 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents' Last Exam
Jun 03, 2026Recent AI systems have achieved strong results on a wide range of benchmarks, yet these gains have not translated into economically meaningful deployment across many professional domains. We argue that this gap is largely an evaluation problem: widely used benchmarks lack sustained performance measurement on real and economically valuable workflows. This paper introduces Agents' Last Exam (ALE), a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. Developed in collaboration with 250+ industry experts, ALE covers non-physical industries defined with reference to O*NET / SOC 2018 (the U.S. federal occupational taxonomy). It is organized around a task taxonomy with 55 subfields grouped into 13 industry clusters covering 1K+ tasks. Current results show that the hardest tier remains far from saturated: across mainstream harness and backbone configurations, the average full pass rate is 2.6%. ALE is designed as a living benchmark: its task pool grows continuously as new workflows and industries are onboarded. More broadly, ALE is intended not merely as another leaderboard, but as an instrument for closing the gap between benchmark success and GDP-relevant impact.
Refer to Anything with Vision-Language Prompts
Jun 05, 2025Recent image segmentation models have advanced to segment images into high-quality masks for visual entities, and yet they cannot provide comprehensive semantic understanding for complex queries based on both language and vision. This limitation reduces their effectiveness in applications that require user-friendly interactions driven by vision-language prompts. To bridge this gap, we introduce a novel task of omnimodal referring expression segmentation (ORES). In this task, a model produces a group of masks based on arbitrary prompts specified by text only or text plus reference visual entities. To address this new challenge, we propose a novel framework to "Refer to Any Segmentation Mask Group" (RAS), which augments segmentation models with complex multimodal interactions and comprehension via a mask-centric large multimodal model. For training and benchmarking ORES models, we create datasets MaskGroups-2M and MaskGroups-HQ to include diverse mask groups specified by text and reference entities. Through extensive evaluation, we demonstrate superior performance of RAS on our new ORES task, as well as classic referring expression segmentation (RES) and generalized referring expression segmentation (GRES) tasks. Project page: https://Ref2Any.github.io.
Swiss Army Knife: Synergizing Biases in Knowledge from Vision Foundation Models for Multi-Task Learning
Oct 18, 2024Vision Foundation Models (VFMs) have demonstrated outstanding performance on numerous downstream tasks. However, due to their inherent representation biases originating from different training paradigms, VFMs exhibit advantages and disadvantages across distinct vision tasks. Although amalgamating the strengths of multiple VFMs for downstream tasks is an intuitive strategy, effectively exploiting these biases remains a significant challenge. In this paper, we propose a novel and versatile "Swiss Army Knife" (SAK) solution, which adaptively distills knowledge from a committee of VFMs to enhance multi-task learning. Unlike existing methods that use a single backbone for knowledge transfer, our approach preserves the unique representation bias of each teacher by collaborating the lightweight Teacher-Specific Adapter Path modules with the Teacher-Agnostic Stem. Through dynamic selection and combination of representations with Mixture-of-Representations Routers, our SAK is capable of synergizing the complementary strengths of multiple VFMs. Extensive experiments show that our SAK remarkably outperforms prior state of the arts in multi-task learning by 10% on the NYUD-v2 benchmark, while also providing a flexible and robust framework that can readily accommodate more advanced model designs.
Emerging Pixel Grounding in Large Multimodal Models Without Grounding Supervision
Oct 10, 2024



Current large multimodal models (LMMs) face challenges in grounding, which requires the model to relate language components to visual entities. Contrary to the common practice that fine-tunes LMMs with additional grounding supervision, we find that the grounding ability can in fact emerge in LMMs trained without explicit grounding supervision. To reveal this emerging grounding, we introduce an "attend-and-segment" method which leverages attention maps from standard LMMs to perform pixel-level segmentation. Furthermore, to enhance the grounding ability, we propose DIFFLMM, an LMM utilizing a diffusion-based visual encoder, as opposed to the standard CLIP visual encoder, and trained with the same weak supervision. Without being constrained by the biases and limited scale of grounding-specific supervision data, our approach is more generalizable and scalable. We achieve competitive performance on both grounding-specific and general visual question answering benchmarks, compared with grounding LMMs and generalist LMMs, respectively. Notably, we achieve a 44.2 grounding mask recall on grounded conversation generation without any grounding supervision, outperforming the extensively supervised model GLaMM. Project page: https://groundLMM.github.io.
SOHES: Self-supervised Open-world Hierarchical Entity Segmentation
Apr 18, 2024Open-world entity segmentation, as an emerging computer vision task, aims at segmenting entities in images without being restricted by pre-defined classes, offering impressive generalization capabilities on unseen images and concepts. Despite its promise, existing entity segmentation methods like Segment Anything Model (SAM) rely heavily on costly expert annotators. This work presents Self-supervised Open-world Hierarchical Entity Segmentation (SOHES), a novel approach that eliminates the need for human annotations. SOHES operates in three phases: self-exploration, self-instruction, and self-correction. Given a pre-trained self-supervised representation, we produce abundant high-quality pseudo-labels through visual feature clustering. Then, we train a segmentation model on the pseudo-labels, and rectify the noises in pseudo-labels via a teacher-student mutual-learning procedure. Beyond segmenting entities, SOHES also captures their constituent parts, providing a hierarchical understanding of visual entities. Using raw images as the sole training data, our method achieves unprecedented performance in self-supervised open-world segmentation, marking a significant milestone towards high-quality open-world entity segmentation in the absence of human-annotated masks. Project page: https://SOHES.github.io.
