 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting How to Distribute Work Between Algorithms and Humans to Segment an Image Batch
Apr 30, 2019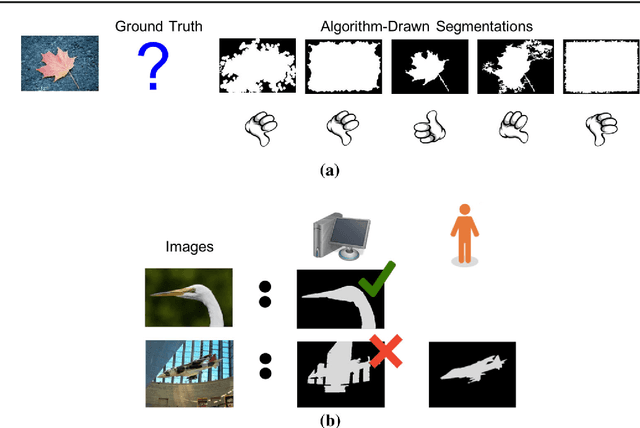
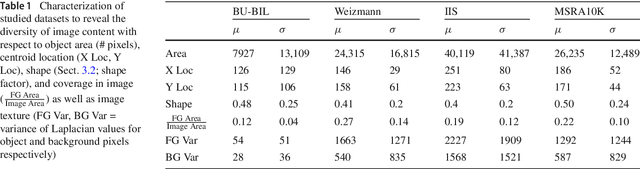
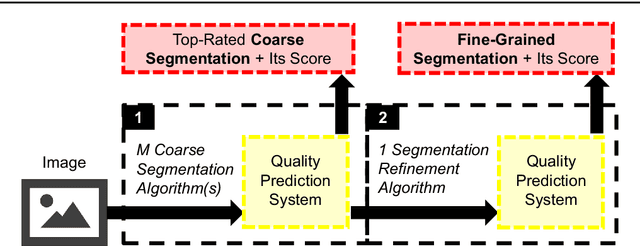
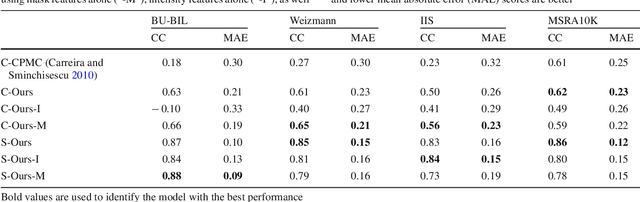
Foreground object segmentation is a critical step for many image analysis tasks. While automated methods can produce high-quality results, their failures disappoint users in need of practical solutions. We propose a resource allocation framework for predicting how best to allocate a fixed budget of human annotation effort in order to collect higher quality segmentations for a given batch of images and automated methods. The framework is based on a prediction module that estimates the quality of given algorithm-drawn segmentations. We demonstrate the value of the framework for two novel tasks related to predicting how to distribute annotation efforts between algorithms and humans. Specifically, we develop two systems that automatically decide, for a batch of images, when to recruit humans versus computers to create 1) coarse segmentations required to initialize segmentation tools and 2) final, fine-grained segmentations. Experiments demonstrate the advantage of relying on a mix of human and computer efforts over relying on either resource alone for segmenting objects in images coming from three diverse modalities (visible, phase contrast microscopy, and fluorescence microscopy).
Pixel Objectness: Learning to Segment Generic Objects Automatically in Images and Videos
Aug 11, 2018


