 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIML/CVL RGB-D Dataset: 2M RGB-D Images of Natural Indoor and Outdoor Scenes
Oct 22, 2021



This manual is intended to provide a detailed description of the DIML/CVL RGB-D dataset. This dataset is comprised of 2M color images and their corresponding depth maps from a great variety of natural indoor and outdoor scenes. The indoor dataset was constructed using the Microsoft Kinect v2, while the outdoor dataset was built using the stereo cameras (ZED stereo camera and built-in stereo camera). Table I summarizes the details of our dataset, including acquisition, processing, format, and toolbox. Refer to Section II and III for more details.
Memory-guided Unsupervised Image-to-image Translation
Apr 12, 2021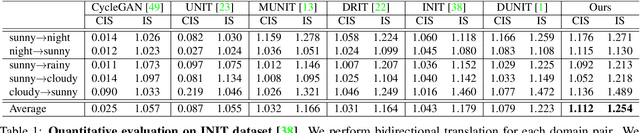
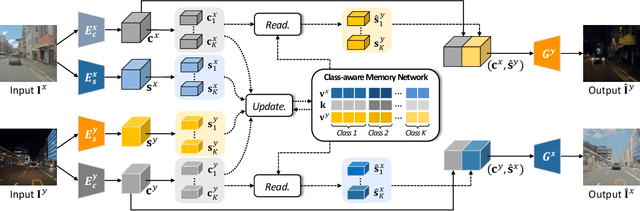
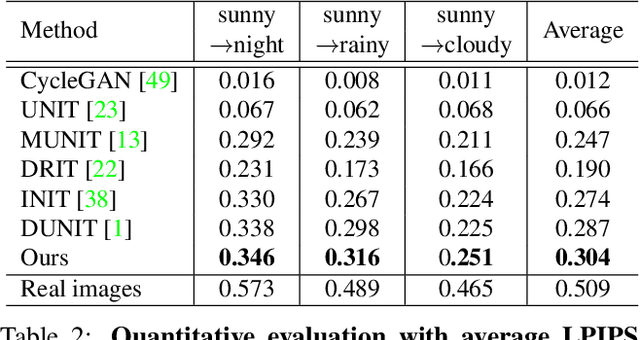
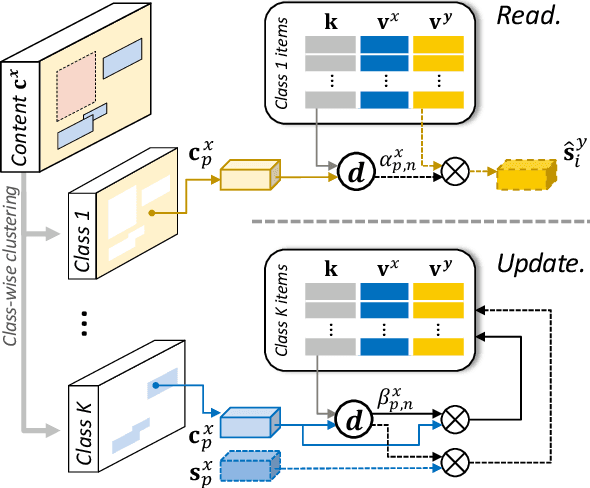
We present a novel unsupervised framework for instance-level image-to-image translation. Although recent advances have been made by incorporating additional object annotations, existing methods often fail to handle images with multiple disparate objects. The main cause is that, during inference, they apply a global style to the whole image and do not consider the large style discrepancy between instance and background, or within instances. To address this problem, we propose a class-aware memory network that explicitly reasons about local style variations. A key-values memory structure, with a set of read/update operations, is introduced to record class-wise style variations and access them without requiring an object detector at the test time. The key stores a domain-agnostic content representation for allocating memory items, while the values encode domain-specific style representations. We also present a feature contrastive loss to boost the discriminative power of memory items. We show that by incorporating our memory, we can transfer class-aware and accurate style representations across domains. Experimental results demonstrate that our model outperforms recent instance-level methods and achieves state-of-the-art performance.
