 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Isolation: A Unified Benchmark for General-Purpose Navigation
May 10, 2026The pursuit of general-purpose embodied agents is hindered by fragmented evaluation protocols that isolate navigation skills and fixate on specific robot morphologies, failing to reflect real-world scenarios where agents must orchestrate diverse behaviors across varying embodiments. To bridge this gap, we introduce OmniNavBench, a benchmark for cross-skill coordination and cross-embodiment generalization. OmniNavBench introduces three paradigm shifts: (1) Compositional Complexity. We propose composite instructions that interleave sub-tasks from 6 categories (PointNav, VLN, ObjectNav, SocialNav, Human Following and EQA), compelling agents to transition between exploration, interaction, and social compliance within a single episode. (2) Morphological Universality and Sensor Flexibility. We present a simulation platform that breaks the reliance on single-morphology evaluation, enabling generalization tests across humanoid, quadrupedal, and wheeled robots, with a modular sensor interface and 170 environments blending synthetic assets with real-world scans. (3) Demonstrations Quality. Moving beyond shortest-path algorithms, we curate 1779 expert trajectories via human teleoperation, capturing behavioral nuances such as exploratory glance and anticipatory avoidance. Extensive evaluations demonstrate that current methods, despite their claimed unified design, struggle with the complex, interleaved nature of general-purpose navigation. This exposes a critical disparity between existing capabilities and real-world deployment demands, underscoring OmniNavBench as a testbed for the next generation of generalist navigators. Dataset, code, and leaderboard are available at http://omninavbench.cloud-ip.cc.
VIGOR: Visual Goal-In-Context Inference for Unified Humanoid Fall Safety
Feb 18, 2026Reliable fall recovery is critical for humanoids operating in cluttered environments. Unlike quadrupeds or wheeled robots, humanoids experience high-energy impacts, complex whole-body contact, and large viewpoint changes during a fall, making recovery essential for continued operation. Existing methods fragment fall safety into separate problems such as fall avoidance, impact mitigation, and stand-up recovery, or rely on end-to-end policies trained without vision through reinforcement learning or imitation learning, often on flat terrain. At a deeper level, fall safety is treated as monolithic data complexity, coupling pose, dynamics, and terrain and requiring exhaustive coverage, limiting scalability and generalization. We present a unified fall safety approach that spans all phases of fall recovery. It builds on two insights: 1) Natural human fall and recovery poses are highly constrained and transferable from flat to complex terrain through alignment, and 2) Fast whole-body reactions require integrated perceptual-motor representations. We train a privileged teacher using sparse human demonstrations on flat terrain and simulated complex terrains, and distill it into a deployable student that relies only on egocentric depth and proprioception. The student learns how to react by matching the teacher's goal-in-context latent representation, which combines the next target pose with the local terrain, rather than separately encoding what it must perceive and how it must act. Results in simulation and on a real Unitree G1 humanoid demonstrate robust, zero-shot fall safety across diverse non-flat environments without real-world fine-tuning. The project page is available at https://vigor2026.github.io/
Unified Humanoid Fall-Safety Policy from a Few Demonstrations
Nov 10, 2025


