 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Deep Classification Models for Domain Generalization
Mar 13, 2020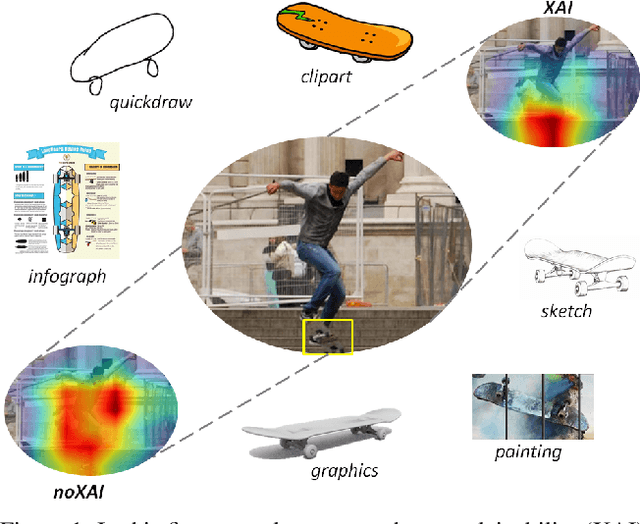
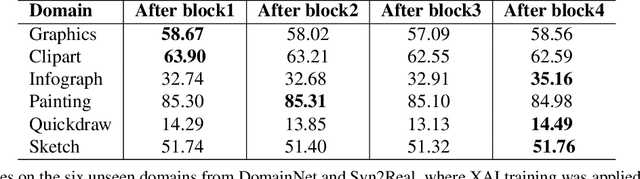
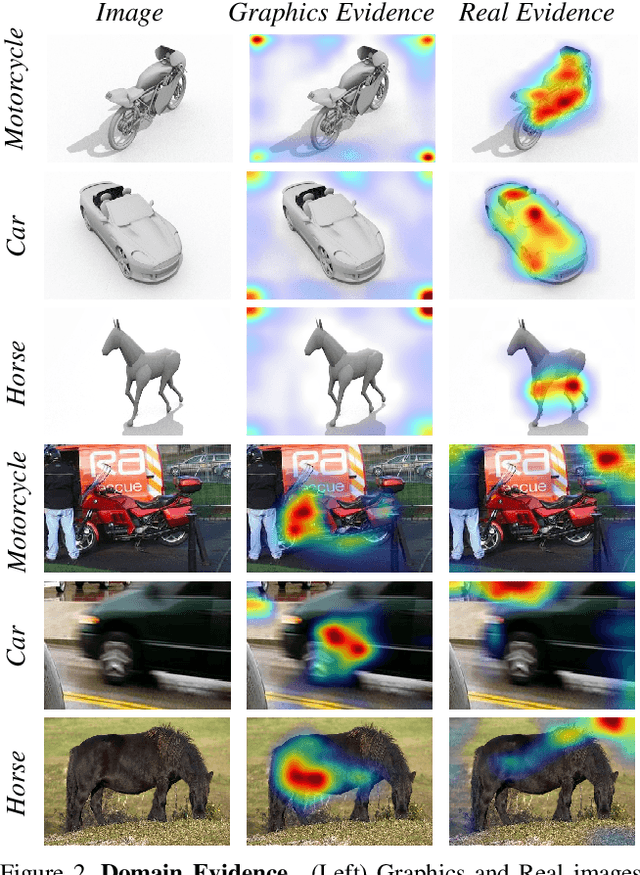

Conventionally, AI models are thought to trade off explainability for lower accuracy. We develop a training strategy that not only leads to a more explainable AI system for object classification, but as a consequence, suffers no perceptible accuracy degradation. Explanations are defined as regions of visual evidence upon which a deep classification network makes a decision. This is represented in the form of a saliency map conveying how much each pixel contributed to the network's decision. Our training strategy enforces a periodic saliency-based feedback to encourage the model to focus on the image regions that directly correspond to the ground-truth object. We quantify explainability using an automated metric, and using human judgement. We propose explainability as a means for bridging the visual-semantic gap between different domains where model explanations are used as a means of disentagling domain specific information from otherwise relevant features. We demonstrate that this leads to improved generalization to new domains without hindering performance on the original domain.
BUOCA: Budget-Optimized Crowd Worker Allocation
Jan 11, 2019
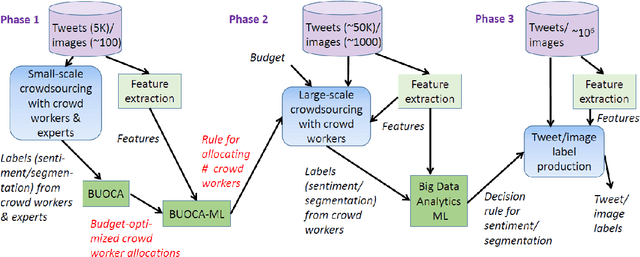
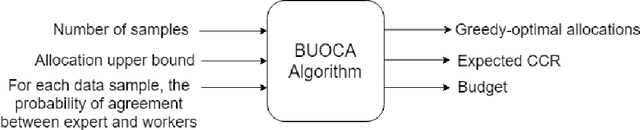

