 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplete Gaussian Splats from a Single Image with Denoising Diffusion Models
Aug 29, 2025Gaussian splatting typically requires dense observations of the scene and can fail to reconstruct occluded and unobserved areas. We propose a latent diffusion model to reconstruct a complete 3D scene with Gaussian splats, including the occluded parts, from only a single image during inference. Completing the unobserved surfaces of a scene is challenging due to the ambiguity of the plausible surfaces. Conventional methods use a regression-based formulation to predict a single "mode" for occluded and out-of-frustum surfaces, leading to blurriness, implausibility, and failure to capture multiple possible explanations. Thus, they often address this problem partially, focusing either on objects isolated from the background, reconstructing only visible surfaces, or failing to extrapolate far from the input views. In contrast, we propose a generative formulation to learn a distribution of 3D representations of Gaussian splats conditioned on a single input image. To address the lack of ground-truth training data, we propose a Variational AutoReconstructor to learn a latent space only from 2D images in a self-supervised manner, over which a diffusion model is trained. Our method generates faithful reconstructions and diverse samples with the ability to complete the occluded surfaces for high-quality 360-degree renderings.
Toward General Object-level Mapping from Sparse Views with 3D Diffusion Priors
Oct 07, 2024Object-level mapping builds a 3D map of objects in a scene with detailed shapes and poses from multi-view sensor observations. Conventional methods struggle to build complete shapes and estimate accurate poses due to partial occlusions and sensor noise. They require dense observations to cover all objects, which is challenging to achieve in robotics trajectories. Recent work introduces generative shape priors for object-level mapping from sparse views, but is limited to single-category objects. In this work, we propose a General Object-level Mapping system, GOM, which leverages a 3D diffusion model as shape prior with multi-category support and outputs Neural Radiance Fields (NeRFs) for both texture and geometry for all objects in a scene. GOM includes an effective formulation to guide a pre-trained diffusion model with extra nonlinear constraints from sensor measurements without finetuning. We also develop a probabilistic optimization formulation to fuse multi-view sensor observations and diffusion priors for joint 3D object pose and shape estimation. Our GOM system demonstrates superior multi-category mapping performance from sparse views, and achieves more accurate mapping results compared to state-of-the-art methods on the real-world benchmarks. We will release our code: https://github.com/TRAILab/GeneralObjectMapping.
Multiple View Geometry Transformers for 3D Human Pose Estimation
Nov 18, 2023



In this work, we aim to improve the 3D reasoning ability of Transformers in multi-view 3D human pose estimation. Recent works have focused on end-to-end learning-based transformer designs, which struggle to resolve geometric information accurately, particularly during occlusion. Instead, we propose a novel hybrid model, MVGFormer, which has a series of geometric and appearance modules organized in an iterative manner. The geometry modules are learning-free and handle all viewpoint-dependent 3D tasks geometrically which notably improves the model's generalization ability. The appearance modules are learnable and are dedicated to estimating 2D poses from image signals end-to-end which enables them to achieve accurate estimates even when occlusion occurs, leading to a model that is both accurate and generalizable to new cameras and geometries. We evaluate our approach for both in-domain and out-of-domain settings, where our model consistently outperforms state-of-the-art methods, and especially does so by a significant margin in the out-of-domain setting. We will release the code and models: https://github.com/XunshanMan/MVGFormer.
Uncertainty-aware 3D Object-Level Mapping with Deep Shape Priors
Sep 17, 2023
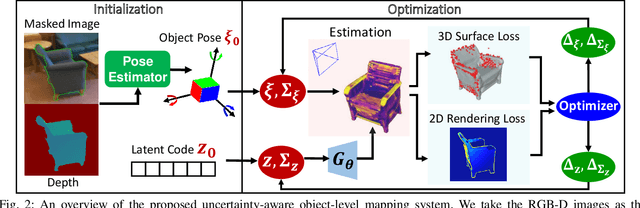
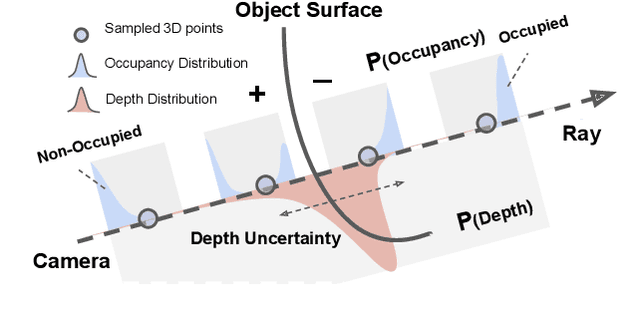

3D object-level mapping is a fundamental problem in robotics, which is especially challenging when object CAD models are unavailable during inference. In this work, we propose a framework that can reconstruct high-quality object-level maps for unknown objects. Our approach takes multiple RGB-D images as input and outputs dense 3D shapes and 9-DoF poses (including 3 scale parameters) for detected objects. The core idea of our approach is to leverage a learnt generative model for shape categories as a prior and to formulate a probabilistic, uncertainty-aware optimization framework for 3D reconstruction. We derive a probabilistic formulation that propagates shape and pose uncertainty through two novel loss functions. Unlike current state-of-the-art approaches, we explicitly model the uncertainty of the object shapes and poses during our optimization, resulting in a high-quality object-level mapping system. Moreover, the resulting shape and pose uncertainties, which we demonstrate can accurately reflect the true errors of our object maps, can also be useful for downstream robotics tasks such as active vision. We perform extensive evaluations on indoor and outdoor real-world datasets, achieving achieves substantial improvements over state-of-the-art methods. Our code will be available at https://github.com/TRAILab/UncertainShapePose.
