 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Fairness Divide: Achieving Group and Individual Fairness in Graph Neural Networks
Apr 26, 2024



Graph neural networks (GNNs) have emerged as a powerful tool for analyzing and learning from complex data structured as graphs, demonstrating remarkable effectiveness in various applications, such as social network analysis, recommendation systems, and drug discovery. However, despite their impressive performance, the fairness problem has increasingly gained attention as a crucial aspect to consider. Existing research in graph learning focuses on either group fairness or individual fairness. However, since each concept provides unique insights into fairness from distinct perspectives, integrating them into a fair graph neural network system is crucial. To the best of our knowledge, no study has yet to comprehensively tackle both individual and group fairness simultaneously. In this paper, we propose a new concept of individual fairness within groups and a novel framework named Fairness for Group and Individual (FairGI), which considers both group fairness and individual fairness within groups in the context of graph learning. FairGI employs the similarity matrix of individuals to achieve individual fairness within groups, while leveraging adversarial learning to address group fairness in terms of both Equal Opportunity and Statistical Parity. The experimental results demonstrate that our approach not only outperforms other state-of-the-art models in terms of group fairness and individual fairness within groups, but also exhibits excellent performance in population-level individual fairness, while maintaining comparable prediction accuracy.
Recent Advances in Text Analysis
Jan 01, 2024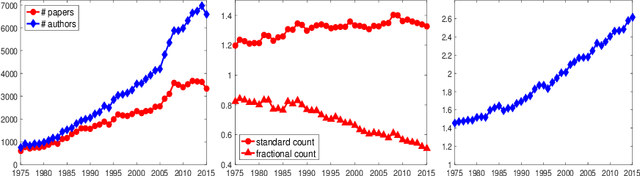
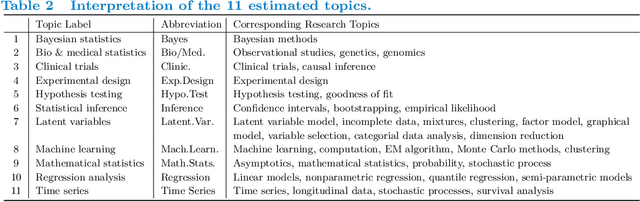
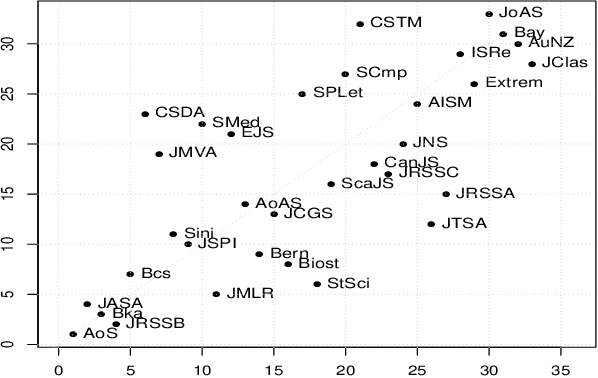
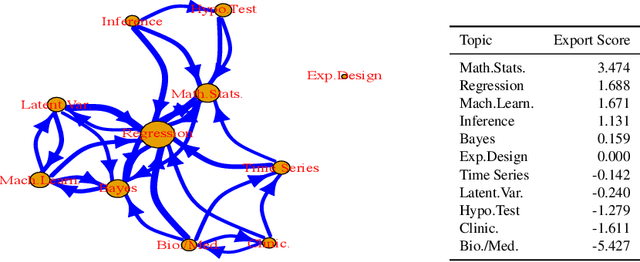
Text analysis is an interesting research area in data science and has various applications, such as in artificial intelligence, biomedical research, and engineering. We review popular methods for text analysis, ranging from topic modeling to the recent neural language models. In particular, we review Topic-SCORE, a statistical approach to topic modeling, and discuss how to use it to analyze MADStat - a dataset on statistical publications that we collected and cleaned. The application of Topic-SCORE and other methods on MADStat leads to interesting findings. For example, $11$ representative topics in statistics are identified. For each journal, the evolution of topic weights over time can be visualized, and these results are used to analyze the trends in statistical research. In particular, we propose a new statistical model for ranking the citation impacts of $11$ topics, and we also build a cross-topic citation graph to illustrate how research results on different topics spread to one another. The results on MADStat provide a data-driven picture of the statistical research in $1975$--$2015$, from a text analysis perspective.
