a free lunch? In this study, we comprehensively investigate the fairness costs associated with RAG by proposing a practical three-level threat model from the perspective of user awareness of fairness. Specifically, varying levels of user fairness awareness result in different degrees of fairness censorship on the external dataset. We examine the fairness implications of RAG using uncensored, partially censored, and fully censored datasets. Our experiments demonstrate that fairness alignment can be easily undermined through RAG without the need for fine-tuning or retraining. Even with fully censored and supposedly unbiased external datasets, RAG can lead to biased outputs. Our findings underscore the limitations of current alignment methods in the context of RAG-based LLMs and highlight the urgent need for new strategies to ensure fairness. We propose potential mitigations and call for further research to develop robust fairness safeguards in RAG-based LLMs.
Bridging the Fairness Divide: Achieving Group and Individual Fairness in Graph Neural Networks
Apr 26, 2024



Graph neural networks (GNNs) have emerged as a powerful tool for analyzing and learning from complex data structured as graphs, demonstrating remarkable effectiveness in various applications, such as social network analysis, recommendation systems, and drug discovery. However, despite their impressive performance, the fairness problem has increasingly gained attention as a crucial aspect to consider. Existing research in graph learning focuses on either group fairness or individual fairness. However, since each concept provides unique insights into fairness from distinct perspectives, integrating them into a fair graph neural network system is crucial. To the best of our knowledge, no study has yet to comprehensively tackle both individual and group fairness simultaneously. In this paper, we propose a new concept of individual fairness within groups and a novel framework named Fairness for Group and Individual (FairGI), which considers both group fairness and individual fairness within groups in the context of graph learning. FairGI employs the similarity matrix of individuals to achieve individual fairness within groups, while leveraging adversarial learning to address group fairness in terms of both Equal Opportunity and Statistical Parity. The experimental results demonstrate that our approach not only outperforms other state-of-the-art models in terms of group fairness and individual fairness within groups, but also exhibits excellent performance in population-level individual fairness, while maintaining comparable prediction accuracy.
XAI meets Biology: A Comprehensive Review of Explainable AI in Bioinformatics Applications
Dec 11, 2023

Artificial intelligence (AI), particularly machine learning and deep learning models, has significantly impacted bioinformatics research by offering powerful tools for analyzing complex biological data. However, the lack of interpretability and transparency of these models presents challenges in leveraging these models for deeper biological insights and for generating testable hypotheses. Explainable AI (XAI) has emerged as a promising solution to enhance the transparency and interpretability of AI models in bioinformatics. This review provides a comprehensive analysis of various XAI techniques and their applications across various bioinformatics domains including DNA, RNA, and protein sequence analysis, structural analysis, gene expression and genome analysis, and bioimaging analysis. We introduce the most pertinent machine learning and XAI methods, then discuss their diverse applications and address the current limitations of available XAI tools. By offering insights into XAI's potential and challenges, this review aims to facilitate its practical implementation in bioinformatics research and help researchers navigate the landscape of XAI tools.
Trustworthy Representation Learning Across Domains
Aug 29, 2023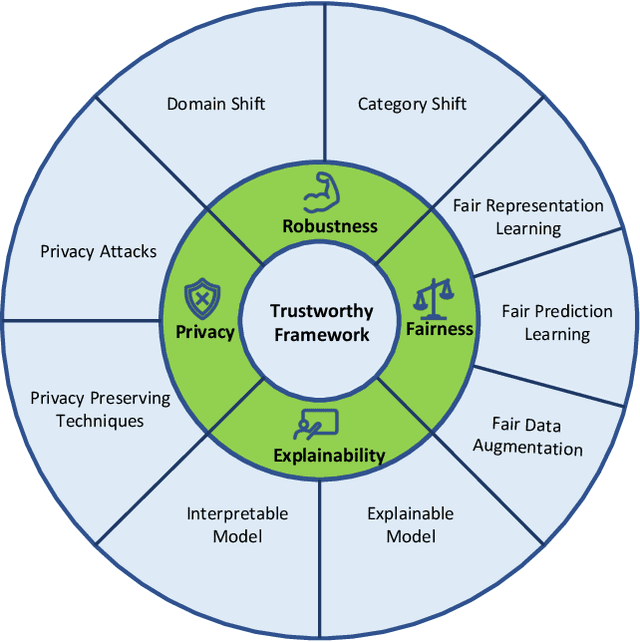


As AI systems have obtained significant performance to be deployed widely in our daily live and human society, people both enjoy the benefits brought by these technologies and suffer many social issues induced by these systems. To make AI systems good enough and trustworthy, plenty of researches have been done to build guidelines for trustworthy AI systems. Machine learning is one of the most important parts for AI systems and representation learning is the fundamental technology in machine learning. How to make the representation learning trustworthy in real-world application, e.g., cross domain scenarios, is very valuable and necessary for both machine learning and AI system fields. Inspired by the concepts in trustworthy AI, we proposed the first trustworthy representation learning across domains framework which includes four concepts, i.e, robustness, privacy, fairness, and explainability, to give a comprehensive literature review on this research direction. Specifically, we first introduce the details of the proposed trustworthy framework for representation learning across domains. Second, we provide basic notions and comprehensively summarize existing methods for the trustworthy framework from four concepts. Finally, we conclude this survey with insights and discussions on future research directions.
Fair Attribute Completion on Graph with Missing Attributes
Mar 02, 2023



Tackling unfairness in graph learning models is a challenging task, as the unfairness issues on graphs involve both attributes and topological structures. Existing work on fair graph learning simply assumes that attributes of all nodes are available for model training and then makes fair predictions. In practice, however, the attributes of some nodes might not be accessible due to missing data or privacy concerns, which makes fair graph learning even more challenging. In this paper, we propose FairAC, a fair attribute completion method, to complement missing information and learn fair node embeddings for graphs with missing attributes. FairAC adopts an attention mechanism to deal with the attribute missing problem and meanwhile, it mitigates two types of unfairness, i.e., feature unfairness from attributes and topological unfairness due to attribute completion. FairAC can work on various types of homogeneous graphs and generate fair embeddings for them and thus can be applied to most downstream tasks to improve their fairness performance. To our best knowledge, FairAC is the first method that jointly addresses the graph attribution completion and graph unfairness problems. Experimental results on benchmark datasets show that our method achieves better fairness performance with less sacrifice in accuracy, compared with the state-of-the-art methods of fair graph learning. Code is available at: https://github.com/donglgcn/FairAC.
Towards Explainable Visual Anomaly Detection
Feb 13, 2023



Anomaly detection and localization of visual data, including images and videos, are of great significance in both machine learning academia and applied real-world scenarios. Despite the rapid development of visual anomaly detection techniques in recent years, the interpretations of these black-box models and reasonable explanations of why anomalies can be distinguished out are scarce. This paper provides the first survey concentrated on explainable visual anomaly detection methods. We first introduce the basic background of image-level anomaly detection and video-level anomaly detection, followed by the current explainable approaches for visual anomaly detection. Then, as the main content of this survey, a comprehensive and exhaustive literature review of explainable anomaly detection methods for both images and videos is presented. Finally, we discuss several promising future directions and open problems to explore on the explainability of visual anomaly detection.