 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDragText: Rethinking Text Embedding in Point-based Image Editing
Jul 25, 2024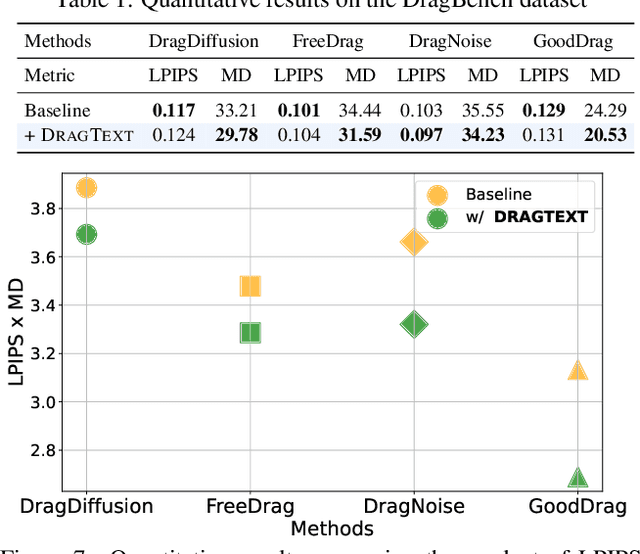
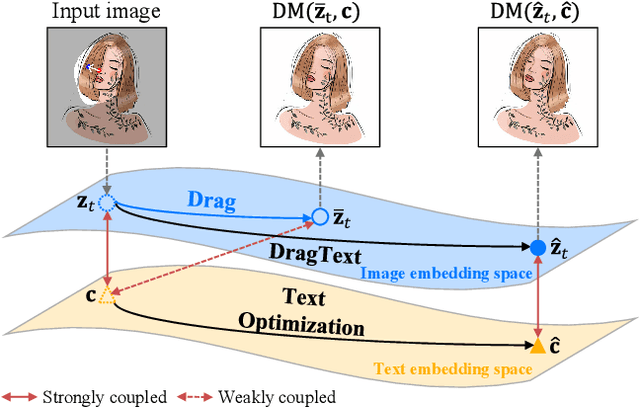


Point-based image editing enables accurate and flexible control through content dragging. However, the role of text embedding in the editing process has not been thoroughly investigated. A significant aspect that remains unexplored is the interaction between text and image embeddings. In this study, we show that during the progressive editing of an input image in a diffusion model, the text embedding remains constant. As the image embedding increasingly diverges from its initial state, the discrepancy between the image and text embeddings presents a significant challenge. Moreover, we found that the text prompt significantly influences the dragging process, particularly in maintaining content integrity and achieving the desired manipulation. To utilize these insights, we propose DragText, which optimizes text embedding in conjunction with the dragging process to pair with the modified image embedding. Simultaneously, we regularize the text optimization process to preserve the integrity of the original text prompt. Our approach can be seamlessly integrated with existing diffusion-based drag methods with only a few lines of code.
Parameter Efficient Fine Tuning for Multi-scanner PET to PET Reconstruction
Jul 10, 2024



Reducing scan time in Positron Emission Tomography (PET) imaging while maintaining high-quality images is crucial for minimizing patient discomfort and radiation exposure. Due to the limited size of datasets and distribution discrepancy across scanners in medical imaging, fine-tuning in a parameter-efficient and effective manner is on the rise. Motivated by the potential of Parameter-Efficient Fine-Tuning (PEFT), we aim to address these issues by effectively leveraging PEFT to improve limited data and GPU resource issues in multi-scanner setups. In this paper, we introduce PETITE, Parameter-Efficient Fine-Tuning for MultI-scanner PET to PET REconstruction that uses fewer than 1% of the parameters. To the best of our knowledge, this study is the first to systematically explore the efficacy of diverse PEFT techniques in medical imaging reconstruction tasks via prevalent encoder-decoder-type deep models. This investigation, in particular, brings intriguing insights into PETITE as we show further improvements by treating encoder and decoder separately and mixing different PEFT methods, namely, Mix-PEFT. Using multi-scanner PET datasets comprised of five different scanners, we extensively test the cross-scanner PET scan time reduction performances (i.e., a model pre-trained on one scanner is fine-tuned on a different scanner) of 21 feasible Mix-PEFT combinations to derive optimal PETITE. We show that training with less than 1% parameters using PETITE performs on par with full fine-tuning (i.e., 100% parameter)