 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSH: A Self-Supervised Framework for Image Harmonization
Aug 17, 2021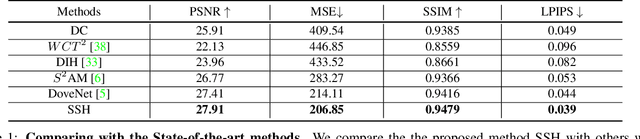
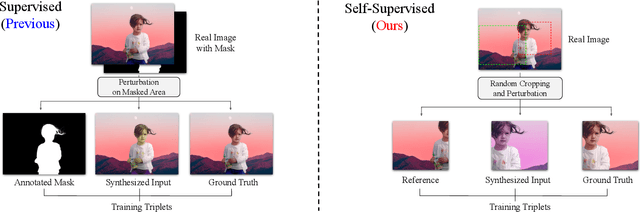
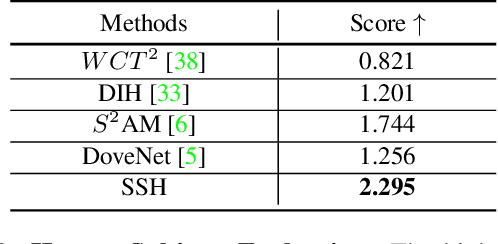
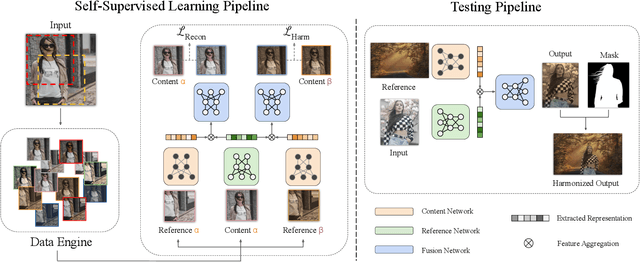
Image harmonization aims to improve the quality of image compositing by matching the "appearance" (\eg, color tone, brightness and contrast) between foreground and background images. However, collecting large-scale annotated datasets for this task requires complex professional retouching. Instead, we propose a novel Self-Supervised Harmonization framework (SSH) that can be trained using just "free" natural images without being edited. We reformulate the image harmonization problem from a representation fusion perspective, which separately processes the foreground and background examples, to address the background occlusion issue. This framework design allows for a dual data augmentation method, where diverse [foreground, background, pseudo GT] triplets can be generated by cropping an image with perturbations using 3D color lookup tables (LUTs). In addition, we build a real-world harmonization dataset as carefully created by expert users, for evaluation and benchmarking purposes. Our results show that the proposed self-supervised method outperforms previous state-of-the-art methods in terms of reference metrics, visual quality, and subject user study. Code and dataset are available at \url{https://github.com/VITA-Group/SSHarmonization}.
DeepLens: Shallow Depth Of Field From A Single Image
Oct 18, 2018



We aim to generate high resolution shallow depth-of-field (DoF) images from a single all-in-focus image with controllable focal distance and aperture size. To achieve this, we propose a novel neural network model comprised of a depth prediction module, a lens blur module, and a guided upsampling module. All modules are differentiable and are learned from data. To train our depth prediction module, we collect a dataset of 2462 RGB-D images captured by mobile phones with a dual-lens camera, and use existing segmentation datasets to improve border prediction. We further leverage a synthetic dataset with known depth to supervise the lens blur and guided upsampling modules. The effectiveness of our system and training strategies are verified in the experiments. Our method can generate high-quality shallow DoF images at high resolution, and produces significantly fewer artifacts than the baselines and existing solutions for single image shallow DoF synthesis. Compared with the iPhone portrait mode, which is a state-of-the-art shallow DoF solution based on a dual-lens depth camera, our method generates comparable results, while allowing for greater flexibility to choose focal points and aperture size, and is not limited to one capture setup.