 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoPoseFormer v2: Accurate Egocentric Human Motion Estimation for AR/VR
Mar 04, 2026Egocentric human motion estimation is essential for AR/VR experiences, yet remains challenging due to limited body coverage from the egocentric viewpoint, frequent occlusions, and scarce labeled data. We present EgoPoseFormer v2, a method that addresses these challenges through two key contributions: (1) a transformer-based model for temporally consistent and spatially grounded body pose estimation, and (2) an auto-labeling system that enables the use of large unlabeled datasets for training. Our model is fully differentiable, introduces identity-conditioned queries, multi-view spatial refinement, causal temporal attention, and supports both keypoints and parametric body representations under a constant compute budget. The auto-labeling system scales learning to tens of millions of unlabeled frames via uncertainty-aware semi-supervised training. The system follows a teacher-student schema to generate pseudo-labels and guide training with uncertainty distillation, enabling the model to generalize to different environments. On the EgoBody3M benchmark, with a 0.8 ms latency on GPU, our model outperforms two state-of-the-art methods by 12.2% and 19.4% in accuracy, and reduces temporal jitter by 22.2% and 51.7%. Furthermore, our auto-labeling system further improves the wrist MPJPE by 13.1%.
No time to train! Training-Free Reference-Based Instance Segmentation
Jul 03, 2025The performance of image segmentation models has historically been constrained by the high cost of collecting large-scale annotated data. The Segment Anything Model (SAM) alleviates this original problem through a promptable, semantics-agnostic, segmentation paradigm and yet still requires manual visual-prompts or complex domain-dependent prompt-generation rules to process a new image. Towards reducing this new burden, our work investigates the task of object segmentation when provided with, alternatively, only a small set of reference images. Our key insight is to leverage strong semantic priors, as learned by foundation models, to identify corresponding regions between a reference and a target image. We find that correspondences enable automatic generation of instance-level segmentation masks for downstream tasks and instantiate our ideas via a multi-stage, training-free method incorporating (1) memory bank construction; (2) representation aggregation and (3) semantic-aware feature matching. Our experiments show significant improvements on segmentation metrics, leading to state-of-the-art performance on COCO FSOD (36.8% nAP), PASCAL VOC Few-Shot (71.2% nAP50) and outperforming existing training-free approaches on the Cross-Domain FSOD benchmark (22.4% nAP).
There is no SAMantics! Exploring SAM as a Backbone for Visual Understanding Tasks
Nov 22, 2024The Segment Anything Model (SAM) was originally designed for label-agnostic mask generation. Does this model also possess inherent semantic understanding, of value to broader visual tasks? In this work we follow a multi-staged approach towards exploring this question. We firstly quantify SAM's semantic capabilities by comparing base image encoder efficacy under classification tasks, in comparison with established models (CLIP and DINOv2). Our findings reveal a significant lack of semantic discriminability in SAM feature representations, limiting potential for tasks that require class differentiation. This initial result motivates our exploratory study that attempts to enable semantic information via in-context learning with lightweight fine-tuning where we observe that generalisability to unseen classes remains limited. Our observations culminate in the proposal of a training-free approach that leverages DINOv2 features, towards better endowing SAM with semantic understanding and achieving instance-level class differentiation through feature-based similarity. Our study suggests that incorporation of external semantic sources provides a promising direction for the enhancement of SAM's utility with respect to complex visual tasks that require semantic understanding.