NTIRE 2020 Challenge on Real Image Denoising: Dataset, Methods and Results
May 08, 2020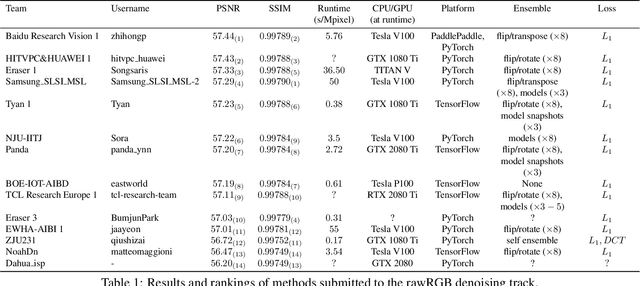
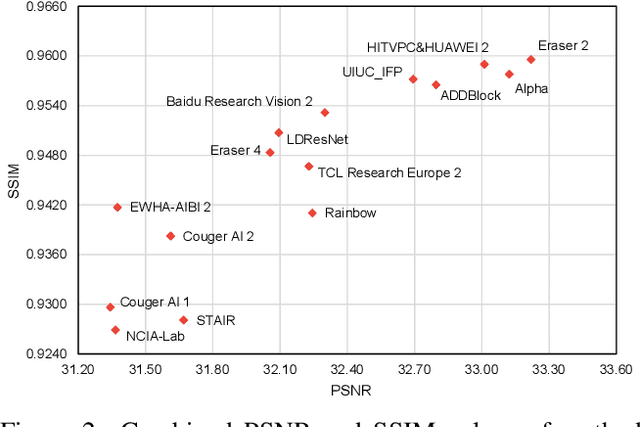
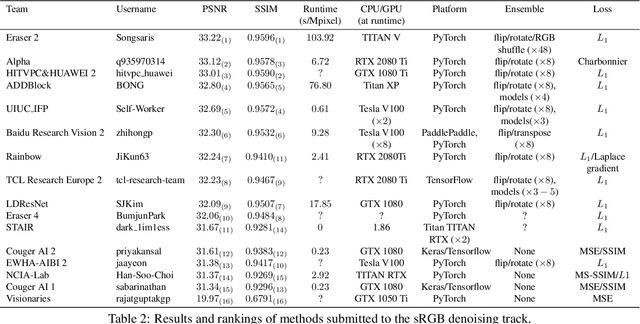
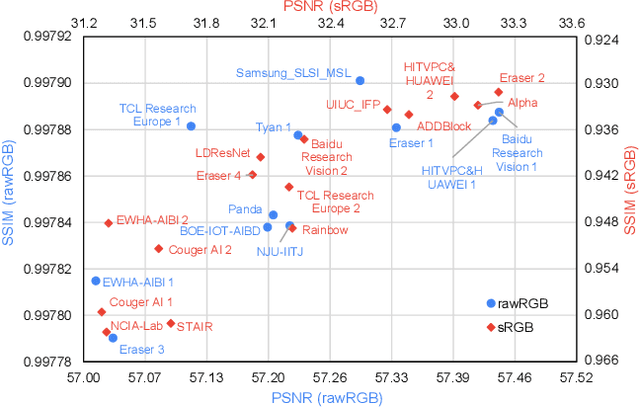
This paper reviews the NTIRE 2020 challenge on real image denoising with focus on the newly introduced dataset, the proposed methods and their results. The challenge is a new version of the previous NTIRE 2019 challenge on real image denoising that was based on the SIDD benchmark. This challenge is based on a newly collected validation and testing image datasets, and hence, named SIDD+. This challenge has two tracks for quantitatively evaluating image denoising performance in (1) the Bayer-pattern rawRGB and (2) the standard RGB (sRGB) color spaces. Each track ~250 registered participants. A total of 22 teams, proposing 24 methods, competed in the final phase of the challenge. The proposed methods by the participating teams represent the current state-of-the-art performance in image denoising targeting real noisy images. The newly collected SIDD+ datasets are publicly available at: https://bit.ly/siddplus_data.
A Large RGB-D Dataset for Semi-supervised Monocular Depth Estimation
Apr 23, 2019



The recent advance of monocular depth estimation is largely based on deeply nested convolutional networks, combined with supervised training. However, it still remains arduous to collect large-scale ground truth depth (or disparity) maps for supervising the networks. This paper presents a simple yet effective semi-supervised approach for monocular depth estimation. Inspired by the human visual system, we propose a student-teacher strategy in which a shallow student network is trained with the auxiliary information obtained from a deeper and accurate teacher network. Specifically, we first train the stereo teacher network fully utilizing the binocular perception of 3D geometry, and then use depth predictions of the teacher network for supervising the student network for monocular depth inference. This enables us to exploit all available depth data from massive unlabeled stereo pairs that are relatively easier-to-obtain. We further introduce a data ensemble strategy that merges multiple depth predictions of the teacher network to improve the training samples for the student network. Additionally, stereo confidence maps are provided to avoid inaccurate depth estimates being used when supervising the student network. Our new training data, consisting of 1 million outdoor stereo images taken using hand-held stereo cameras, is hosted at the project webpage. Lastly, we demonstrate that the monocular depth estimation network provides feature representations that are suitable for some high-level vision tasks such as semantic segmentation and road detection. Extensive experiments demonstrate the effectiveness and flexibility of the proposed method in various outdoor scenarios.
