 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Prototype Unit for Image De-raining using Time-Lapse Data
Dec 27, 2024
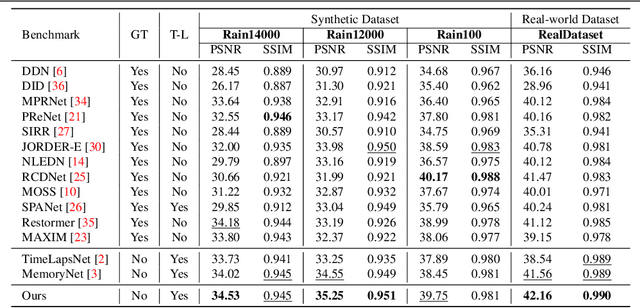
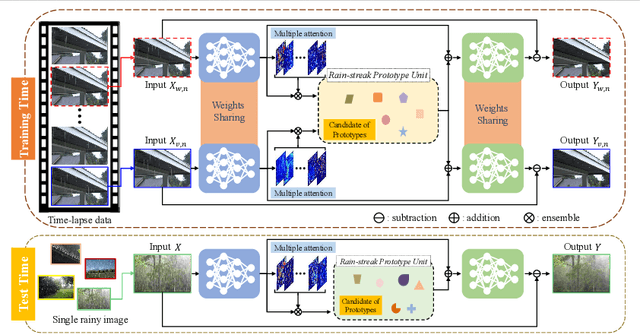

We address the challenge of single-image de-raining, a task that involves recovering rain-free background information from a single rain image. While recent advancements have utilized real-world time-lapse data for training, enabling the estimation of consistent backgrounds and realistic rain streaks, these methods often suffer from computational and memory consumption, limiting their applicability in real-world scenarios. In this paper, we introduce a novel solution: the Rain Streak Prototype Unit (RsPU). The RsPU efficiently encodes rain streak-relevant features as real-time prototypes derived from time-lapse data, eliminating the need for excessive memory resources. Our de-raining network combines encoder-decoder networks with the RsPU, allowing us to learn and encapsulate diverse rain streak-relevant features as concise prototypes, employing an attention-based approach. To ensure the effectiveness of our approach, we propose a feature prototype loss encompassing cohesion and divergence components. This loss function captures both the compactness and diversity aspects of the prototypical rain streak features within the RsPU. Our method evaluates various de-raining benchmarks, accompanied by comprehensive ablation studies. We show that it can achieve competitive results in various rain images compared to state-of-the-art methods.
Improving Image De-raining Using Reference-Guided Transformers
Aug 01, 2024



Image de-raining is a critical task in computer vision to improve visibility and enhance the robustness of outdoor vision systems. While recent advances in de-raining methods have achieved remarkable performance, the challenge remains to produce high-quality and visually pleasing de-rained results. In this paper, we present a reference-guided de-raining filter, a transformer network that enhances de-raining results using a reference clean image as guidance. We leverage the capabilities of the proposed module to further refine the images de-rained by existing methods. We validate our method on three datasets and show that our module can improve the performance of existing prior-based, CNN-based, and transformer-based approaches.
MoNDE: Mixture of Near-Data Experts for Large-Scale Sparse Models
May 29, 2024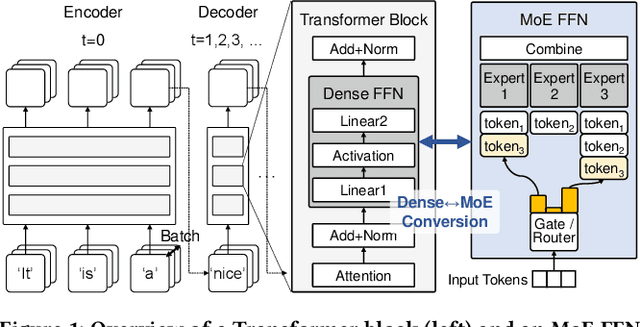

