 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWid3R: Wide Field-of-View 3D Reconstruction via Camera Model Conditioning
Feb 05, 2026We present Wid3R, a feed-forward neural network for visual geometry reconstruction that supports wide field-of-view camera models. Prior methods typically assume that input images are rectified or captured with pinhole cameras, since both their architectures and training datasets are tailored to perspective images only. These assumptions limit their applicability in real-world scenarios that use fisheye or panoramic cameras and often require careful calibration and undistortion. In contrast, Wid3R is a generalizable multi-view 3D estimation method that can model wide field-of-view camera types. Our approach leverages a ray representation with spherical harmonics and a novel camera model token within the network, enabling distortion-aware 3D reconstruction. Furthermore, Wid3R is the first multi-view foundation model to support feed-forward 3D reconstruction directly from 360 imagery. It demonstrates strong zero-shot robustness and consistently outperforms prior methods, achieving improvements of up to +77.33 on Stanford2D3D.
EDM: Equirectangular Projection-Oriented Dense Kernelized Feature Matching
Feb 28, 2025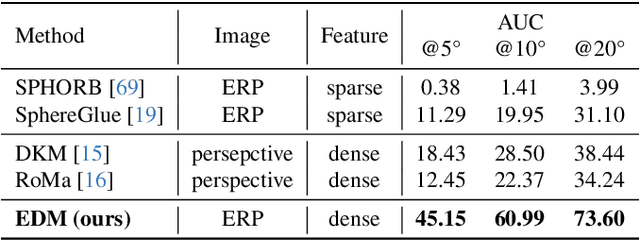
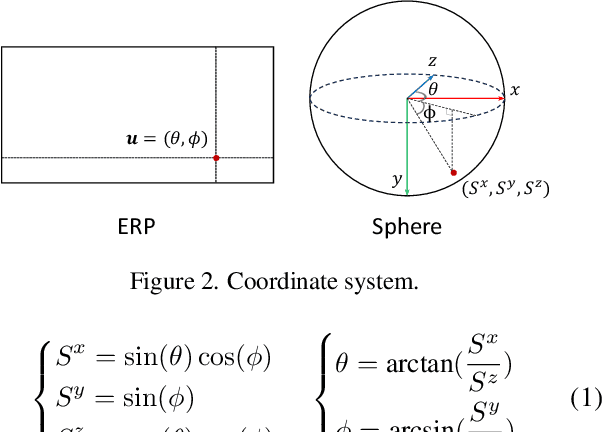
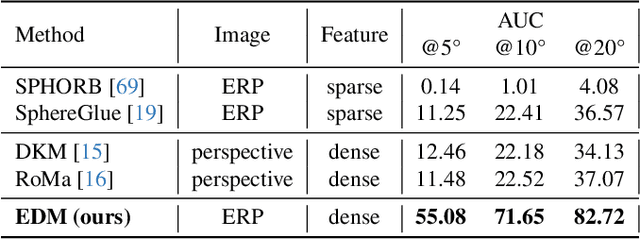

We introduce the first learning-based dense matching algorithm, termed Equirectangular Projection-Oriented Dense Kernelized Feature Matching (EDM), specifically designed for omnidirectional images. Equirectangular projection (ERP) images, with their large fields of view, are particularly suited for dense matching techniques that aim to establish comprehensive correspondences across images. However, ERP images are subject to significant distortions, which we address by leveraging the spherical camera model and geodesic flow refinement in the dense matching method. To further mitigate these distortions, we propose spherical positional embeddings based on 3D Cartesian coordinates of the feature grid. Additionally, our method incorporates bidirectional transformations between spherical and Cartesian coordinate systems during refinement, utilizing a unit sphere to improve matching performance. We demonstrate that our proposed method achieves notable performance enhancements, with improvements of +26.72 and +42.62 in AUC@5{\deg} on the Matterport3D and Stanford2D3D datasets.
EBDM: Exemplar-guided Image Translation with Brownian-bridge Diffusion Models
Oct 13, 2024Exemplar-guided image translation, synthesizing photo-realistic images that conform to both structural control and style exemplars, is attracting attention due to its ability to enhance user control over style manipulation. Previous methodologies have predominantly depended on establishing dense correspondences across cross-domain inputs. Despite these efforts, they incur quadratic memory and computational costs for establishing dense correspondence, resulting in limited versatility and performance degradation. In this paper, we propose a novel approach termed Exemplar-guided Image Translation with Brownian-Bridge Diffusion Models (EBDM). Our method formulates the task as a stochastic Brownian bridge process, a diffusion process with a fixed initial point as structure control and translates into the corresponding photo-realistic image while being conditioned solely on the given exemplar image. To efficiently guide the diffusion process toward the style of exemplar, we delineate three pivotal components: the Global Encoder, the Exemplar Network, and the Exemplar Attention Module to incorporate global and detailed texture information from exemplar images. Leveraging Bridge diffusion, the network can translate images from structure control while exclusively conditioned on the exemplar style, leading to more robust training and inference processes. We illustrate the superiority of our method over competing approaches through comprehensive benchmark evaluations and visual results.