Deeply Aggregated Alternating Minimization for Image Restoration
Dec 20, 2016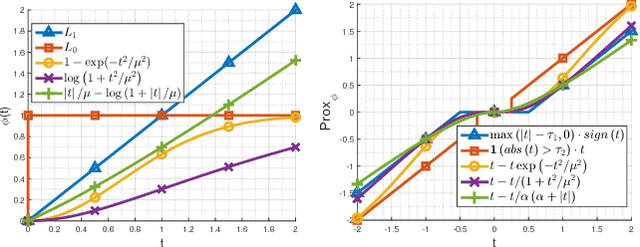
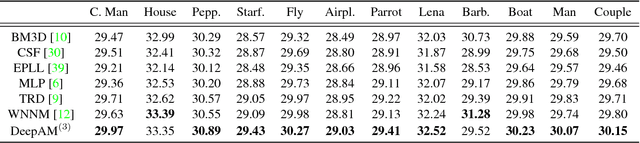

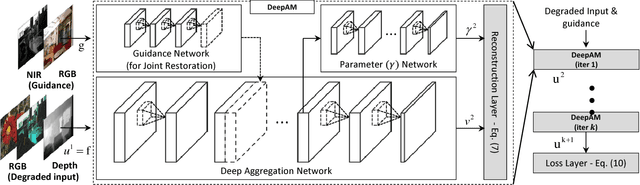
Regularization-based image restoration has remained an active research topic in computer vision and image processing. It often leverages a guidance signal captured in different fields as an additional cue. In this work, we present a general framework for image restoration, called deeply aggregated alternating minimization (DeepAM). We propose to train deep neural network to advance two of the steps in the conventional AM algorithm: proximal mapping and ?- continuation. Both steps are learned from a large dataset in an end-to-end manner. The proposed framework enables the convolutional neural networks (CNNs) to operate as a prior or regularizer in the AM algorithm. We show that our learned regularizer via deep aggregation outperforms the recent data-driven approaches as well as the nonlocalbased methods. The flexibility and effectiveness of our framework are demonstrated in several image restoration tasks, including single image denoising, RGB-NIR restoration, and depth super-resolution.
Efficient Splitting-based Method for Global Image Smoothing
Apr 26, 2016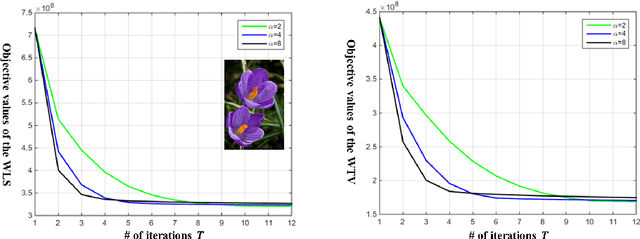

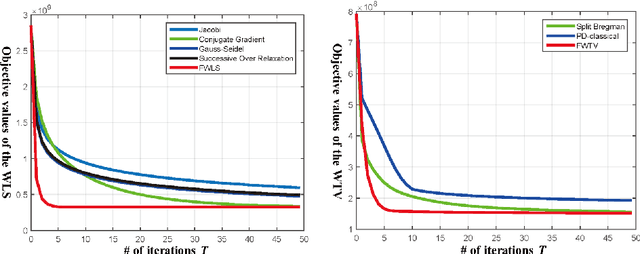
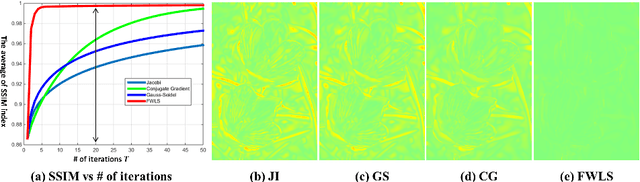
Edge-preserving smoothing (EPS) can be formulated as minimizing an objective function that consists of data and prior terms. This global EPS approach shows better smoothing performance than a local one that typically has a form of weighted averaging, at the price of high computational cost. In this paper, we introduce a highly efficient splitting-based method for global EPS that minimizes the objective function of ${l_2}$ data and prior terms (possibly non-smooth and non-convex) in linear time. Different from previous splitting-based methods that require solving a large linear system, our approach solves an equivalent constrained optimization problem, resulting in a sequence of 1D sub-problems. This enables linear time solvers for weighted-least squares and -total variation problems. Our solver converges quickly, and its runtime is even comparable to state-of-the-art local EPS approaches. We also propose a family of fast iteratively re-weighted algorithms using a non-convex prior term. Experimental results demonstrate the effectiveness and flexibility of our approach in a range of computer vision and image processing tasks.