Multi-view 3D Object Reconstruction and Uncertainty Modelling with Neural Shape Prior
Jun 17, 2023
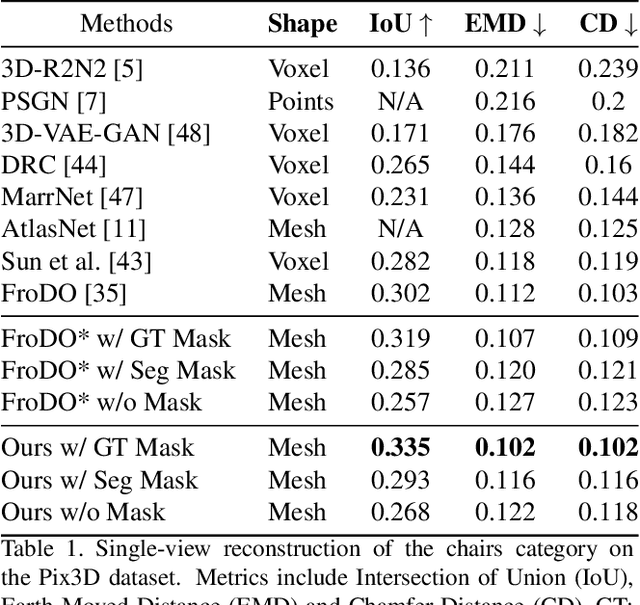


3D object reconstruction is important for semantic scene understanding. It is challenging to reconstruct detailed 3D shapes from monocular images directly due to a lack of depth information, occlusion and noise. Most current methods generate deterministic object models without any awareness of the uncertainty of the reconstruction. We tackle this problem by leveraging a neural object representation which learns an object shape distribution from large dataset of 3d object models and maps it into a latent space. We propose a method to model uncertainty as part of the representation and define an uncertainty-aware encoder which generates latent codes with uncertainty directly from individual input images. Further, we propose a method to propagate the uncertainty in the latent code to SDF values and generate a 3d object mesh with local uncertainty for each mesh component. Finally, we propose an incremental fusion method under a Bayesian framework to fuse the latent codes from multi-view observations. We evaluate the system in both synthetic and real datasets to demonstrate the effectiveness of uncertainty-based fusion to improve 3D object reconstruction accuracy.
SO-SLAM: Semantic Object SLAM with Scale Proportional and Symmetrical Texture Constraints
Sep 10, 2021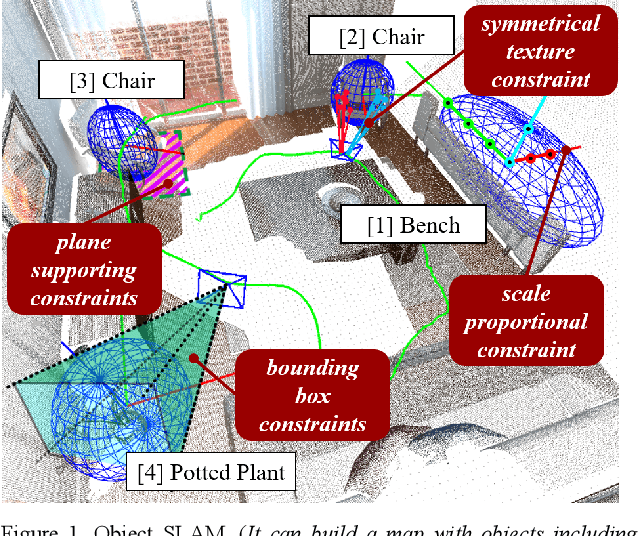
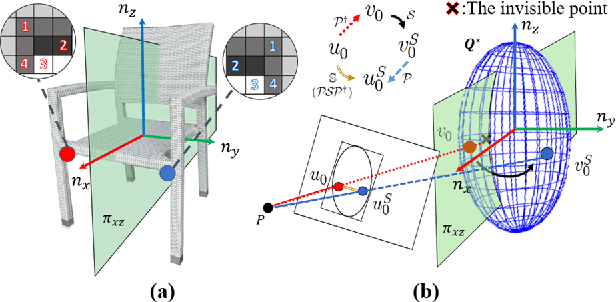
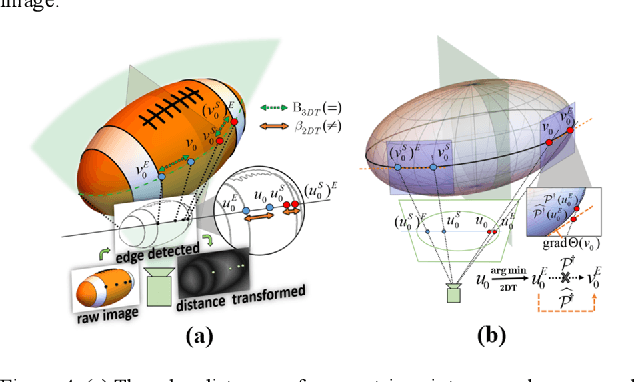
Object SLAM introduces the concept of objects into Simultaneous Localization and Mapping (SLAM) and helps understand indoor scenes for mobile robots and object-level interactive applications. The state-of-art object SLAM systems face challenges such as partial observations, occlusions, unobservable problems, limiting the mapping