 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecent Advances in Text Analysis
Paper and Code
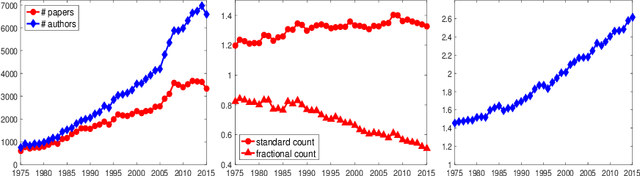
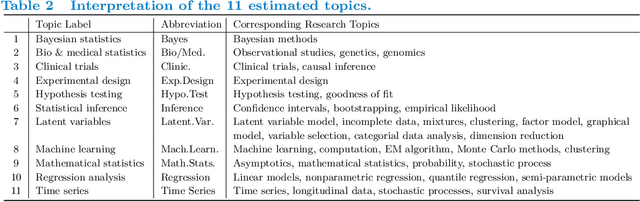
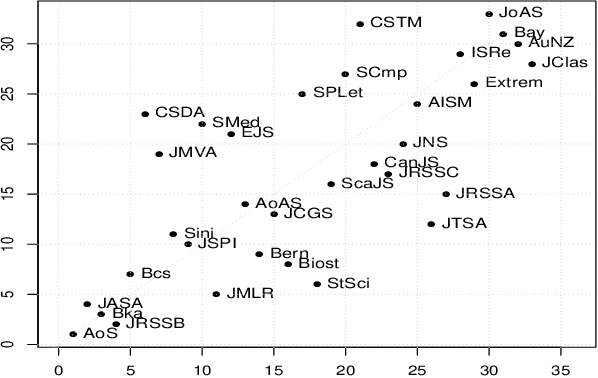
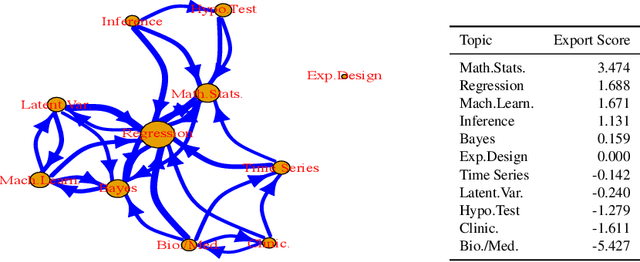
Text analysis is an interesting research area in data science and has various applications, such as in artificial intelligence, biomedical research, and engineering. We review popular methods for text analysis, ranging from topic modeling to the recent neural language models. In particular, we review Topic-SCORE, a statistical approach to topic modeling, and discuss how to use it to analyze MADStat - a dataset on statistical publications that we collected and cleaned. The application of Topic-SCORE and other methods on MADStat leads to interesting findings. For example, $11$ representative topics in statistics are identified. For each journal, the evolution of topic weights over time can be visualized, and these results are used to analyze the trends in statistical research. In particular, we propose a new statistical model for ranking the citation impacts of $11$ topics, and we also build a cross-topic citation graph to illustrate how research results on different topics spread to one another. The results on MADStat provide a data-driven picture of the statistical research in $1975$--$2015$, from a text analysis perspective.