 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Accurate Reconstruction of 3D Scene Shape from A Single Monocular Image
Aug 28, 2022

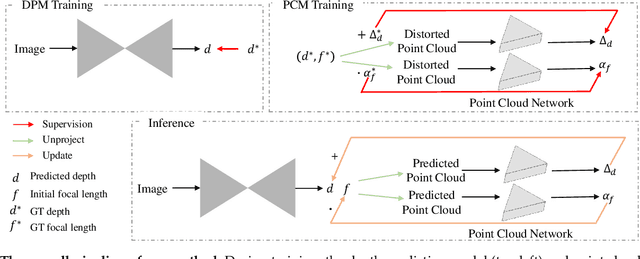
Despite significant progress made in the past few years, challenges remain for depth estimation using a single monocular image. First, it is nontrivial to train a metric-depth prediction model that can generalize well to diverse scenes mainly due to limited training data. Thus, researchers have built large-scale relative depth datasets that are much easier to collect. However, existing relative depth estimation models often fail to recover accurate 3D scene shapes due to the unknown depth shift caused by training with the relative depth data. We tackle this problem here and attempt to estimate accurate scene shapes by training on large-scale relative depth data, and estimating the depth shift. To do so, we propose a two-stage framework that first predicts depth up to an unknown scale and shift from a single monocular image, and then exploits 3D point cloud data to predict the depth shift and the camera's focal length that allow us to recover 3D scene shapes. As the two modules are trained separately, we do not need strictly paired training data. In addition, we propose an image-level normalized regression loss and a normal-based geometry loss to improve training with relative depth annotation. We test our depth model on nine unseen datasets and achieve state-of-the-art performance on zero-shot evaluation. Code is available at: https://git.io/Depth
Towards Domain-agnostic Depth Completion
Jul 29, 2022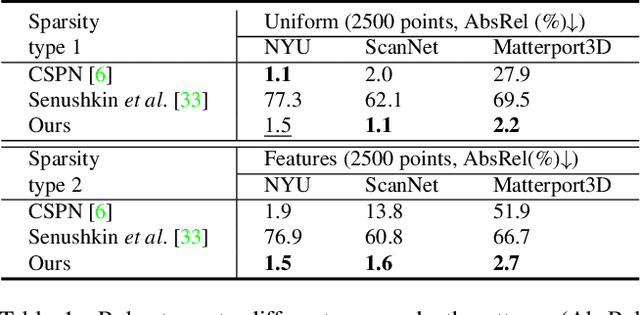