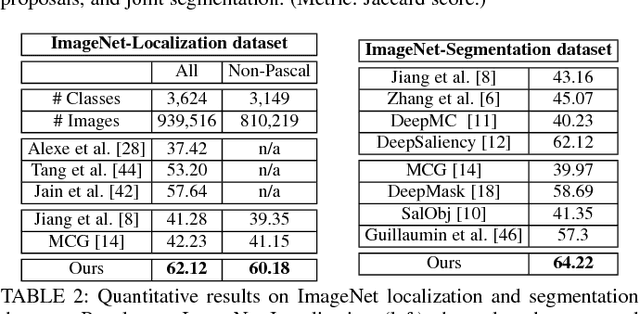
We propose an end-to-end learning framework for segmenting generic objects in both images and videos. Given a novel image or video, our approach produces a pixel-level mask for all "object-like" regions---even for object categories never seen during training. We formulate the task as a structured prediction problem of assigning an object/background label to each pixel, implemented using a deep fully convolutional network. When applied to a video, our model further incorporates a motion stream, and the network learns to combine both appearance and motion and attempts to extract all prominent objects whether they are moving or not. Beyond the core model, a second contribution of our approach is how it leverages varying strengths of training annotations. Pixel-level annotations are quite difficult to obtain, yet crucial for training a deep network approach for segmentation. Thus we propose ways to exploit weakly labeled data for learning dense foreground segmentation. For images, we show the value in mixing object category examples with image-level labels together with relatively few images with boundary-level annotations. For video, we show how to bootstrap weakly annotated videos together with the network trained for image segmentation. Through experiments on multiple challenging image and video segmentation benchmarks, our method offers consistently strong results and improves the state-of-the-art for fully automatic segmentation of generic (unseen) objects. In addition, we demonstrate how our approach benefits image retrieval and image retargeting, both of which flourish when given our high-quality foreground maps. Code, models, and videos are at:http://vision.cs.utexas.edu/projects/pixelobjectness/
Predicting Foreground Object Ambiguity and Efficiently Crowdsourcing the Segmentation(s)
Apr 30, 2017
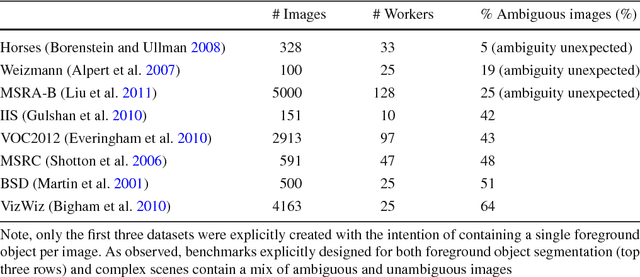


We propose the ambiguity problem for the foreground object segmentation task and motivate the importance of estimating and accounting for this ambiguity when designing vision systems. Specifically, we distinguish between images which lead multiple annotators to segment different foreground objects (ambiguous) versus minor inter-annotator differences of the same object. Taking images from eight widely used datasets, we crowdsource labeling the images as "ambiguous" or "not ambiguous" to segment in order to construct a new dataset we call STATIC. Using STATIC, we develop a system that automatically predicts which images are ambiguous. Experiments demonstrate the advantage of our prediction system over existing saliency-based methods on images from vision benchmarks and images taken by blind people who are trying to recognize objects in their environment. Finally, we introduce a crowdsourcing system to achieve cost savings for collecting the diversity of all valid "ground truth" foreground object segmentations by collecting extra segmentations only when ambiguity is expected. Experiments show our system eliminates up to 47% of human effort compared to existing crowdsourcing methods with no loss in capturing the diversity of ground truths.
Pixel Objectness
Apr 12, 2017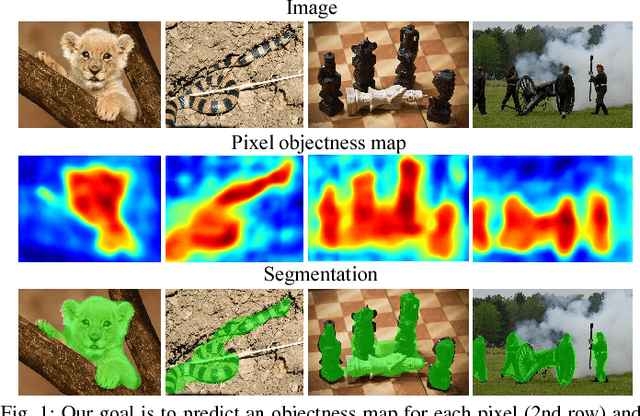