accuracy and robustness. This paper proposes a novel monocular Semantic Object SLAM (SO-SLAM) system that addresses the introduction of object spatial constraints. We explore three representative spatial constraints, including scale proportional constraint, symmetrical texture constraint and plane supporting constraint. Based on these semantic constraints, we propose two new methods - a more robust object initialization method and an orientation fine optimization method. We have verified the performance of the algorithm on the public datasets and an author-recorded mobile robot dataset and achieved a significant improvement on mapping effects. We will release the code here: https://github.com/XunshanMan/SoSLAM.
Stereo Plane SLAM Based on Intersecting Lines
Aug 19, 2020

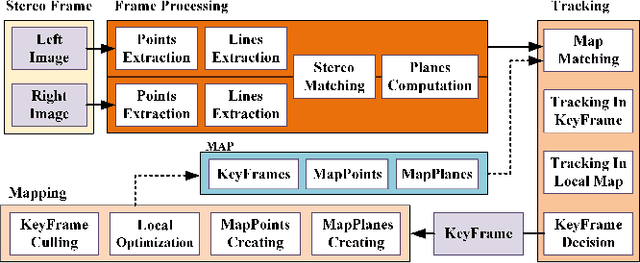

Plane feature is a kind of stable landmark to reduce drift error in SLAM system. It is easy and fast to extract planes from dense point cloud, which is commonly acquired from RGB-D camera or lidar. But for stereo camera, it is hard to compute dense point cloud accurately and efficiently. In this paper, we propose a novel method to compute plane parameters from intersecting lines extracted for stereo image. The plane features commonly exist on the surface of man-made objects and structure, which have regular shape and straight edge lines. In 3D space, two intersecting lines can determine such a plane. Thus we extract line segments from both stereo left and right image. By stereo matching, we compute the endpoints and line directions in 3D space, and then the planes can be computed. Adding such computed plane features in stereo SLAM system reduces the drift error and refines the performance. We test our proposed system on public datasets and demonstrate its robust and accurate estimation results, compared with state-of-the-art SLAM systems.
