 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniSER: A Foundation Model for Unified Soft Effects Removal
Nov 18, 2025Digital images are often degraded by soft effects such as lens flare, haze, shadows, and reflections, which reduce aesthetics even though the underlying pixels remain partially visible. The prevailing works address these degradations in isolation, developing highly specialized, specialist models that lack scalability and fail to exploit the shared underlying essences of these restoration problems. While specialist models are limited, recent large-scale pretrained generalist models offer powerful, text-driven image editing capabilities. while recent general-purpose systems (e.g., GPT-4o, Flux Kontext, Nano Banana) require detailed prompts and often fail to achieve robust removal on these fine-grained tasks or preserve identity of the scene. Leveraging the common essence of soft effects, i.e., semi-transparent occlusions, we introduce a foundational versatile model UniSER, capable of addressing diverse degradations caused by soft effects within a single framework. Our methodology centers on curating a massive 3.8M-pair dataset to ensure robustness and generalization, which includes novel, physically-plausible data to fill critical gaps in public benchmarks, and a tailored training pipeline that fine-tunes a Diffusion Transformer to learn robust restoration priors from this diverse data, integrating fine-grained mask and strength controls. This synergistic approach allows UniSER to significantly outperform both specialist and generalist models, achieving robust, high-fidelity restoration in the wild.
Layer- and Timestep-Adaptive Differentiable Token Compression Ratios for Efficient Diffusion Transformers
Dec 22, 2024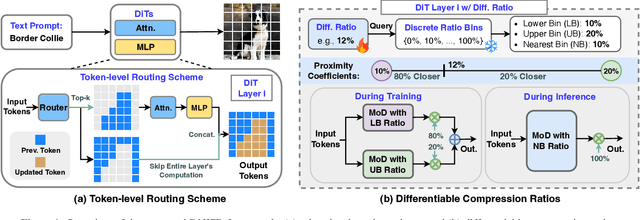



Diffusion Transformers (DiTs) have achieved state-of-the-art (SOTA) image generation quality but suffer from high latency and memory inefficiency, making them difficult to deploy on resource-constrained devices. One key efficiency bottleneck is that existing DiTs apply equal computation across all regions of an image. However, not all image tokens are equally important, and certain localized areas require more computation, such as objects. To address this, we propose DiffRatio-MoD, a dynamic DiT inference framework with differentiable compression ratios, which automatically learns to dynamically route computation across layers and timesteps for each image token, resulting in Mixture-of-Depths (MoD) efficient DiT models. Specifically, DiffRatio-MoD integrates three features: (1) A token-level routing scheme where each DiT layer includes a router that is jointly fine-tuned with model weights to predict token importance scores. In this way, unimportant tokens bypass the entire layer's computation; (2) A layer-wise differentiable ratio mechanism where different DiT layers automatically learn varying compression ratios from a zero initialization, resulting in large compression ratios in redundant layers while others remain less compressed or even uncompressed; (3) A timestep-wise differentiable ratio mechanism where each denoising timestep learns its own compression ratio. The resulting pattern shows higher ratios for noisier timesteps and lower ratios as the image becomes clearer. Extensive experiments on both text-to-image and inpainting tasks show that DiffRatio-MoD effectively captures dynamism across token, layer, and timestep axes, achieving superior trade-offs between generation quality and efficiency compared to prior works.
Perceptual Artifacts Localization for Image Synthesis Tasks
Oct 09, 2023