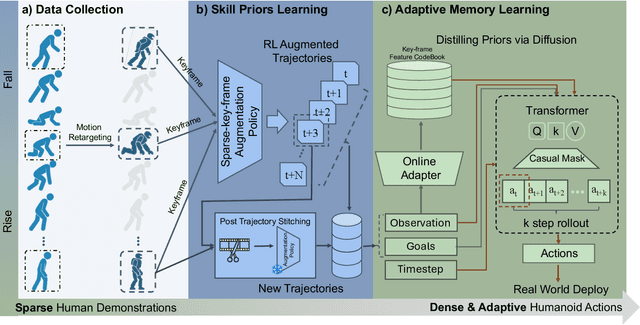
Falling is an inherent risk of humanoid mobility. Maintaining stability is thus a primary safety focus in robot control and learning, yet no existing approach fully averts loss of balance. When instability does occur, prior work addresses only isolated aspects of falling: avoiding falls, choreographing a controlled descent, or standing up afterward. Consequently, humanoid robots lack integrated strategies for impact mitigation and prompt recovery when real falls defy these scripts. We aim to go beyond keeping balance to make the entire fall-and-recovery process safe and autonomous: prevent falls when possible, reduce impact when unavoidable, and stand up when fallen. By fusing sparse human demonstrations with reinforcement learning and an adaptive diffusion-based memory of safe reactions, we learn adaptive whole-body behaviors that unify fall prevention, impact mitigation, and rapid recovery in one policy. Experiments in simulation and on a Unitree G1 demonstrate robust sim-to-real transfer, lower impact forces, and consistently fast recovery across diverse disturbances, pointing towards safer, more resilient humanoids in real environments. Videos are available at https://firm2025.github.io/.
DODT: Enhanced Online Decision Transformer Learning through Dreamer's Actor-Critic Trajectory Forecasting
Oct 15, 2024
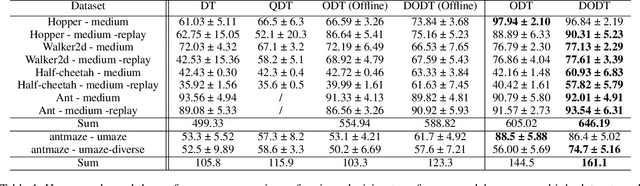
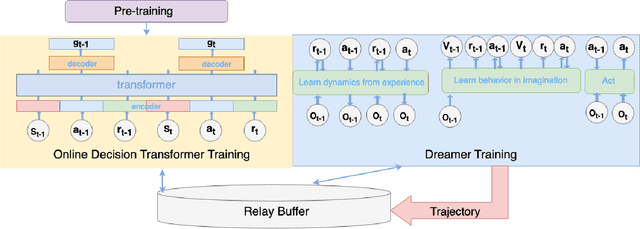
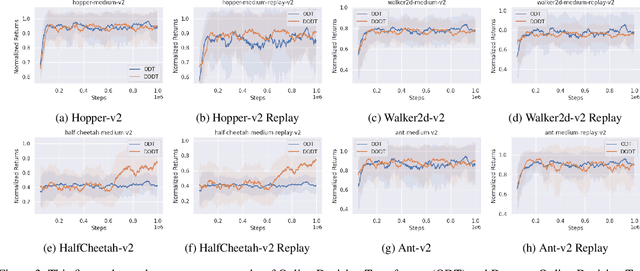
Advancements in reinforcement learning have led to the development of sophisticated models capable of learning complex decision-making tasks. However, efficiently integrating world models with decision transformers remains a challenge. In this paper, we introduce a novel approach that combines the Dreamer algorithm's ability to generate anticipatory trajectories with the adaptive learning strengths of the Online Decision Transformer. Our methodology enables parallel training where Dreamer-produced trajectories enhance the contextual decision-making of the transformer, creating a bidirectional enhancement loop. We empirically demonstrate the efficacy of our approach on a suite of challenging benchmarks, achieving notable improvements in sample efficiency and reward maximization over existing methods. Our results indicate that the proposed integrated framework not only accelerates learning but also showcases robustness in diverse and dynamic scenarios, marking a significant step forward in model-based reinforcement learning.
Perceptual Artifacts Localization for Image Synthesis Tasks
Oct 09, 2023



Recent advancements in deep generative models have facilitated the creation of photo-realistic images across various tasks. However, these generated images often exhibit perceptual artifacts in specific regions, necessitating manual correction. In this study, we present a comprehensive empirical examination of Perceptual Artifacts Localization (PAL) spanning diverse image synthesis endeavors. We introduce a novel dataset comprising 10,168 generated images, each annotated with per-pixel perceptual artifact labels across ten synthesis tasks. A segmentation model, trained on our proposed dataset, effectively localizes artifacts across a range of tasks. Additionally, we illustrate its proficiency in adapting to previously unseen models using minimal training samples. We further propose an innovative zoom-in inpainting pipeline that seamlessly rectifies perceptual artifacts in the generated images. Through our experimental analyses, we elucidate several practical downstream applications, such as automated artifact rectification, non-referential image quality evaluation, and abnormal region detection in images. The dataset and code are released.
HashEncoding: Autoencoding with Multiscale Coordinate Hashing
Nov 29, 2022

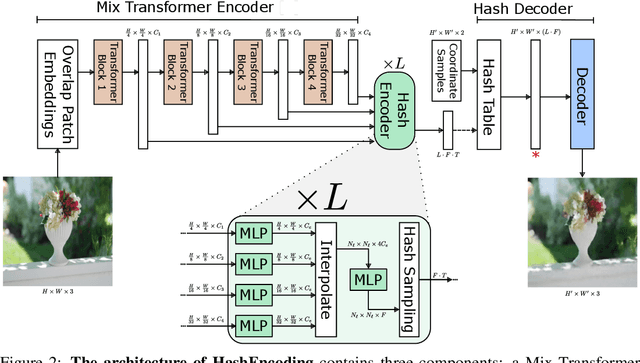

We present HashEncoding, a novel autoencoding architecture that leverages a non-parametric multiscale coordinate hash function to facilitate a per-pixel decoder without convolutions. By leveraging the space-folding behaviour of hashing functions, HashEncoding allows for an inherently multiscale embedding space that remains much smaller than the original image. As a result, the decoder requires very few parameters compared with decoders in traditional autoencoders, approaching a non-parametric reconstruction of the original image and allowing for greater generalizability. Finally, by allowing backpropagation directly to the coordinate space, we show that HashEncoding can be exploited for geometric tasks such as optical flow.