 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Comparison of Crowdworkers and NLP Tools onNamed-Entity Recognition and Sentiment Analysis of Political Tweets
Feb 11, 2020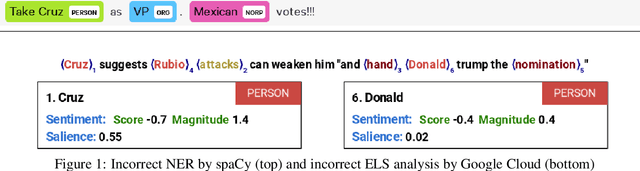
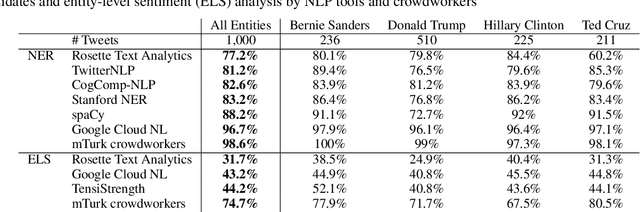
We report results of a comparison of the accuracy of crowdworkers and seven NaturalLanguage Processing (NLP) toolkits in solving two important NLP tasks, named-entity recognition (NER) and entity-level sentiment(ELS) analysis. We here focus on a challenging dataset, 1,000 political tweets that were collected during the U.S. presidential primary election in February 2016. Each tweet refers to at least one of four presidential candidates,i.e., four named entities. The groundtruth, established by experts in political communication, has entity-level sentiment information for each candidate mentioned in the tweet. We tested several commercial and open-source tools. Our experiments show that, for our dataset of political tweets, the most accurate NER system, Google Cloud NL, performed almost on par with crowdworkers, but the most accurate ELS analysis system, TensiStrength, did not match the accuracy of crowdworkers by a large margin of more than 30 percent points.
BUOCA: Budget-Optimized Crowd Worker Allocation
Jan 11, 2019
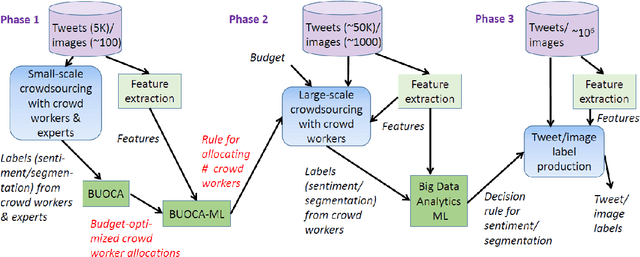
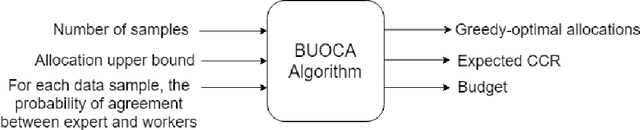

Due to concerns about human error in crowdsourcing, it is standard practice to collect labels for the same data point from multiple internet workers. We here show that the resulting budget can be used more effectively with a flexible worker assignment strategy that asks fewer workers to analyze easy-to-label data and more workers to analyze data that requires extra scrutiny. Our main contribution is to show how the allocations of the number of workers to a task can be computed optimally based on task features alone, without using worker profiles. Our target tasks are delineating cells in microscopy images and analyzing the sentiment toward the 2016 U.S. presidential candidates in tweets. We first propose an algorithm that computes budget-optimized crowd worker allocation (BUOCA). We next train a machine learning system (BUOCA-ML) that predicts an optimal number of crowd workers needed to maximize the accuracy of the labeling. We show that the computed allocation can yield large savings in the crowdsourcing budget (up to 49 percent points) while maintaining labeling accuracy. Finally, we envisage a human-machine system for performing budget-optimized data analysis at a scale beyond the feasibility of crowdsourcing.
Dynamic Allocation of Crowd Contributions for Sentiment Analysis during the 2016 U.S. Presidential Election
Feb 09, 2017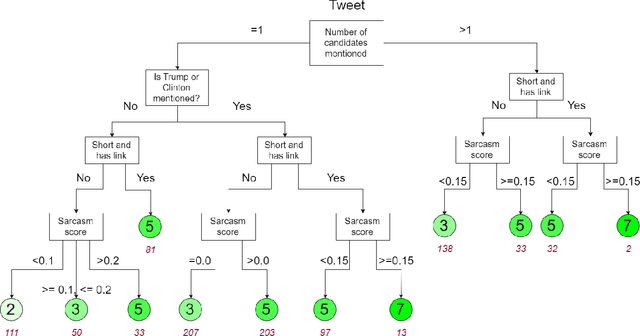
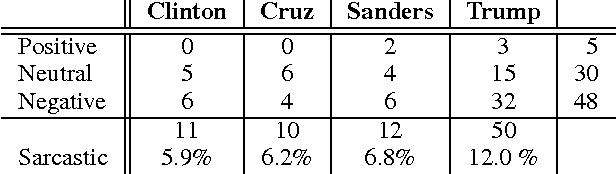
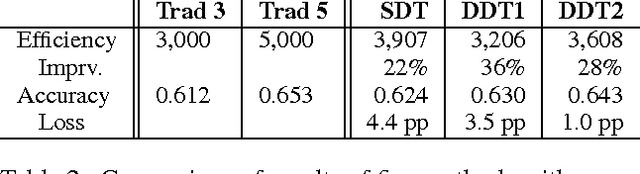

Opinions about the 2016 U.S. Presidential Candidates have been expressed in millions of tweets that are challenging to analyze automatically. Crowdsourcing the analysis of political tweets effectively is also difficult, due to large inter-rater disagreements when sarcasm is involved. Each tweet is typically analyzed by a fixed number of workers and majority voting. We here propose a crowdsourcing framework that instead uses a dynamic allocation of the number of workers. We explore two dynamic-allocation methods: (1) The number of workers queried to label a tweet is computed offline based on the predicted difficulty of discerning the sentiment of a particular tweet. (2) The number of crowd workers is determined online, during an iterative crowd sourcing process, based on inter-rater agreements between labels.We applied our approach to 1,000 twitter messages about the four U.S. presidential candidates Clinton, Cruz, Sanders, and Trump, collected during February 2016. We implemented the two proposed methods using decision trees that allocate more crowd efforts to tweets predicted to be sarcastic. We show that our framework outperforms the traditional static allocation scheme. It collects opinion labels from the crowd at a much lower cost while maintaining labeling accuracy.