Recent advancements in deep generative models have facilitated the creation of photo-realistic images across various tasks. However, these generated images often exhibit perceptual artifacts in specific regions, necessitating manual correction. In this study, we present a comprehensive empirical examination of Perceptual Artifacts Localization (PAL) spanning diverse image synthesis endeavors. We introduce a novel dataset comprising 10,168 generated images, each annotated with per-pixel perceptual artifact labels across ten synthesis tasks. A segmentation model, trained on our proposed dataset, effectively localizes artifacts across a range of tasks. Additionally, we illustrate its proficiency in adapting to previously unseen models using minimal training samples. We further propose an innovative zoom-in inpainting pipeline that seamlessly rectifies perceptual artifacts in the generated images. Through our experimental analyses, we elucidate several practical downstream applications, such as automated artifact rectification, non-referential image quality evaluation, and abnormal region detection in images. The dataset and code are released.
SimpSON: Simplifying Photo Cleanup with Single-Click Distracting Object Segmentation Network
May 28, 2023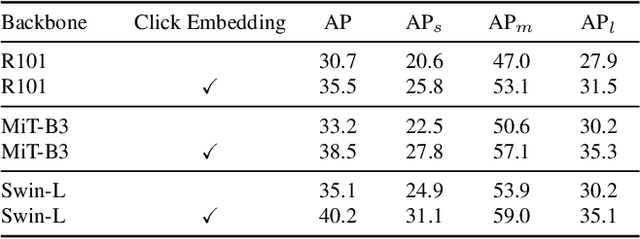
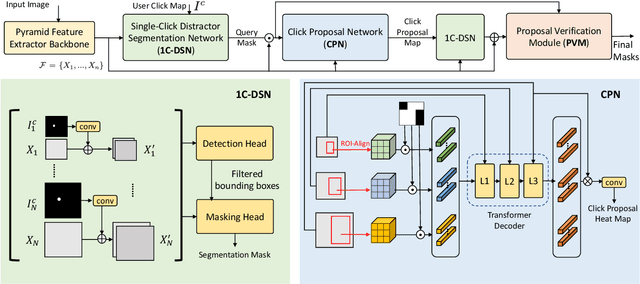
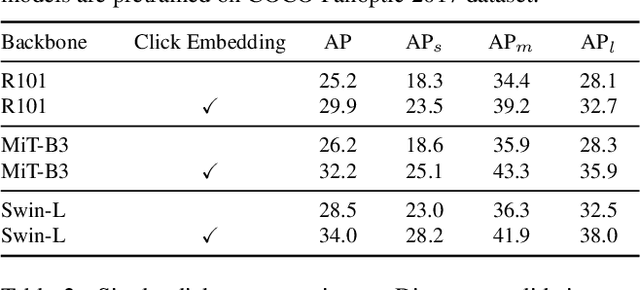
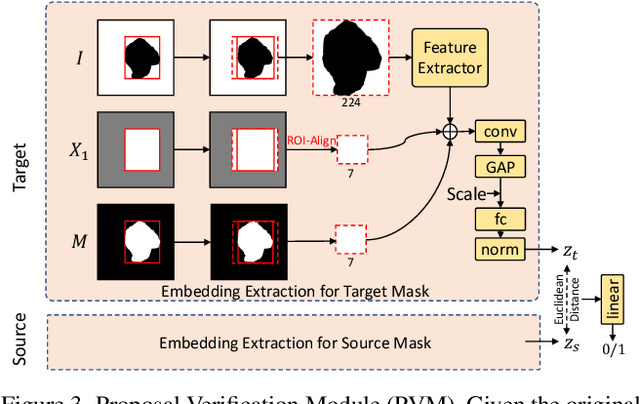
In photo editing, it is common practice to remove visual distractions to improve the overall image quality and highlight the primary subject. However, manually selecting and removing these small and dense distracting regions can be a laborious and time-consuming task. In this paper, we propose an interactive distractor selection method that is optimized to achieve the task with just a single click. Our method surpasses the precision and recall achieved by the traditional method of running panoptic segmentation and then selecting the segments containing the clicks. We also showcase how a transformer-based module can be used to identify more distracting regions similar to the user's click position. Our experiments demonstrate that the model can effectively and accurately segment unknown distracting objects interactively and in groups. By significantly simplifying the photo cleaning and retouching process, our proposed model provides inspiration for exploring rare object segmentation and group selection with a single click.
Automatic High Resolution Wire Segmentation and Removal
Apr 01, 2023