Co-embedding of Nodes and Edges with Graph Neural Networks
Oct 25, 2020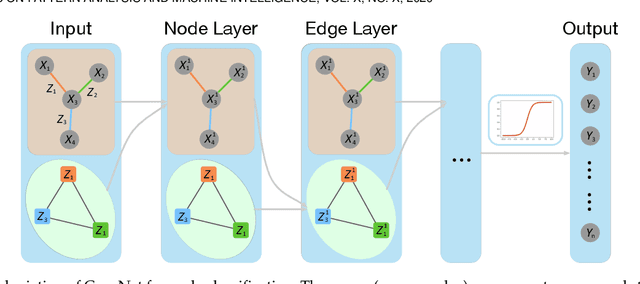
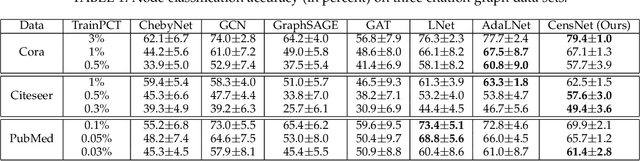
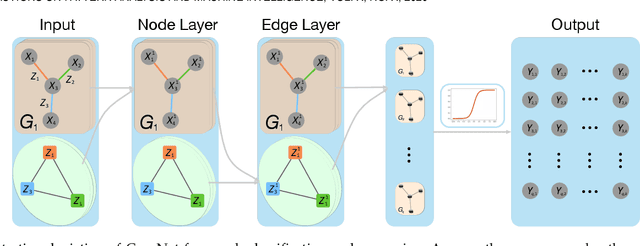
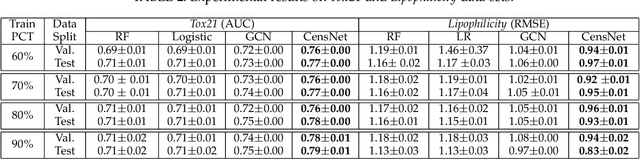
Graph, as an important data representation, is ubiquitous in many real world applications ranging from social network analysis to biology. How to correctly and effectively learn and extract information from graph is essential for a large number of machine learning tasks. Graph embedding is a way to transform and encode the data structure in high dimensional and non-Euclidean feature space to a low dimensional and structural space, which is easily exploited by other machine learning algorithms. We have witnessed a huge surge of such embedding methods, from statistical approaches to recent deep learning methods such as the graph convolutional networks (GCN). Deep learning approaches usually outperform the traditional methods in most graph learning benchmarks by building an end-to-end learning framework to optimize the loss function directly. However, most of the existing GCN methods can only perform convolution operations with node features, while ignoring the handy information in edge features, such as relations in knowledge graphs. To address this problem, we present CensNet, Convolution with Edge-Node Switching graph neural network, for learning tasks in graph-structured data with both node and edge features. CensNet is a general graph embedding framework, which embeds both nodes and edges to a latent feature space. By using line graph of the original undirected graph, the role of nodes and edges are switched, and two novel graph convolution operations are proposed for feature propagation. Experimental results on real-world academic citation networks and quantum chemistry graphs show that our approach achieves or matches the state-of-the-art performance in four graph learning tasks, including semi-supervised node classification, multi-task graph classification, graph regression, and link prediction.
Spectral Algorithms for Community Detection in Directed Networks
Aug 09, 2020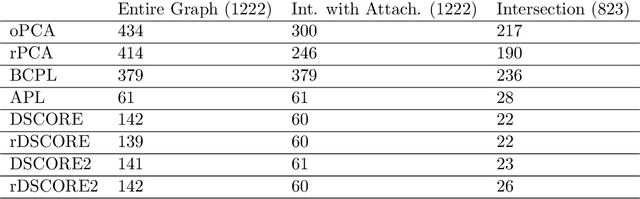
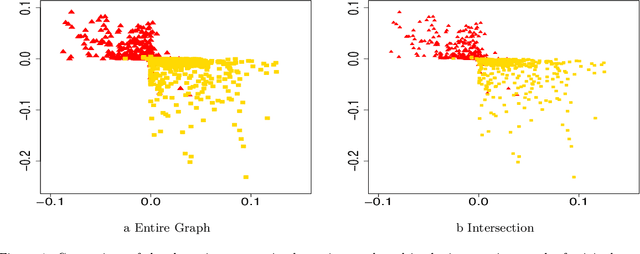
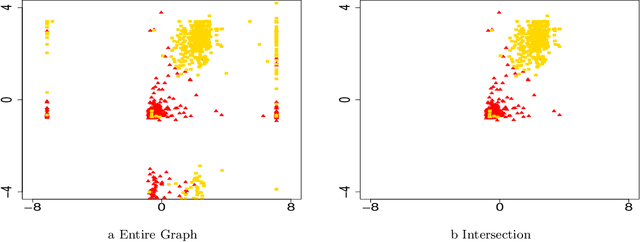
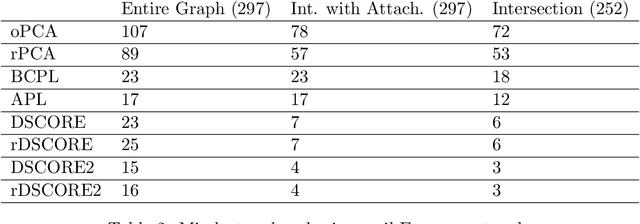
Community detection in large social networks is affected by degree heterogeneity of nodes. The D-SCORE algorithm for directed networks was introduced to reduce this effect by taking the element-wise ratios of the singular vectors of the adjacency matrix before clustering. Meaningful results were obtained for the statistician citation network, but rigorous analysis on its performance was missing. First, this paper establishes theoretical guarantee for this algorithm and its variants for the directed degree-corrected block model (Directed-DCBM). Second, this paper provides significant improvements for the original D-SCORE algorithms by attaching the nodes outside of the community cores using the information of the original network instead of the singular vectors.