TAMM: TriAdapter Multi-Modal Learning for 3D Shape Understanding
Feb 28, 2024The limited scale of current 3D shape datasets hinders the advancements in 3D shape understanding, and motivates multi-modal learning approaches which transfer learned knowledge from data-abundant 2D image and language modalities to 3D shapes. However, even though the image and language representations have been aligned by cross-modal models like CLIP, we find that the image modality fails to contribute as much as the language in existing multi-modal 3D representation learning methods. This is attributed to the domain shift in the 2D images and the distinct focus of each modality. To more effectively leverage both modalities in the pre-training, we introduce TriAdapter Multi-Modal Learning (TAMM) -- a novel two-stage learning approach based on three synergetic adapters. First, our CLIP Image Adapter mitigates the domain gap between 3D-rendered images and natural images, by adapting the visual representations of CLIP for synthetic image-text pairs. Subsequently, our Dual Adapters decouple the 3D shape representation space into two complementary sub-spaces: one focusing on visual attributes and the other for semantic understanding, which ensure a more comprehensive and effective multi-modal pre-training. Extensive experiments demonstrate that TAMM consistently enhances 3D representations for a wide range of 3D encoder architectures, pre-training datasets, and downstream tasks. Notably, we boost the zero-shot classification accuracy on Objaverse-LVIS from 46.8 to 50.7, and improve the 5-way 10-shot linear probing classification accuracy on ModelNet40 from 96.1 to 99.0. Project page: \url{https://alanzhangcs.github.io/tamm-page}.
HASSOD: Hierarchical Adaptive Self-Supervised Object Detection
Feb 05, 2024The human visual perception system demonstrates exceptional capabilities in learning without explicit supervision and understanding the part-to-whole composition of objects. Drawing inspiration from these two abilities, we propose Hierarchical Adaptive Self-Supervised Object Detection (HASSOD), a novel approach that learns to detect objects and understand their compositions without human supervision. HASSOD employs a hierarchical adaptive clustering strategy to group regions into object masks based on self-supervised visual representations, adaptively determining the number of objects per image. Furthermore, HASSOD identifies the hierarchical levels of objects in terms of composition, by analyzing coverage relations between masks and constructing tree structures. This additional self-supervised learning task leads to improved detection performance and enhanced interpretability. Lastly, we abandon the inefficient multi-round self-training process utilized in prior methods and instead adapt the Mean Teacher framework from semi-supervised learning, which leads to a smoother and more efficient training process. Through extensive experiments on prevalent image datasets, we demonstrate the superiority of HASSOD over existing methods, thereby advancing the state of the art in self-supervised object detection. Notably, we improve Mask AR from 20.2 to 22.5 on LVIS, and from 17.0 to 26.0 on SA-1B. Project page: https://HASSOD-NeurIPS23.github.io.
Aligning Large Multimodal Models with Factually Augmented RLHF
Sep 25, 2023Large Multimodal Models (LMM) are built across modalities and the misalignment between two modalities can result in "hallucination", generating textual outputs that are not grounded by the multimodal information in context. To address the multimodal misalignment issue, we adapt the Reinforcement Learning from Human Feedback (RLHF) from the text domain to the task of vision-language alignment, where human annotators are asked to compare two responses and pinpoint the more hallucinated one, and the vision-language model is trained to maximize the simulated human rewards. We propose a new alignment algorithm called Factually Augmented RLHF that augments the reward model with additional factual information such as image captions and ground-truth multi-choice options, which alleviates the reward hacking phenomenon in RLHF and further improves the performance. We also enhance the GPT-4-generated training data (for vision instruction tuning) with previously available human-written image-text pairs to improve the general capabilities of our model. To evaluate the proposed approach in real-world scenarios, we develop a new evaluation benchmark MMHAL-BENCH with a special focus on penalizing hallucinations. As the first LMM trained with RLHF, our approach achieves remarkable improvement on the LLaVA-Bench dataset with the 94% performance level of the text-only GPT-4 (while previous best methods can only achieve the 87% level), and an improvement by 60% on MMHAL-BENCH over other baselines. We opensource our code, model, data at https://llava-rlhf.github.io.