Wires and powerlines are common visual distractions that often undermine the aesthetics of photographs. The manual process of precisely segmenting and removing them is extremely tedious and may take up hours, especially on high-resolution photos where wires may span the entire space. In this paper, we present an automatic wire clean-up system that eases the process of wire segmentation and removal/inpainting to within a few seconds. We observe several unique challenges: wires are thin, lengthy, and sparse. These are rare properties of subjects that common segmentation tasks cannot handle, especially in high-resolution images. We thus propose a two-stage method that leverages both global and local contexts to accurately segment wires in high-resolution images efficiently, and a tile-based inpainting strategy to remove the wires given our predicted segmentation masks. We also introduce the first wire segmentation benchmark dataset, WireSegHR. Finally, we demonstrate quantitatively and qualitatively that our wire clean-up system enables fully automated wire removal with great generalization to various wire appearances.
Structure-Guided Image Completion with Image-level and Object-level Semantic Discriminators
Dec 13, 2022Structure-guided image completion aims to inpaint a local region of an image according to an input guidance map from users. While such a task enables many practical applications for interactive editing, existing methods often struggle to hallucinate realistic object instances in complex natural scenes. Such a limitation is partially due to the lack of semantic-level constraints inside the hole region as well as the lack of a mechanism to enforce realistic object generation. In this work, we propose a learning paradigm that consists of semantic discriminators and object-level discriminators for improving the generation of complex semantics and objects. Specifically, the semantic discriminators leverage pretrained visual features to improve the realism of the generated visual concepts. Moreover, the object-level discriminators take aligned instances as inputs to enforce the realism of individual objects. Our proposed scheme significantly improves the generation quality and achieves state-of-the-art results on various tasks, including segmentation-guided completion, edge-guided manipulation and panoptically-guided manipulation on Places2 datasets. Furthermore, our trained model is flexible and can support multiple editing use cases, such as object insertion, replacement, removal and standard inpainting. In particular, our trained model combined with a novel automatic image completion pipeline achieves state-of-the-art results on the standard inpainting task.
Inpainting at Modern Camera Resolution by Guided PatchMatch with Auto-Curation
Aug 06, 2022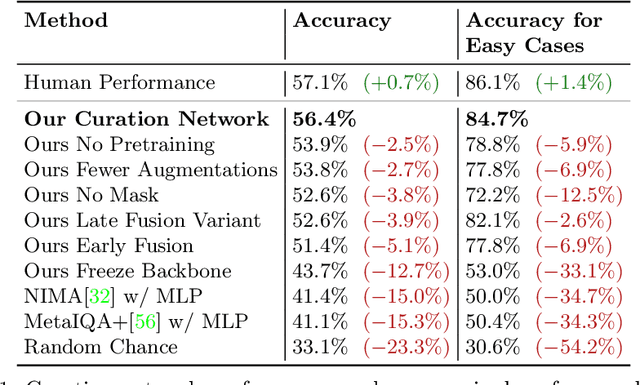

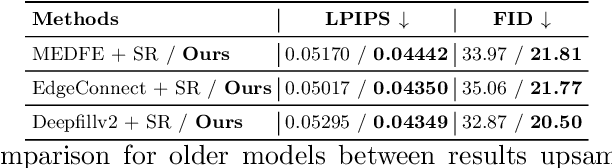

Recently, deep models have established SOTA performance for low-resolution image inpainting, but they lack fidelity at resolutions associated with modern cameras such as 4K or more, and for large holes. We contribute an inpainting benchmark dataset of photos at 4K and above representative of modern sensors. We demonstrate a novel framework that combines deep learning and traditional methods. We use an existing deep inpainting model LaMa to fill the hole plausibly, establish three guide images consisting of structure, segmentation, depth, and apply a multiply-guided PatchMatch to produce eight candidate upsampled inpainted images. Next, we feed all candidate inpaintings through a novel curation module that chooses a good inpainting by column summation on an 8x8 antisymmetric pairwise preference matrix. Our framework's results are overwhelmingly preferred by users over 8 strong baselines, with improvements of quantitative metrics up to 7.4 over the best baseline LaMa, and our technique when paired with 4 different SOTA inpainting backbones improves each such that ours is overwhelmingly preferred by users over a strong super-res baseline.
Perceptual Artifacts Localization for Inpainting
Aug 05, 2022Image inpainting is an essential task for multiple practical applications like object removal and image editing. Deep GAN-based models greatly improve the inpainting performance in structures and textures within the hole, but might also generate unexpected artifacts like broken structures or color blobs. Users perceive these artifacts to judge the effectiveness of inpainting models, and retouch these imperfect areas to inpaint again in a typical retouching workflow. Inspired by this workflow, we propose a new learning task of automatic segmentation of inpainting perceptual artifacts, and apply the model for inpainting model evaluation and iterative refinement. Specifically, we first construct a new inpainting artifacts dataset by manually annotating perceptual artifacts in the results of state-of-the-art inpainting models. Then we train advanced segmentation networks on this dataset to reliably localize inpainting artifacts within inpainted images. Second, we propose a new interpretable evaluation metric called Perceptual Artifact Ratio (PAR), which is the ratio of objectionable inpainted regions to the entire inpainted area. PAR demonstrates a strong correlation with real user preference. Finally, we further apply the generated masks for iterative image inpainting by combining our approach with multiple recent inpainting methods. Extensive experiments demonstrate the consistent decrease of artifact regions and inpainting quality improvement across the different methods.
CM-GAN: Image Inpainting with Cascaded Modulation GAN and Object-Aware Training
Mar 22, 2022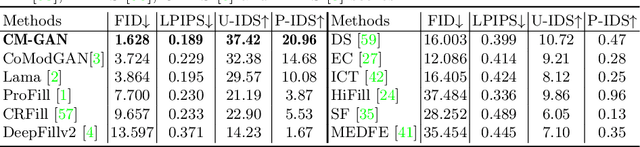
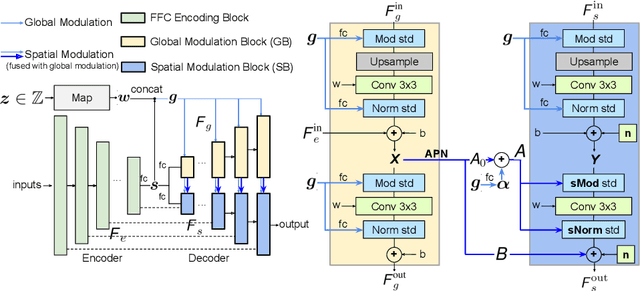
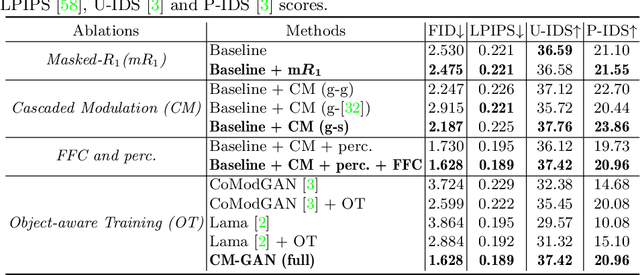