Probabilistic Prompt Learning for Dense Prediction
Apr 03, 2023Recent progress in deterministic prompt learning has become a promising alternative to various downstream vision tasks, enabling models to learn powerful visual representations with the help of pre-trained vision-language models. However, this approach results in limited performance for dense prediction tasks that require handling more complex and diverse objects, since a single and deterministic description cannot sufficiently represent the entire image. In this paper, we present a novel probabilistic prompt learning to fully exploit the vision-language knowledge in dense prediction tasks. First, we introduce learnable class-agnostic attribute prompts to describe universal attributes across the object class. The attributes are combined with class information and visual-context knowledge to define the class-specific textual distribution. Text representations are sampled and used to guide the dense prediction task using the probabilistic pixel-text matching loss, enhancing the stability and generalization capability of the proposed method. Extensive experiments on different dense prediction tasks and ablation studies demonstrate the effectiveness of our proposed method.
Multi-domain Unsupervised Image-to-Image Translation with Appearance Adaptive Convolution
Feb 06, 2022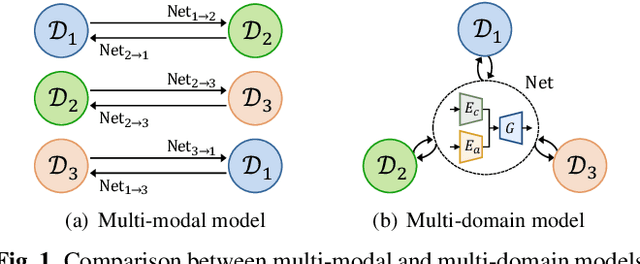
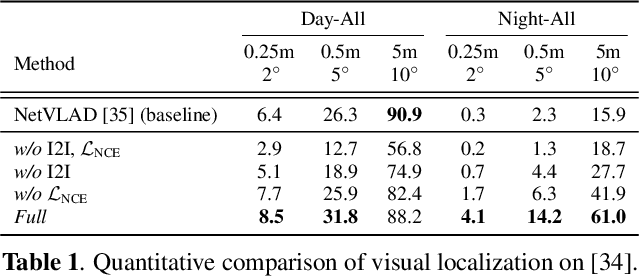
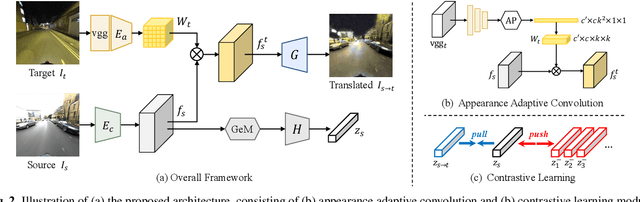

Over the past few years, image-to-image (I2I) translation methods have been proposed to translate a given image into diverse outputs. Despite the impressive results, they mainly focus on the I2I translation between two domains, so the multi-domain I2I translation still remains a challenge. To address this problem, we propose a novel multi-domain unsupervised image-to-image translation (MDUIT) framework that leverages the decomposed content feature and appearance adaptive convolution to translate an image into a target appearance while preserving the given geometric content. We also exploit a contrast learning objective, which improves the disentanglement ability and effectively utilizes multi-domain image data in the training process by pairing the semantically similar images. This allows our method to learn the diverse mappings between multiple visual domains with only a single framework. We show that the proposed method produces visually diverse and plausible results in multiple domains compared to the state-of-the-art methods.