einspace: Searching for Neural Architectures from Fundamental Operations
May 31, 2024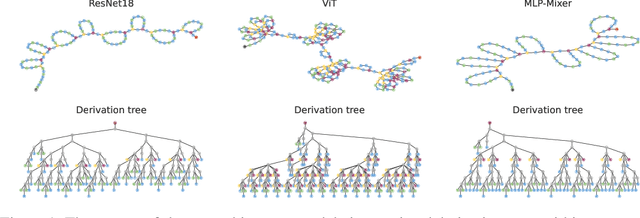
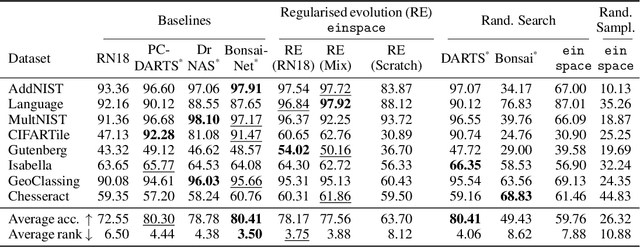

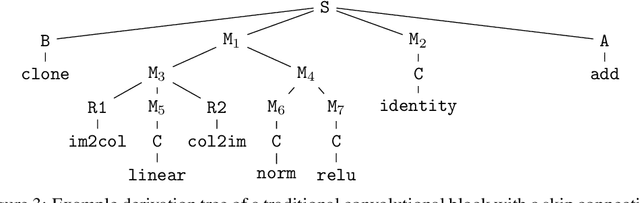
Neural architecture search (NAS) finds high performing networks for a given task. Yet the results of NAS are fairly prosaic; they did not e.g. create a shift from convolutional structures to transformers. This is not least because the search spaces in NAS often aren't diverse enough to include such transformations a priori. Instead, for NAS to provide greater potential for fundamental design shifts, we need a novel expressive search space design which is built from more fundamental operations. To this end, we introduce einspace, a search space based on a parameterised probabilistic context-free grammar. Our space is versatile, supporting architectures of various sizes and complexities, while also containing diverse network operations which allow it to model convolutions, attention components and more. It contains many existing competitive architectures, and provides flexibility for discovering new ones. Using this search space, we perform experiments to find novel architectures as well as improvements on existing ones on the diverse Unseen NAS datasets. We show that competitive architectures can be obtained by searching from scratch, and we consistently find large improvements when initialising the search with strong baselines. We believe that this work is an important advancement towards a transformative NAS paradigm where search space expressivity and strategic search initialisation play key roles.
PlainMamba: Improving Non-Hierarchical Mamba in Visual Recognition
Mar 26, 2024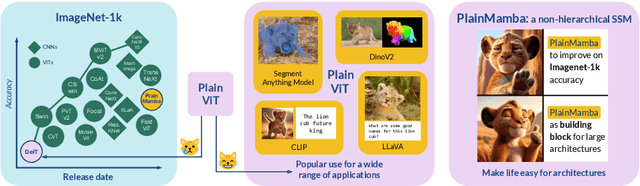
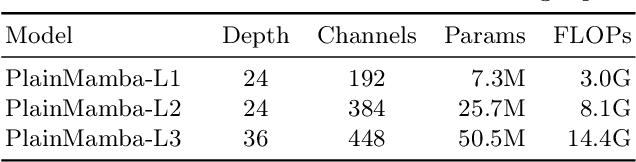
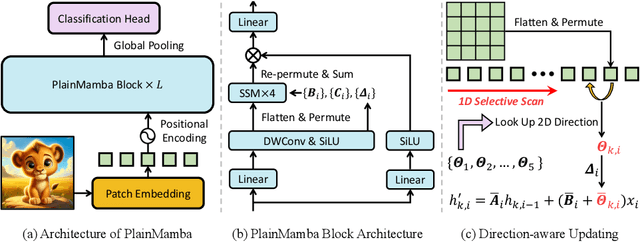
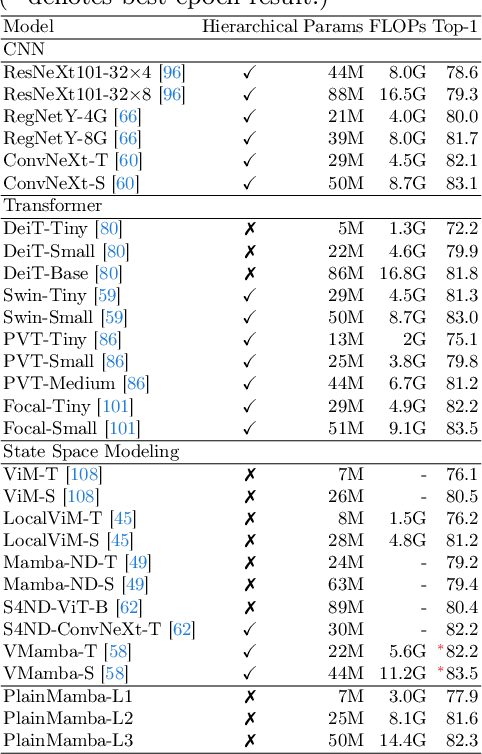
We present PlainMamba: a simple non-hierarchical state space model (SSM) designed for general visual recognition. The recent Mamba model has shown how SSMs can be highly competitive with other architectures on sequential data and initial attempts have been made to apply it to images. In this paper, we further adapt the selective scanning process of Mamba to the visual domain, enhancing its ability to learn features from two-dimensional images by (i) a continuous 2D scanning process that improves spatial continuity by ensuring adjacency of tokens in the scanning sequence, and (ii) direction-aware updating which enables the model to discern the spatial relations of tokens by encoding directional information. Our architecture is designed to be easy to use and easy to scale, formed by stacking identical PlainMamba blocks, resulting in a model with constant width throughout all layers. The architecture is further simplified by removing the need for special tokens. We evaluate PlainMamba on a variety of visual recognition tasks including image classification, semantic segmentation, object detection, and instance segmentation. Our method achieves performance gains over previous non-hierarchical models and is competitive with hierarchical alternatives. For tasks requiring high-resolution inputs, in particular, PlainMamba requires much less computing while maintaining high performance. Code and models are available at https://github.com/ChenhongyiYang/PlainMamba