We propose an end-to-end learning framework for generating foreground object segmentations. Given a single novel image, our approach produces pixel-level masks for all "object-like" regions---even for object categories never seen during training. We formulate the task as a structured prediction problem of assigning foreground/background labels to all pixels, implemented using a deep fully convolutional network. Key to our idea is training with a mix of image-level object category examples together with relatively few images with boundary-level annotations. Our method substantially improves the state-of-the-art on foreground segmentation for ImageNet and MIT Object Discovery datasets. Furthermore, on over 1 million images, we show that it generalizes well to segment object categories unseen in the foreground maps used for training. Finally, we demonstrate how our approach benefits image retrieval and image retargeting, both of which flourish when given our high-quality foreground maps.
FusionSeg: Learning to combine motion and appearance for fully automatic segmention of generic objects in videos
Apr 12, 2017

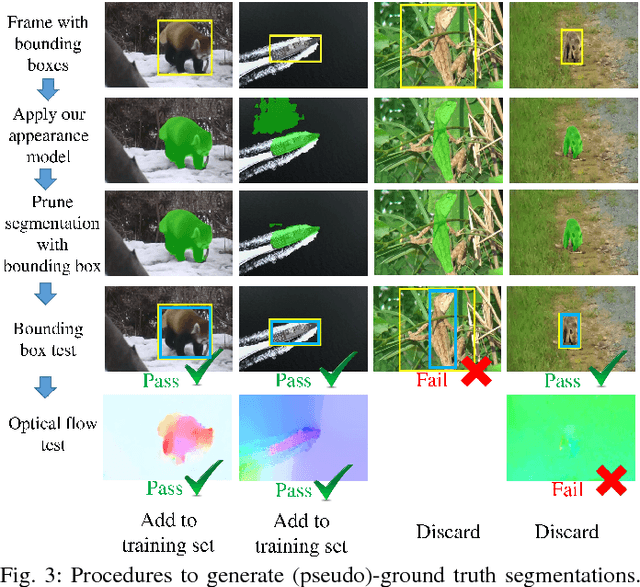

We propose an end-to-end learning framework for segmenting generic objects in videos. Our method learns to combine appearance and motion information to produce pixel level segmentation masks for all prominent objects in videos. We formulate this task as a structured prediction problem and design a two-stream fully convolutional neural network which fuses together motion and appearance in a unified framework. Since large-scale video datasets with pixel level segmentations are problematic, we show how to bootstrap weakly annotated videos together with existing image recognition datasets for training. Through experiments on three challenging video segmentation benchmarks, our method substantially improves the state-of-the-art for segmenting generic (unseen) objects. Code and pre-trained models are available on the project website.
Click Carving: Segmenting Objects in Video with Point Clicks
Jul 05, 2016
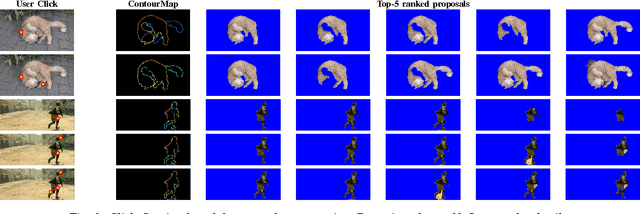

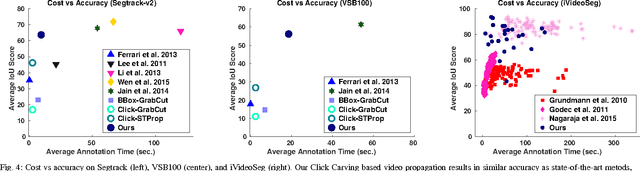
We present a novel form of interactive video object segmentation where a few clicks by the user helps the system produce a full spatio-temporal segmentation of the object of interest. Whereas conventional interactive pipelines take the user's initialization as a starting point, we show the value in the system taking the lead even in initialization. In particular, for a given video frame, the system precomputes a ranked list of thousands of possible segmentation hypotheses (also referred to as object region proposals) using image and motion cues. Then, the user looks at the top ranked proposals, and clicks on the object boundary to carve away erroneous ones. This process iterates (typically 2-3 times), and each time the system revises the top ranked proposal set, until the user is satisfied with a resulting segmentation mask. Finally, the mask is propagated across the video to produce a spatio-temporal object tube. On three challenging datasets, we provide extensive comparisons with both existing work and simpler alternative methods. In all, the proposed Click Carving approach strikes an excellent balance of accuracy and human effort. It outperforms all similarly fast methods, and is competitive or better than those requiring 2 to 12 times the effort.