Dual Prototypical Contrastive Learning for Few-shot Semantic Segmentation
Nov 09, 2021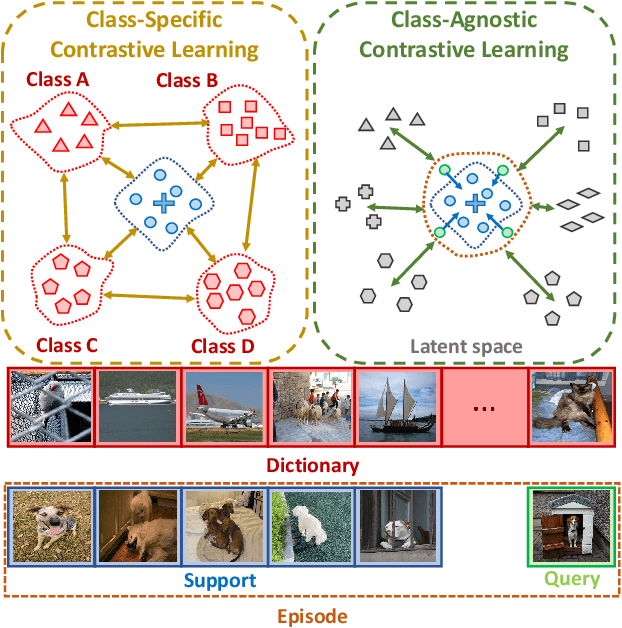
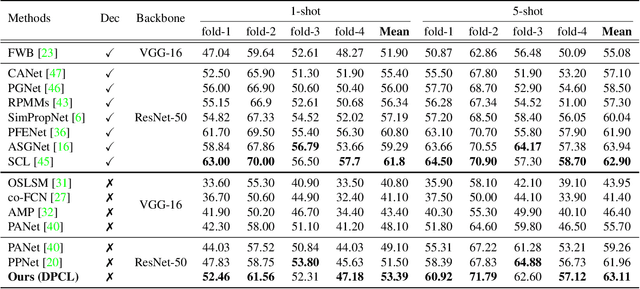
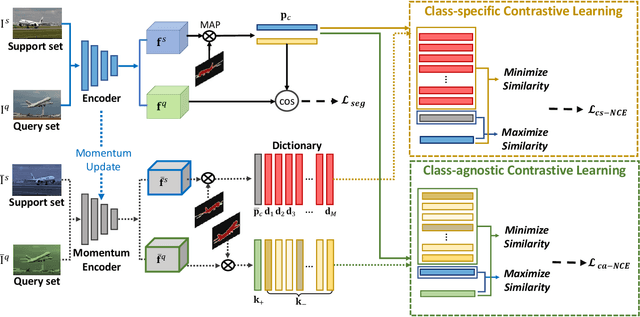

We address the problem of few-shot semantic segmentation (FSS), which aims to segment novel class objects in a target image with a few annotated samples. Though recent advances have been made by incorporating prototype-based metric learning, existing methods still show limited performance under extreme intra-class object variations and semantically similar inter-class objects due to their poor feature representation. To tackle this problem, we propose a dual prototypical contrastive learning approach tailored to the FSS task to capture the representative semanticfeatures effectively. The main idea is to encourage the prototypes more discriminative by increasing inter-class distance while reducing intra-class distance in prototype feature space. To this end, we first present a class-specific contrastive loss with a dynamic prototype dictionary that stores the class-aware prototypes during training, thus enabling the same class prototypes similar and the different class prototypes to be dissimilar. Furthermore, we introduce a class-agnostic contrastive loss to enhance the generalization ability to unseen classes by compressing the feature distribution of semantic class within each episode. We demonstrate that the proposed dual prototypical contrastive learning approach outperforms state-of-the-art FSS methods on PASCAL-5i and COCO-20i datasets. The code is available at:https://github.com/kwonjunn01/DPCL1.
Memory-guided Unsupervised Image-to-image Translation
Apr 12, 2021
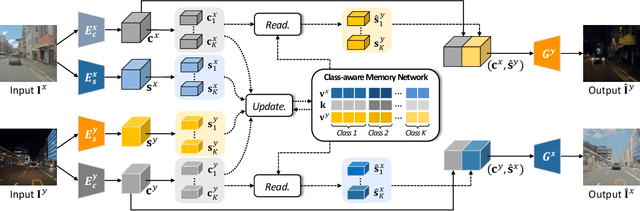
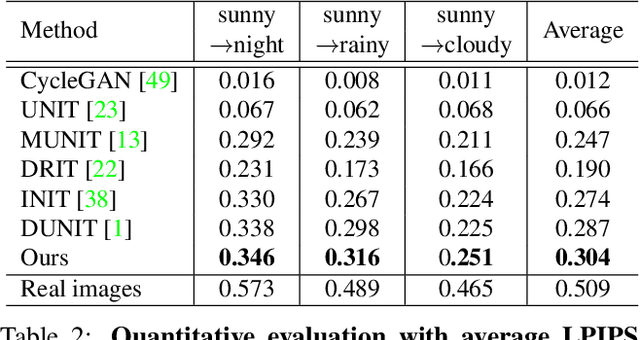
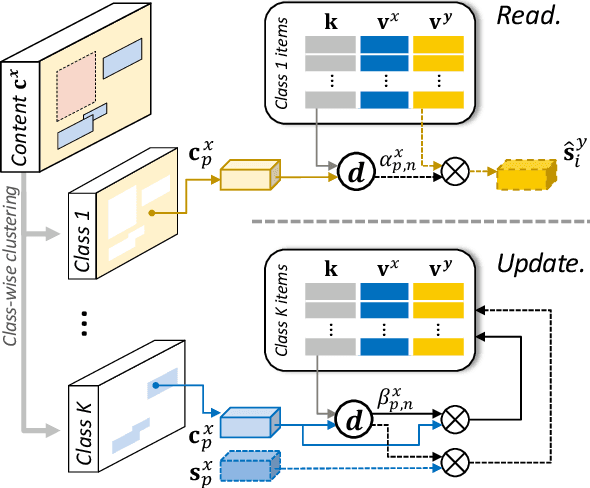
We present a novel unsupervised framework for instance-level image-to-image translation. Although recent advances have been made by incorporating additional object annotations, existing methods often fail to handle images with multiple disparate objects. The main cause is that, during inference, they apply a global style to the whole image and do not consider the large style discrepancy between instance and background, or within instances. To address this problem, we propose a class-aware memory network that explicitly reasons about local style variations. A key-values memory structure, with a set of read/update operations, is introduced to record class-wise style variations and access them without requiring an object detector at the test time. The key stores a domain-agnostic content representation for allocating memory items, while the values encode domain-specific style representations. We also present a feature contrastive loss to boost the discriminative power of memory items. We show that by incorporating our memory, we can transfer class-aware and accurate style representations across domains. Experimental results demonstrate that our model outperforms recent instance-level methods and achieves state-of-the-art performance.