EgoPoseFormer: A Simple Baseline for Egocentric 3D Human Pose Estimation
Mar 26, 2024



We present EgoPoseFormer, a simple yet effective transformer-based model for stereo egocentric human pose estimation. The main challenge in egocentric pose estimation is overcoming joint invisibility, which is caused by self-occlusion or a limited field of view (FOV) of head-mounted cameras. Our approach overcomes this challenge by incorporating a two-stage pose estimation paradigm: in the first stage, our model leverages the global information to estimate each joint's coarse location, then in the second stage, it employs a DETR style transformer to refine the coarse locations by exploiting fine-grained stereo visual features. In addition, we present a deformable stereo operation to enable our transformer to effectively process multi-view features, which enables it to accurately localize each joint in the 3D world. We evaluate our method on the stereo UnrealEgo dataset and show it significantly outperforms previous approaches while being computationally efficient: it improves MPJPE by 27.4mm (45% improvement) with only 7.9% model parameters and 13.1% FLOPs compared to the state-of-the-art. Surprisingly, with proper training techniques, we find that even our first-stage pose proposal network can achieve superior performance compared to previous arts. We also show that our method can be seamlessly extended to monocular settings, which achieves state-of-the-art performance on the SceneEgo dataset, improving MPJPE by 25.5mm (21% improvement) compared to the best existing method with only 60.7% model parameters and 36.4% FLOPs.
WidthFormer: Toward Efficient Transformer-based BEV View Transformation
Jan 15, 2024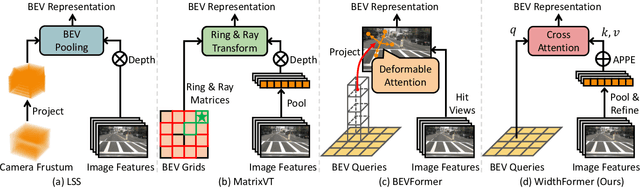



In this work, we present WidthFormer, a novel transformer-based Bird's-Eye-View (BEV) 3D detection method tailored for real-time autonomous-driving applications. WidthFormer is computationally efficient, robust and does not require any special engineering effort to deploy. In this work, we propose a novel 3D positional encoding mechanism capable of accurately encapsulating 3D geometric information, which enables our model to generate high-quality BEV representations with only a single transformer decoder layer. This mechanism is also beneficial for existing sparse 3D object detectors. Inspired by the recently-proposed works, we further improve our model's efficiency by vertically compressing the image features when serving as attention keys and values. We also introduce two modules to compensate for potential information loss due to feature compression. Experimental evaluation on the widely-used nuScenes 3D object detection benchmark demonstrates that our method outperforms previous approaches across different 3D detection architectures. More importantly, our model is highly efficient. For example, when using $256\times 704$ input images, it achieves 1.5 ms and 2.8 ms latency on NVIDIA 3090 GPU and Horizon Journey-5 computation solutions, respectively. Furthermore, WidthFormer also exhibits strong robustness to different degrees of camera perturbations. Our study offers valuable insights into the deployment of BEV transformation methods in real-world, complex road environments. Code is available at https://github.com/ChenhongyiYang/WidthFormer .
