 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-aware Network for Aerial-to-Ground Image Synthesis
Aug 14, 2023Aerial-to-ground image synthesis is an emerging and challenging problem that aims to synthesize a ground image from an aerial image. Due to the highly different layout and object representation between the aerial and ground images, existing approaches usually fail to transfer the components of the aerial scene into the ground scene. In this paper, we propose a novel framework to explore the challenges by imposing enhanced structural alignment and semantic awareness. We introduce a novel semantic-attentive feature transformation module that allows to reconstruct the complex geographic structures by aligning the aerial feature to the ground layout. Furthermore, we propose semantic-aware loss functions by leveraging a pre-trained segmentation network. The network is enforced to synthesize realistic objects across various classes by separately calculating losses for different classes and balancing them. Extensive experiments including comparisons with previous methods and ablation studies show the effectiveness of the proposed framework both qualitatively and quantitatively.
Probabilistic Prompt Learning for Dense Prediction
Apr 03, 2023Recent progress in deterministic prompt learning has become a promising alternative to various downstream vision tasks, enabling models to learn powerful visual representations with the help of pre-trained vision-language models. However, this approach results in limited performance for dense prediction tasks that require handling more complex and diverse objects, since a single and deterministic description cannot sufficiently represent the entire image. In this paper, we present a novel probabilistic prompt learning to fully exploit the vision-language knowledge in dense prediction tasks. First, we introduce learnable class-agnostic attribute prompts to describe universal attributes across the object class. The attributes are combined with class information and visual-context knowledge to define the class-specific textual distribution. Text representations are sampled and used to guide the dense prediction task using the probabilistic pixel-text matching loss, enhancing the stability and generalization capability of the proposed method. Extensive experiments on different dense prediction tasks and ablation studies demonstrate the effectiveness of our proposed method.
Context-Preserving Instance-Level Augmentation and Deformable Convolution Networks for SAR Ship Detection
Feb 14, 2022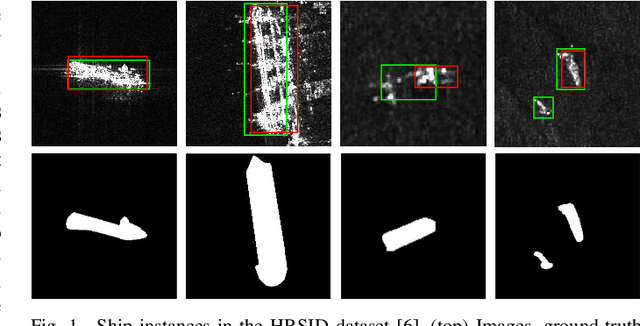

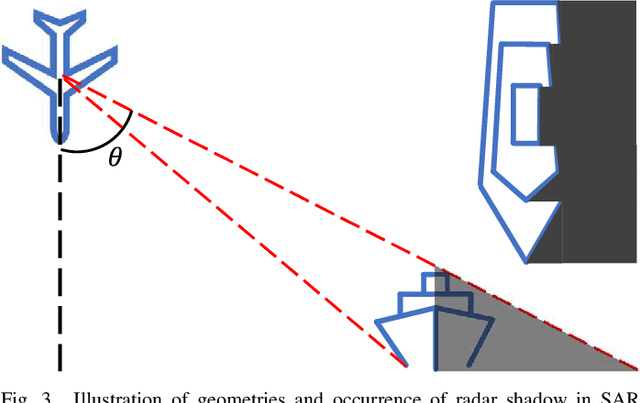

Shape deformation of targets in SAR image due to random orientation and partial information loss caused by occlusion of the radar signal, is an essential challenge in SAR ship detection. In this paper, we propose a data augmentation method to train a deep network that is robust to partial information loss within the targets. Taking advantage of ground-truth annotations for bounding box and instance segmentation mask, we present a simple and effective pipeline to simulate information loss on targets in instance-level, while preserving contextual information. Furthermore, we adopt deformable convolutional network to adaptively extract shape-invariant deep features from geometrically translated targets. By learning sampling offset to the grid of standard convolution, the network can robustly extract the features from targets with shape variations for SAR ship detection. Experiments on the HRSID dataset including comparisons with other deep networks and augmentation methods, as well as ablation study, demonstrate the effectiveness of our proposed method.