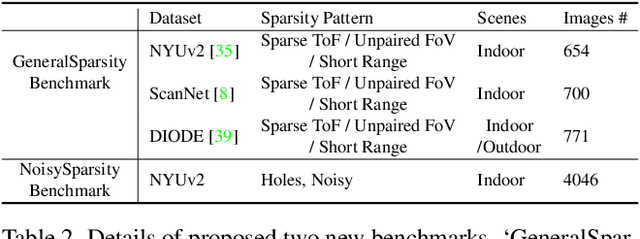

Existing depth completion methods are often targeted at a specific sparse depth type, and generalize poorly across task domains. We present a method to complete sparse/semi-dense, noisy, and potentially low-resolution depth maps obtained by various range sensors, including those in modern mobile phones, or by multi-view reconstruction algorithms. Our method leverages a data driven prior in the form of a single image depth prediction network trained on large-scale datasets, the output of which is used as an input to our model. We propose an effective training scheme where we simulate various sparsity patterns in typical task domains. In addition, we design two new benchmarks to evaluate the generalizability and the robustness of depth completion methods. Our simple method shows superior cross-domain generalization ability against state-of-the-art depth completion methods, introducing a practical solution to high quality depth capture on a mobile device. Code is available at: https://github.com/YvanYin/FillDepth.
Layered Depth Refinement with Mask Guidance
Jun 07, 2022
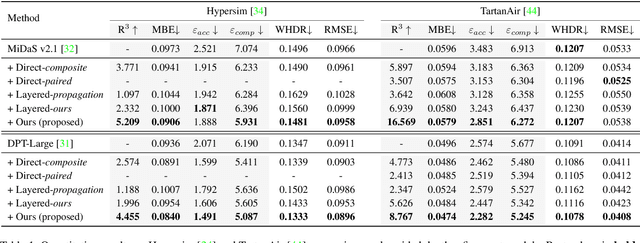
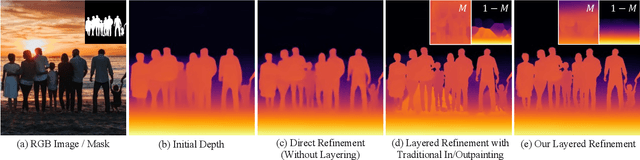
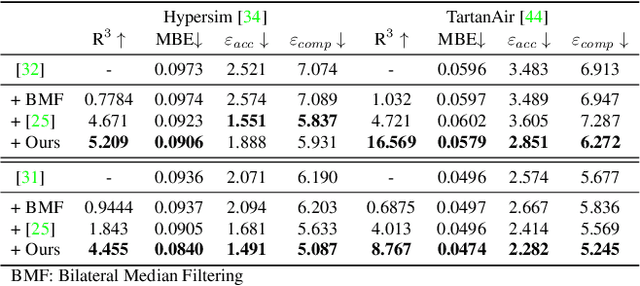
Depth maps are used in a wide range of applications from 3D rendering to 2D image effects such as Bokeh. However, those predicted by single image depth estimation (SIDE) models often fail to capture isolated holes in objects and/or have inaccurate boundary regions. Meanwhile, high-quality masks are much easier to obtain, using commercial auto-masking tools or off-the-shelf methods of segmentation and matting or even by manual editing. Hence, in this paper, we formulate a novel problem of mask-guided depth refinement that utilizes a generic mask to refine the depth prediction of SIDE models. Our framework performs layered refinement and inpainting/outpainting, decomposing the depth map into two separate layers signified by the mask and the inverse mask. As datasets with both depth and mask annotations are scarce, we propose a self-supervised learning scheme that uses arbitrary masks and RGB-D datasets. We empirically show that our method is robust to different types of masks and initial depth predictions, accurately refining depth values in inner and outer mask boundary regions. We further analyze our model with an ablation study and demonstrate results on real applications. More information can be found at https://sooyekim.github.io/MaskDepth/ .
SSH: A Self-Supervised Framework for Image Harmonization
Aug 17, 2021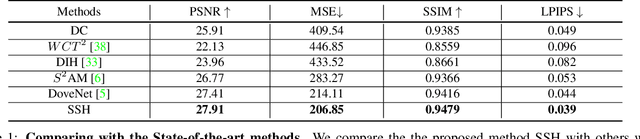
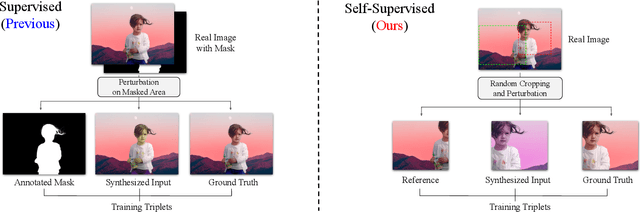
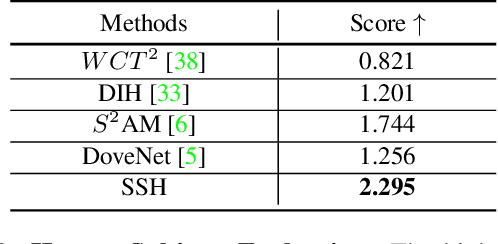
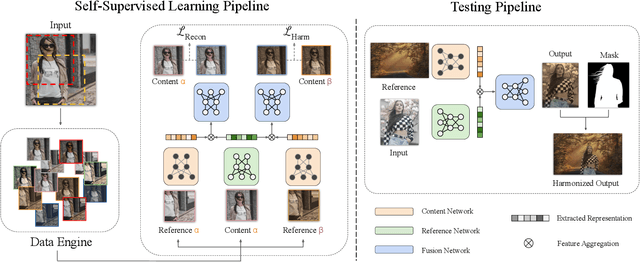
Image harmonization aims to improve the quality of image compositing by matching the "appearance" (\eg, color tone, brightness and contrast) between foreground and background images. However, collecting large-scale annotated datasets for this task requires complex professional retouching. Instead, we propose a novel Self-Supervised Harmonization framework (SSH) that can be trained using just "free" natural images without being edited. We reformulate the image harmonization problem from a representation fusion perspective, which separately processes the foreground and background examples, to address the background occlusion issue. This framework design allows for a dual data augmentation method, where diverse [foreground, background, pseudo GT] triplets can be generated by cropping an image with perturbations using 3D color lookup tables (LUTs). In addition, we build a real-world harmonization dataset as carefully created by expert users, for evaluation and benchmarking purposes. Our results show that the proposed self-supervised method outperforms previous state-of-the-art methods in terms of reference metrics, visual quality, and subject user study. Code and dataset are available at \url{https://github.com/VITA-Group/SSHarmonization}.
Learning to Recover 3D Scene Shape from a Single Image
Dec 17, 2020
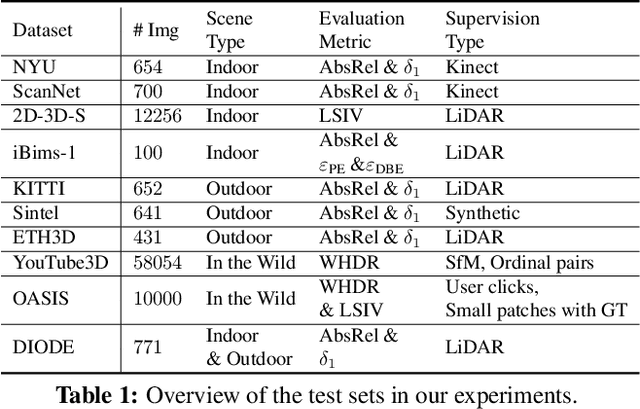


Despite significant progress in monocular depth estimation in the wild, recent state-of-the-art methods cannot be used to recover accurate 3D scene shape due to an unknown depth shift induced by shift-invariant reconstruction losses used in mixed-data depth prediction training, and possible unknown camera focal length. We investigate this problem in detail, and propose a two-stage framework that first predicts depth up to an unknown scale and shift from a single monocular image, and then use 3D point cloud encoders to predict the missing depth shift and focal length that allow us to recover a realistic 3D scene shape. In addition, we propose an image-level normalized regression loss and a normal-based geometry loss to enhance depth prediction models trained on mixed datasets. We test our depth model on nine unseen datasets and achieve state-of-the-art performance on zero-shot dataset generalization. Code is available at: https://git.io/Depth