Semantic Attribute Matching Networks
Apr 05, 2019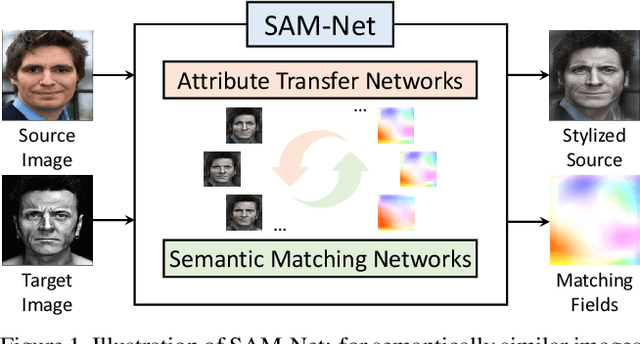
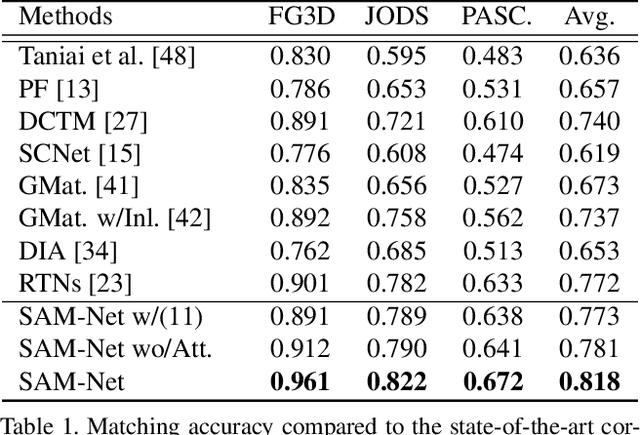
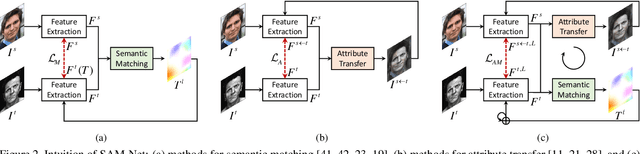
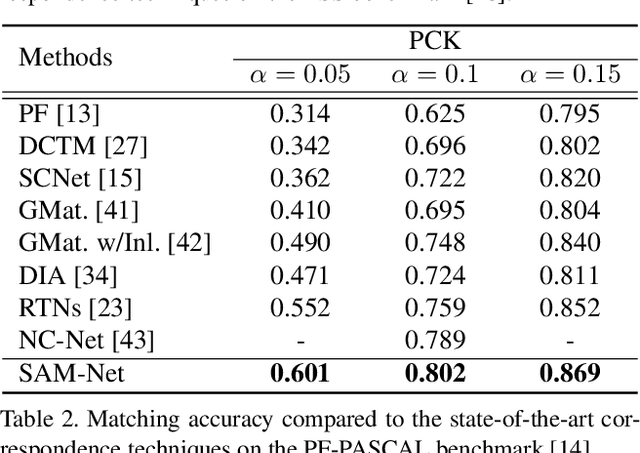
We present semantic attribute matching networks (SAM-Net) for jointly establishing correspondences and transferring attributes across semantically similar images, which intelligently weaves the advantages of the two tasks while overcoming their limitations. SAM-Net accomplishes this through an iterative process of establishing reliable correspondences by reducing the attribute discrepancy between the images and synthesizing attribute transferred images using the learned correspondences. To learn the networks using weak supervisions in the form of image pairs, we present a semantic attribute matching loss based on the matching similarity between an attribute transferred source feature and a warped target feature. With SAM-Net, the state-of-the-art performance is attained on several benchmarks for semantic matching and attribute transfer.