Due to concerns about human error in crowdsourcing, it is standard practice to collect labels for the same data point from multiple internet workers. We here show that the resulting budget can be used more effectively with a flexible worker assignment strategy that asks fewer workers to analyze easy-to-label data and more workers to analyze data that requires extra scrutiny. Our main contribution is to show how the allocations of the number of workers to a task can be computed optimally based on task features alone, without using worker profiles. Our target tasks are delineating cells in microscopy images and analyzing the sentiment toward the 2016 U.S. presidential candidates in tweets. We first propose an algorithm that computes budget-optimized crowd worker allocation (BUOCA). We next train a machine learning system (BUOCA-ML) that predicts an optimal number of crowd workers needed to maximize the accuracy of the labeling. We show that the computed allocation can yield large savings in the crowdsourcing budget (up to 49 percent points) while maintaining labeling accuracy. Finally, we envisage a human-machine system for performing budget-optimized data analysis at a scale beyond the feasibility of crowdsourcing.
Predicting Foreground Object Ambiguity and Efficiently Crowdsourcing the Segmentation(s)
Apr 30, 2017
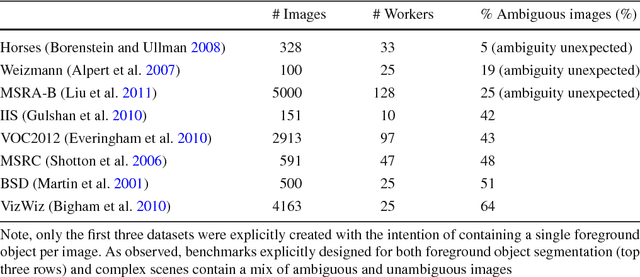


We propose the ambiguity problem for the foreground object segmentation task and motivate the importance of estimating and accounting for this ambiguity when designing vision systems. Specifically, we distinguish between images which lead multiple annotators to segment different foreground objects (ambiguous) versus minor inter-annotator differences of the same object. Taking images from eight widely used datasets, we crowdsource labeling the images as "ambiguous" or "not ambiguous" to segment in order to construct a new dataset we call STATIC. Using STATIC, we develop a system that automatically predicts which images are ambiguous. Experiments demonstrate the advantage of our prediction system over existing saliency-based methods on images from vision benchmarks and images taken by blind people who are trying to recognize objects in their environment. Finally, we introduce a crowdsourcing system to achieve cost savings for collecting the diversity of all valid "ground truth" foreground object segmentations by collecting extra segmentations only when ambiguity is expected. Experiments show our system eliminates up to 47% of human effort compared to existing crowdsourcing methods with no loss in capturing the diversity of ground truths.
Dynamic Allocation of Crowd Contributions for Sentiment Analysis during the 2016 U.S. Presidential Election
Feb 09, 2017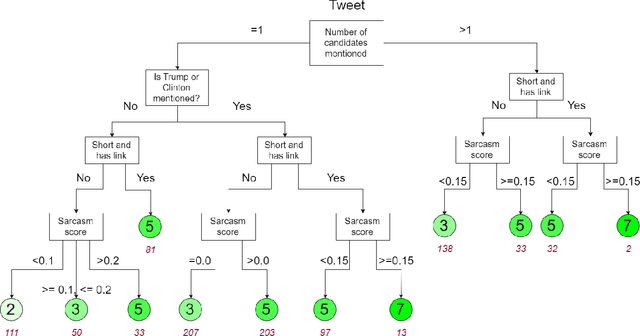
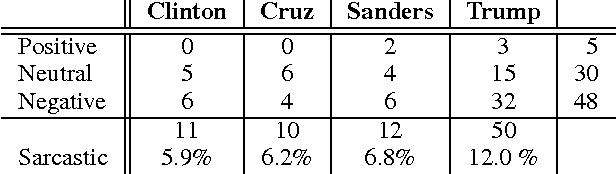
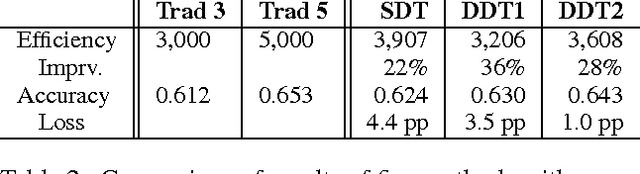

Opinions about the 2016 U.S. Presidential Candidates have been expressed in millions of tweets that are challenging to analyze automatically. Crowdsourcing the analysis of political tweets effectively is also difficult, due to large inter-rater disagreements when sarcasm is involved. Each tweet is typically analyzed by a fixed number of workers and majority voting. We here propose a crowdsourcing framework that instead uses a dynamic allocation of the number of workers. We explore two dynamic-allocation methods: (1) The number of workers queried to label a tweet is computed offline based on the predicted difficulty of discerning the sentiment of a particular tweet. (2) The number of crowd workers is determined online, during an iterative crowd sourcing process, based on inter-rater agreements between labels.We applied our approach to 1,000 twitter messages about the four U.S. presidential candidates Clinton, Cruz, Sanders, and Trump, collected during February 2016. We implemented the two proposed methods using decision trees that allocate more crowd efforts to tweets predicted to be sarcastic. We show that our framework outperforms the traditional static allocation scheme. It collects opinion labels from the crowd at a much lower cost while maintaining labeling accuracy.
Salient Object Subitizing
Jul 26, 2016



We study the problem of Salient Object Subitizing, i.e. predicting the existence and the number of salient objects in an image using holistic cues. This task is inspired by the ability of people to quickly and accurately identify the number of items within the subitizing range (1-4). To this end, we present a salient object subitizing image dataset of about 14K everyday images which are annotated using an online crowdsourcing marketplace. We show that using an end-to-end trained Convolutional Neural Network (CNN) model, we achieve prediction accuracy comparable to human performance in identifying images with zero or one salient object. For images with multiple salient objects, our model also provides significantly better than chance performance without requiring any localization process. Moreover, we propose a method to improve the training of the CNN subitizing model by leveraging synthetic images. In experiments, we demonstrate the accuracy and generalizability of our CNN subitizing model and its applications in salient object detection and image retrieval.