GPViT: A High Resolution Non-Hierarchical Vision Transformer with Group Propagation
Dec 13, 2022We present the Group Propagation Vision Transformer (GPViT): a novel nonhierarchical (i.e. non-pyramidal) transformer model designed for general visual recognition with high-resolution features. High-resolution features (or tokens) are a natural fit for tasks that involve perceiving fine-grained details such as detection and segmentation, but exchanging global information between these features is expensive in memory and computation because of the way self-attention scales. We provide a highly efficient alternative Group Propagation Block (GP Block) to exchange global information. In each GP Block, features are first grouped together by a fixed number of learnable group tokens; we then perform Group Propagation where global information is exchanged between the grouped features; finally, global information in the updated grouped features is returned back to the image features through a transformer decoder. We evaluate GPViT on a variety of visual recognition tasks including image classification, semantic segmentation, object detection, and instance segmentation. Our method achieves significant performance gains over previous works across all tasks, especially on tasks that require high-resolution outputs, for example, our GPViT-L3 outperforms Swin Transformer-B by 2.0 mIoU on ADE20K semantic segmentation with only half as many parameters. Code and pre-trained models are available at https://github.com/ChenhongyiYang/GPViT .
Plug and Play Active Learning for Object Detection
Nov 21, 2022Annotating data for supervised learning is expensive and tedious, and we want to do as little of it as possible. To make the most of a given "annotation budget" we can turn to active learning (AL) which aims to identify the most informative samples in a dataset for annotation. Active learning algorithms are typically uncertainty-based or diversity-based. Both have seen success in image classification, but fall short when it comes to object detection. We hypothesise that this is because: (1) it is difficult to quantify uncertainty for object detection as it consists of both localisation and classification, where some classes are harder to localise, and others are harder to classify; (2) it is difficult to measure similarities for diversity-based AL when images contain different numbers of objects. We propose a two-stage active learning algorithm Plug and Play Active Learning (PPAL) that overcomes these difficulties. It consists of (1) Difficulty Calibrated Uncertainty Sampling, in which we used a category-wise difficulty coefficient that takes both classification and localisation into account to re-weight object uncertainties for uncertainty-based sampling; (2) Category Conditioned Matching Similarity to compute the similarities of multi-instance images as ensembles of their instance similarities. PPAL is highly generalisable because it makes no change to model architectures or detector training pipelines. We benchmark PPAL on the MS-COCO and Pascal VOC datasets using different detector architectures and show that our method outperforms the prior state-of-the-art. Code is available at https://github.com/ChenhongyiYang/PPAL
DETRDistill: A Universal Knowledge Distillation Framework for DETR-families
Nov 21, 2022Transformer-based detectors (DETRs) have attracted great attention due to their sparse training paradigm and the removal of post-processing operations, but the huge model can be computationally time-consuming and difficult to be deployed in real-world applications. To tackle this problem, knowledge distillation (KD) can be employed to compress the huge model by constructing a universal teacher-student learning framework. Different from the traditional CNN detectors, where the distillation targets can be naturally aligned through the feature map, DETR regards object detection as a set prediction problem, leading to an unclear relationship between teacher and student during distillation. In this paper, we propose DETRDistill, a novel knowledge distillation dedicated to DETR-families. We first explore a sparse matching paradigm with progressive stage-by-stage instance distillation. Considering the diverse attention mechanisms adopted in different DETRs, we propose attention-agnostic feature distillation module to overcome the ineffectiveness of conventional feature imitation. Finally, to fully leverage the intermediate products from the teacher, we introduce teacher-assisted assignment distillation, which uses the teacher's object queries and assignment results for a group with additional guidance. Extensive experiments demonstrate that our distillation method achieves significant improvement on various competitive DETR approaches, without introducing extra consumption in the inference phase. To the best of our knowledge, this is the first systematic study to explore a general distillation method for DETR-style detectors.