 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusionSeg: Learning to combine motion and appearance for fully automatic segmention of generic objects in videos
Paper and Code
Apr 12, 2017

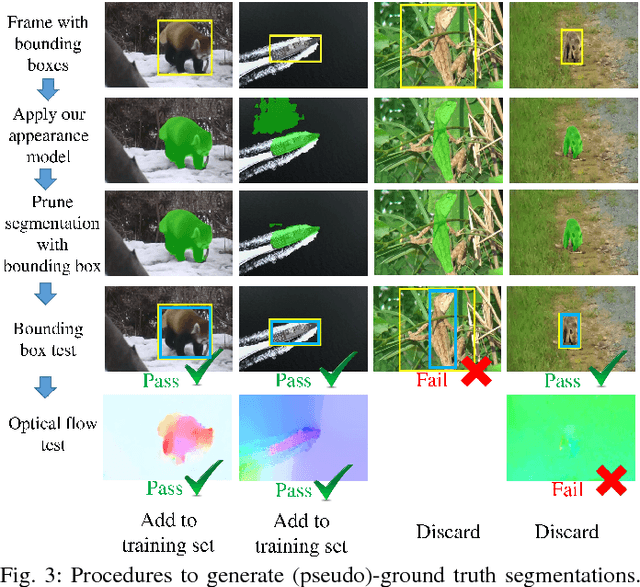

We propose an end-to-end learning framework for segmenting generic objects in videos. Our method learns to combine appearance and motion information to produce pixel level segmentation masks for all prominent objects in videos. We formulate this task as a structured prediction problem and design a two-stream fully convolutional neural network which fuses together motion and appearance in a unified framework. Since large-scale video datasets with pixel level segmentations are problematic, we show how to bootstrap weakly annotated videos together with existing image recognition datasets for training. Through experiments on three challenging video segmentation benchmarks, our method substantially improves the state-of-the-art for segmenting generic (unseen) objects. Code and pre-trained models are available on the project website.