Learning Lightweight Object Detectors via Multi-Teacher Progressive Distillation
Aug 17, 2023Resource-constrained perception systems such as edge computing and vision-for-robotics require vision models to be both accurate and lightweight in computation and memory usage. While knowledge distillation is a proven strategy to enhance the performance of lightweight classification models, its application to structured outputs like object detection and instance segmentation remains a complicated task, due to the variability in outputs and complex internal network modules involved in the distillation process. In this paper, we propose a simple yet surprisingly effective sequential approach to knowledge distillation that progressively transfers the knowledge of a set of teacher detectors to a given lightweight student. To distill knowledge from a highly accurate but complex teacher model, we construct a sequence of teachers to help the student gradually adapt. Our progressive strategy can be easily combined with existing detection distillation mechanisms to consistently maximize student performance in various settings. To the best of our knowledge, we are the first to successfully distill knowledge from Transformer-based teacher detectors to convolution-based students, and unprecedentedly boost the performance of ResNet-50 based RetinaNet from 36.5% to 42.0% AP and Mask R-CNN from 38.2% to 42.5% AP on the MS COCO benchmark.
Contrastive Mean Teacher for Domain Adaptive Object Detectors
May 04, 2023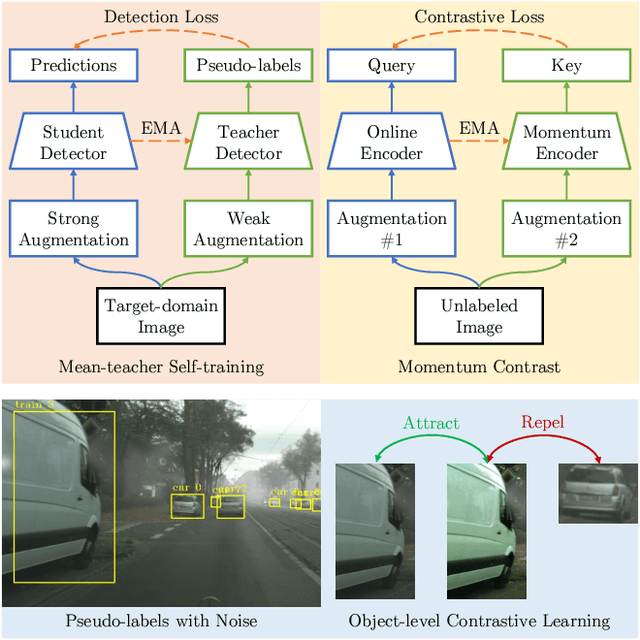
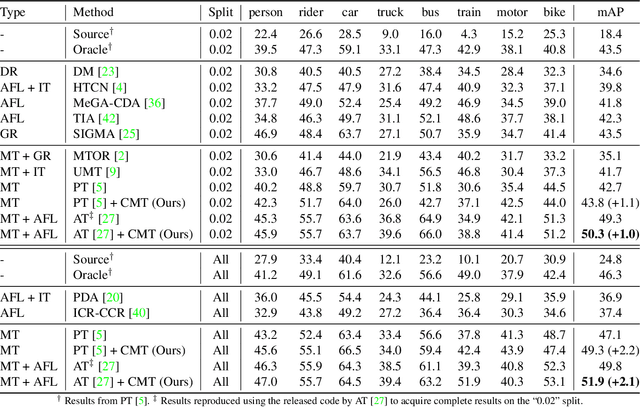
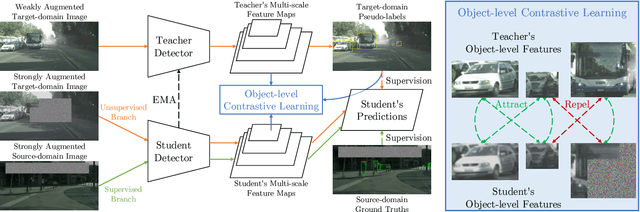
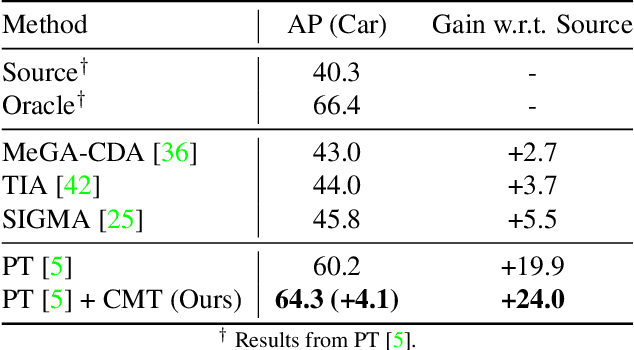
Object detectors often suffer from the domain gap between training (source domain) and real-world applications (target domain). Mean-teacher self-training is a powerful paradigm in unsupervised domain adaptation for object detection, but it struggles with low-quality pseudo-labels. In this work, we identify the intriguing alignment and synergy between mean-teacher self-training and contrastive learning. Motivated by this, we propose Contrastive Mean Teacher (CMT) -- a unified, general-purpose framework with the two paradigms naturally integrated to maximize beneficial learning signals. Instead of using pseudo-labels solely for final predictions, our strategy extracts object-level features using pseudo-labels and optimizes them via contrastive learning, without requiring labels in the target domain. When combined with recent mean-teacher self-training methods, CMT leads to new state-of-the-art target-domain performance: 51.9% mAP on Foggy Cityscapes, outperforming the previously best by 2.1% mAP. Notably, CMT can stabilize performance and provide more significant gains as pseudo-label noise increases.