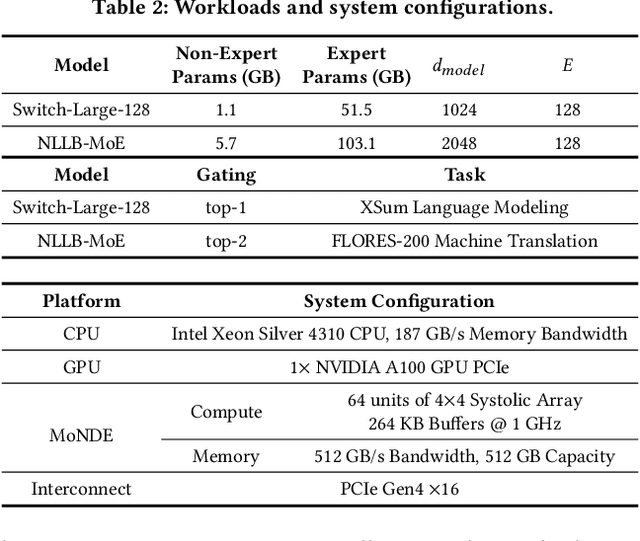
Mixture-of-Experts (MoE) large language models (LLM) have memory requirements that often exceed the GPU memory capacity, requiring costly parameter movement from secondary memories to the GPU for expert computation. In this work, we present Mixture of Near-Data Experts (MoNDE), a near-data computing solution that efficiently enables MoE LLM inference. MoNDE reduces the volume of MoE parameter movement by transferring only the $\textit{hot}$ experts to the GPU, while computing the remaining $\textit{cold}$ experts inside the host memory device. By replacing the transfers of massive expert parameters with the ones of small activations, MoNDE enables far more communication-efficient MoE inference, thereby resulting in substantial speedups over the existing parameter offloading frameworks for both encoder and decoder operations.
Multi-task Learning for Real-time Autonomous Driving Leveraging Task-adaptive Attention Generator
Mar 06, 2024



Real-time processing is crucial in autonomous driving systems due to the imperative of instantaneous decision-making and rapid response. In real-world scenarios, autonomous vehicles are continuously tasked with interpreting their surroundings, analyzing intricate sensor data, and making decisions within split seconds to ensure safety through numerous computer vision tasks. In this paper, we present a new real-time multi-task network adept at three vital autonomous driving tasks: monocular 3D object detection, semantic segmentation, and dense depth estimation. To counter the challenge of negative transfer, which is the prevalent issue in multi-task learning, we introduce a task-adaptive attention generator. This generator is designed to automatically discern interrelations across the three tasks and arrange the task-sharing pattern, all while leveraging the efficiency of the hard-parameter sharing approach. To the best of our knowledge, the proposed model is pioneering in its capability to concurrently handle multiple tasks, notably 3D object detection, while maintaining real-time processing speeds. Our rigorously optimized network, when tested on the Cityscapes-3D datasets, consistently outperforms various baseline models. Moreover, an in-depth ablation study substantiates the efficacy of the methodologies integrated into our framework.
Memory-guided Image De-raining Using Time-Lapse Data
Jan 06, 2022



This paper addresses the problem of single image de-raining, that is, the task of recovering clean and rain-free background scenes from a single image obscured by a rainy artifact. Although recent advances adopt real-world time-lapse data to overcome the need for paired rain-clean images, they are limited to fully exploit the time-lapse data. The main cause is that, in terms of network architectures, they could not capture long-term rain streak information in the time-lapse data during training owing to the lack of memory components. To address this problem, we propose a novel network architecture based on a memory network that explicitly helps to capture long-term rain streak information in the time-lapse data. Our network comprises the encoder-decoder networks and a memory network. The features extracted from the encoder are read and updated in the memory network that contains several memory items to store rain streak-aware feature representations. With the read/update operation, the memory network retrieves relevant memory items in terms of the queries, enabling the memory items to represent the various rain streaks included in the time-lapse data. To boost the discriminative power of memory features, we also present a novel background selective whitening (BSW) loss for capturing only rain streak information in the memory network by erasing the background information. Experimental results on standard benchmarks demonstrate the effectiveness and superiority of our approach.
DIML/CVL RGB-D Dataset: 2M RGB-D Images of Natural Indoor and Outdoor Scenes
Oct 22, 2021



