 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Foreground Object Ambiguity and Efficiently Crowdsourcing the Segmentation(s)
Paper and Code
Apr 30, 2017
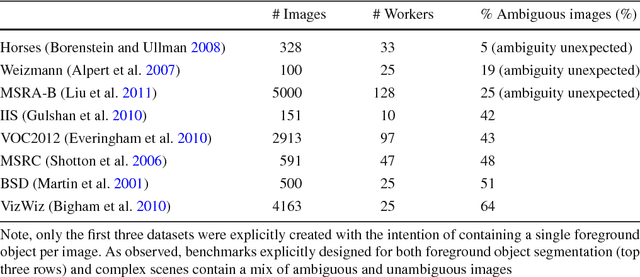


We propose the ambiguity problem for the foreground object segmentation task and motivate the importance of estimating and accounting for this ambiguity when designing vision systems. Specifically, we distinguish between images which lead multiple annotators to segment different foreground objects (ambiguous) versus minor inter-annotator differences of the same object. Taking images from eight widely used datasets, we crowdsource labeling the images as "ambiguous" or "not ambiguous" to segment in order to construct a new dataset we call STATIC. Using STATIC, we develop a system that automatically predicts which images are ambiguous. Experiments demonstrate the advantage of our prediction system over existing saliency-based methods on images from vision benchmarks and images taken by blind people who are trying to recognize objects in their environment. Finally, we introduce a crowdsourcing system to achieve cost savings for collecting the diversity of all valid "ground truth" foreground object segmentations by collecting extra segmentations only when ambiguity is expected. Experiments show our system eliminates up to 47% of human effort compared to existing crowdsourcing methods with no loss in capturing the diversity of ground truths.