 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Deep Classification Models for Domain Generalization
Paper and Code
Mar 13, 2020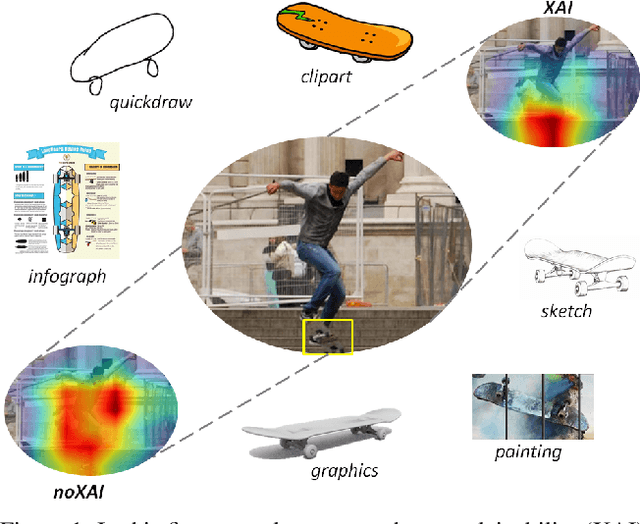
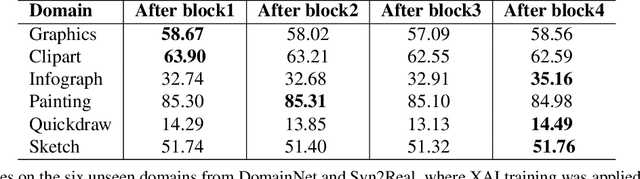
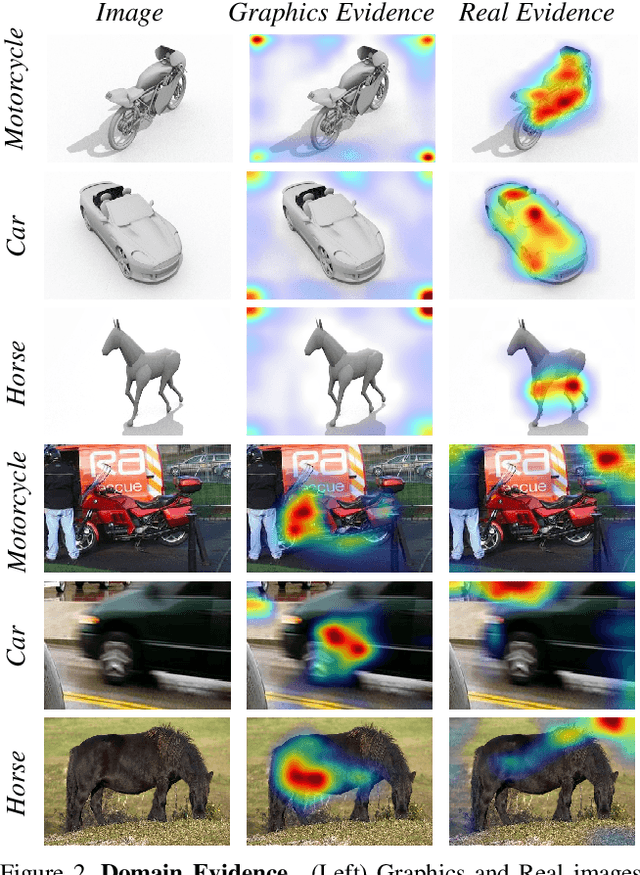

Conventionally, AI models are thought to trade off explainability for lower accuracy. We develop a training strategy that not only leads to a more explainable AI system for object classification, but as a consequence, suffers no perceptible accuracy degradation. Explanations are defined as regions of visual evidence upon which a deep classification network makes a decision. This is represented in the form of a saliency map conveying how much each pixel contributed to the network's decision. Our training strategy enforces a periodic saliency-based feedback to encourage the model to focus on the image regions that directly correspond to the ground-truth object. We quantify explainability using an automated metric, and using human judgement. We propose explainability as a means for bridging the visual-semantic gap between different domains where model explanations are used as a means of disentagling domain specific information from otherwise relevant features. We demonstrate that this leads to improved generalization to new domains without hindering performance on the original domain.