 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoFill: Reference-Based Image Inpainting of Scenes with Complex Geometry
Paper and Code
Jan 20, 2022

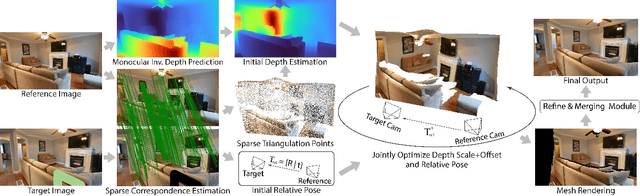
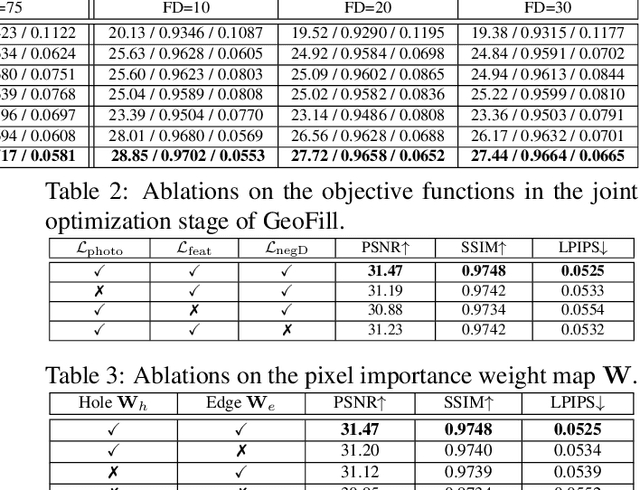
Reference-guided image inpainting restores image pixels by leveraging the content from another reference image. The previous state-of-the-art, TransFill, warps the source image with multiple homographies, and fuses them together for hole filling. Inspired by structure from motion pipelines and recent progress in monocular depth estimation, we propose a more principled approach that does not require heuristic planar assumptions. We leverage a monocular depth estimate and predict relative pose between cameras, then align the reference image to the target by a differentiable 3D reprojection and a joint optimization of relative pose and depth map scale and offset. Our approach achieves state-of-the-art performance on both RealEstate10K and MannequinChallenge dataset with large baselines, complex geometry and extreme camera motions. We experimentally verify our approach is also better at handling large holes.