 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRTX: Efficient Ray Tracing for 3D Gaussian-Based Rendering
Jan 28, 20263D Gaussian Splatting has gained widespread adoption across diverse applications due to its exceptional rendering performance and visual quality. While most existing methods rely on rasterization to render Gaussians, recent research has started investigating ray tracing approaches to overcome the fundamental limitations inherent in rasterization. However, current Gaussian ray tracing methods suffer from inefficiencies such as bloated acceleration structures and redundant node traversals, which greatly degrade ray tracing performance. In this work, we present GRTX, a set of software and hardware optimizations that enable efficient ray tracing for 3D Gaussian-based rendering. First, we introduce a novel approach for constructing streamlined acceleration structures for Gaussian primitives. Our key insight is that anisotropic Gaussians can be treated as unit spheres through ray space transformations, which substantially reduces BVH size and traversal overhead. Second, we propose dedicated hardware support for traversal checkpointing within ray tracing units. This eliminates redundant node visits during multi-round tracing by resuming traversal from checkpointed nodes rather than restarting from the root node in each subsequent round. Our evaluation shows that GRTX significantly improves ray tracing performance compared to the baseline ray tracing method with a negligible hardware cost.
VR-Pipe: Streamlining Hardware Graphics Pipeline for Volume Rendering
Feb 24, 2025


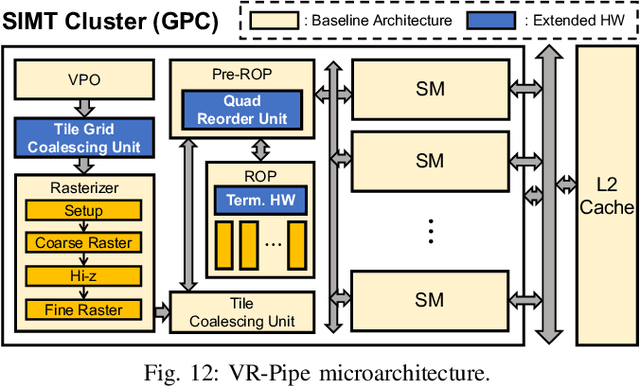
Graphics rendering that builds on machine learning and radiance fields is gaining significant attention due to its outstanding quality and speed in generating photorealistic images from novel viewpoints. However, prior work has primarily focused on evaluating its performance through software-based rendering on programmable shader cores, leaving its performance when exploiting fixed-function graphics units largely unexplored. In this paper, we investigate the performance implications of performing radiance field rendering on the hardware graphics pipeline. In doing so, we implement the state-of-the-art radiance field method, 3D Gaussian splatting, using graphics APIs and evaluate it across synthetic and real-world scenes on today's graphics hardware. Based on our analysis, we present VR-Pipe, which seamlessly integrates two innovations into graphics hardware to streamline the hardware pipeline for volume rendering, such as radiance field methods. First, we introduce native hardware support for early termination by repurposing existing special-purpose hardware in modern GPUs. Second, we propose multi-granular tile binning with quad merging, which opportunistically blends fragments in shader cores before passing them to fixed-function blending units. Our evaluation shows that VR-Pipe greatly improves rendering performance, achieving up to a 2.78x speedup over the conventional graphics pipeline with negligible hardware overhead.
InfiniGen: Efficient Generative Inference of Large Language Models with Dynamic KV Cache Management
Jun 28, 2024Transformer-based large language models (LLMs) demonstrate impressive performance across various natural language processing tasks. Serving LLM inference for generating long contents, however, poses a challenge due to the enormous memory footprint of the transient state, known as the key-value (KV) cache, which scales with the sequence length and batch size. In this paper, we present InfiniGen, a novel KV cache management framework tailored for long-text generation, which synergistically works with modern offloading-based inference systems. InfiniGen leverages the key insight that a few important tokens that are essential for computing the subsequent attention layer in the Transformer can be speculated by performing a minimal rehearsal with the inputs of the current layer and part of the query weight and key cache of the subsequent layer. This allows us to prefetch only the essential KV cache entries (without fetching them all), thereby mitigating the fetch overhead from the host memory in offloading-based LLM serving systems. Our evaluation on several representative LLMs shows that InfiniGen improves the overall performance of a modern offloading-based system by up to 3.00x compared to prior KV cache management methods while offering substantially better model accuracy.
Tender: Accelerating Large Language Models via Tensor Decomposition and Runtime Requantization
Jun 16, 2024Large language models (LLMs) demonstrate outstanding performance in various tasks in machine learning and have thus become one of the most important workloads in today's computing landscape. However, deploying LLM inference poses challenges due to the high compute and memory requirements stemming from the enormous model size and the difficulty of running it in the integer pipelines. In this paper, we present Tender, an algorithm-hardware co-design solution that enables efficient deployment of LLM inference at low precision. Based on our analysis of outlier values in LLMs, we propose a decomposed quantization technique in which the scale factors of decomposed matrices are powers of two apart. The proposed scheme allows us to avoid explicit requantization (i.e., dequantization/quantization) when accumulating the partial sums from the decomposed matrices, with a minimal extension to the commodity tensor compute hardware. Our evaluation shows that Tender achieves higher accuracy and inference performance compared to the state-of-the-art methods while also being significantly less intrusive to the existing accelerators.
MoNDE: Mixture of Near-Data Experts for Large-Scale Sparse Models
May 29, 2024Mixture-of-Experts (MoE) large language models (LLM) have memory requirements that often exceed the GPU memory capacity, requiring costly parameter movement from secondary memories to the GPU for expert computation. In this work, we present Mixture of Near-Data Experts (MoNDE), a near-data computing solution that efficiently enables MoE LLM inference. MoNDE reduces the volume of MoE parameter movement by transferring only the $\textit{hot}$ experts to the GPU, while computing the remaining $\textit{cold}$ experts inside the host memory device. By replacing the transfers of massive expert parameters with the ones of small activations, MoNDE enables far more communication-efficient MoE inference, thereby resulting in substantial speedups over the existing parameter offloading frameworks for both encoder and decoder operations.