Recent image inpainting methods have made great progress but often struggle to generate plausible image structures when dealing with large holes in complex images. This is partially due to the lack of effective network structures that can capture both the long-range dependency and high-level semantics of an image. To address these problems, we propose cascaded modulation GAN (CM-GAN), a new network design consisting of an encoder with Fourier convolution blocks that extract multi-scale feature representations from the input image with holes and a StyleGAN-like decoder with a novel cascaded global-spatial modulation block at each scale level. In each decoder block, global modulation is first applied to perform coarse semantic-aware structure synthesis, then spatial modulation is applied on the output of global modulation to further adjust the feature map in a spatially adaptive fashion. In addition, we design an object-aware training scheme to prevent the network from hallucinating new objects inside holes, fulfilling the needs of object removal tasks in real-world scenarios. Extensive experiments are conducted to show that our method significantly outperforms existing methods in both quantitative and qualitative evaluation.
GeoFill: Reference-Based Image Inpainting of Scenes with Complex Geometry
Jan 20, 2022

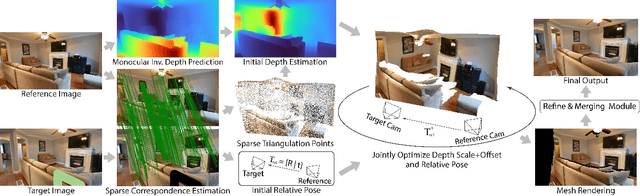
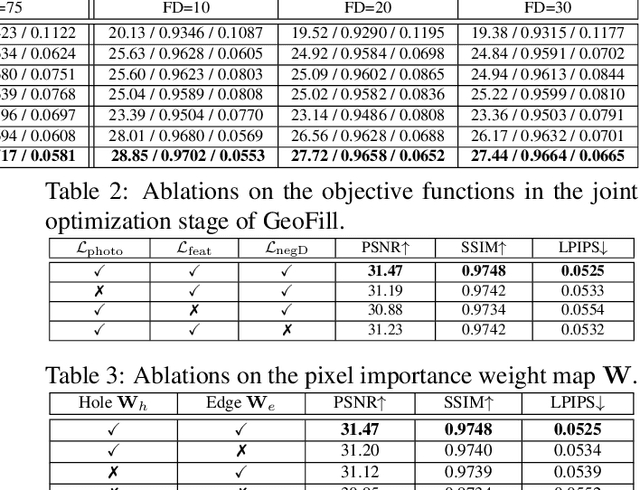
Reference-guided image inpainting restores image pixels by leveraging the content from another reference image. The previous state-of-the-art, TransFill, warps the source image with multiple homographies, and fuses them together for hole filling. Inspired by structure from motion pipelines and recent progress in monocular depth estimation, we propose a more principled approach that does not require heuristic planar assumptions. We leverage a monocular depth estimate and predict relative pose between cameras, then align the reference image to the target by a differentiable 3D reprojection and a joint optimization of relative pose and depth map scale and offset. Our approach achieves state-of-the-art performance on both RealEstate10K and MannequinChallenge dataset with large baselines, complex geometry and extreme camera motions. We experimentally verify our approach is also better at handling large holes.