This manual is intended to provide a detailed description of the DIML/CVL RGB-D dataset. This dataset is comprised of 2M color images and their corresponding depth maps from a great variety of natural indoor and outdoor scenes. The indoor dataset was constructed using the Microsoft Kinect v2, while the outdoor dataset was built using the stereo cameras (ZED stereo camera and built-in stereo camera). Table I summarizes the details of our dataset, including acquisition, processing, format, and toolbox. Refer to Section II and III for more details.
Wide and Narrow: Video Prediction from Context and Motion
Oct 22, 2021

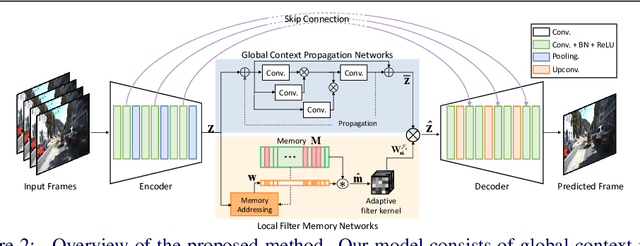
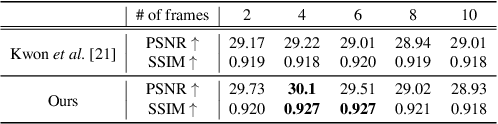
Video prediction, forecasting the future frames from a sequence of input frames, is a challenging task since the view changes are influenced by various factors, such as the global context surrounding the scene and local motion dynamics. In this paper, we propose a new framework to integrate these complementary attributes to predict complex pixel dynamics through deep networks. We present global context propagation networks that iteratively aggregate the non-local neighboring representations to preserve the contextual information over the past frames. To capture the local motion pattern of objects, we also devise local filter memory networks that generate adaptive filter kernels by storing the prototypical motion of moving objects in the memory. The proposed framework, utilizing the outputs from both networks, can address blurry predictions and color distortion. We conduct experiments on Caltech pedestrian and UCF101 datasets, and demonstrate state-of-the-art results. Especially for multi-step prediction, we obtain an outstanding performance in quantitative and qualitative evaluation.
A Large RGB-D Dataset for Semi-supervised Monocular Depth Estimation
Apr 23, 2019



The recent advance of monocular depth estimation is largely based on deeply nested convolutional networks, combined with supervised training. However, it still remains arduous to collect large-scale ground truth depth (or disparity) maps for supervising the networks. This paper presents a simple yet effective semi-supervised approach for monocular depth estimation. Inspired by the human visual system, we propose a student-teacher strategy in which a shallow student network is trained with the auxiliary information obtained from a deeper and accurate teacher network. Specifically, we first train the stereo teacher network fully utilizing the binocular perception of 3D geometry, and then use depth predictions of the teacher network for supervising the student network for monocular depth inference. This enables us to exploit all available depth data from massive unlabeled stereo pairs that are relatively easier-to-obtain. We further introduce a data ensemble strategy that merges multiple depth predictions of the teacher network to improve the training samples for the student network. Additionally, stereo confidence maps are provided to avoid inaccurate depth estimates being used when supervising the student network. Our new training data, consisting of 1 million outdoor stereo images taken using hand-held stereo cameras, is hosted at the project webpage. Lastly, we demonstrate that the monocular depth estimation network provides feature representations that are suitable for some high-level vision tasks such as semantic segmentation and road detection. Extensive experiments demonstrate the effectiveness and flexibility of the proposed method in various outdoor scenarios.