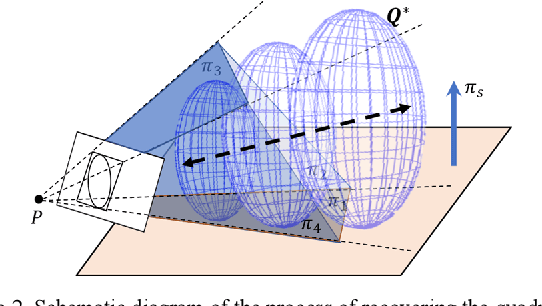
Object-oriented SLAM using Quadrics and Symmetry Properties for Indoor Environments
Apr 11, 2020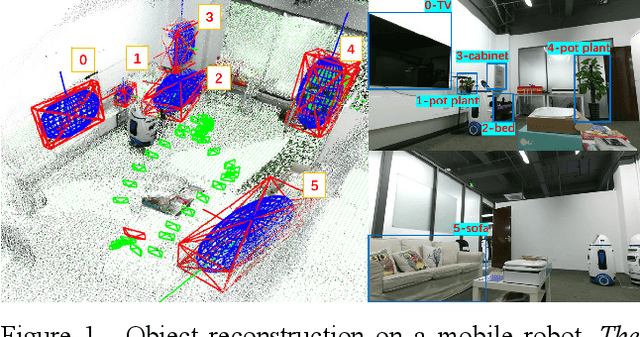

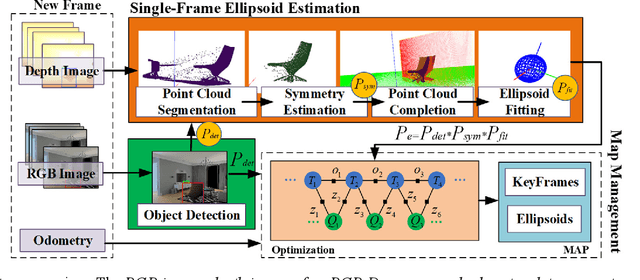
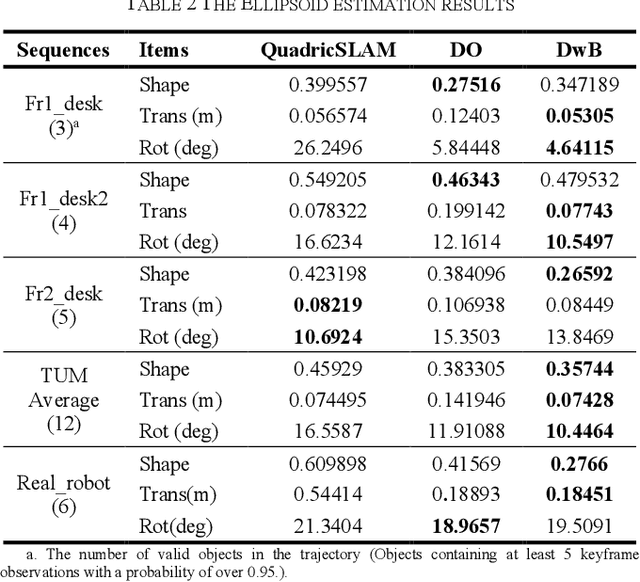
Aiming at the application environment of indoor mobile robots, this paper proposes a sparse object-level SLAM algorithm based on an RGB-D camera. A quadric representation is used as a landmark to compactly model objects, including their position, orientation, and occupied space. The state-of-art quadric-based SLAM algorithm faces the observability problem caused by the limited perspective under the plane trajectory of the mobile robot. To solve the problem, the proposed algorithm fuses both object detection and point cloud data to estimate the quadric parameters. It finishes the quadric initialization based on a single frame of RGB-D data, which significantly reduces the requirements for perspective changes. As objects are often observed locally, the proposed algorithm uses the symmetrical properties of indoor artificial objects to estimate the occluded parts to obtain more accurate quadric parameters. Experiments have shown that compared with the state-of-art algorithm, especially on the forward trajectory of mobile robots, the proposed algorithm significantly improves the accuracy and convergence speed of quadric reconstruction. Finally, we made available an opensource implementation to replicate the experiments.
Coarse-To-Fine Visual Localization Using Semantic Compact Map
Oct 17, 2019
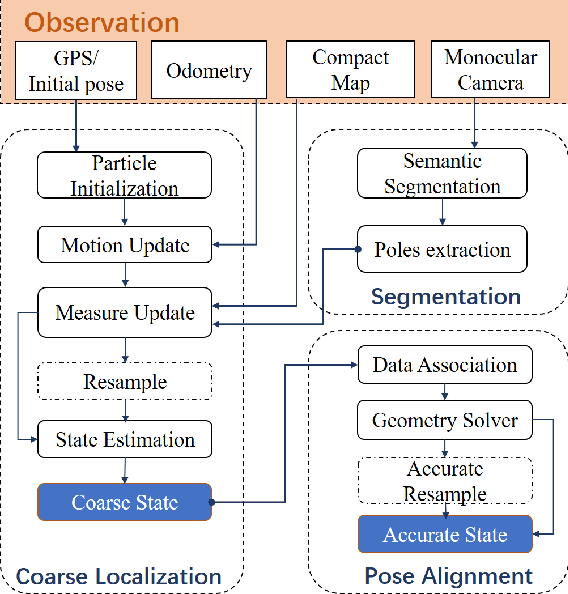
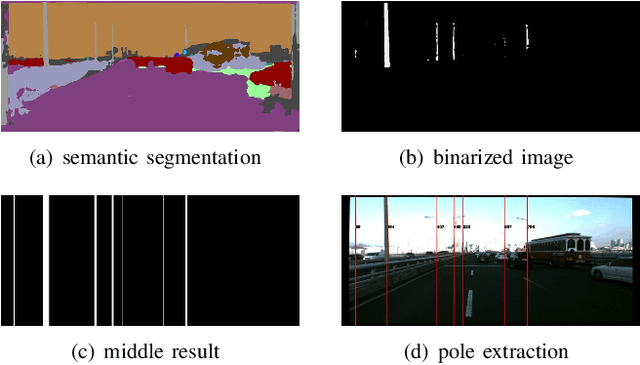
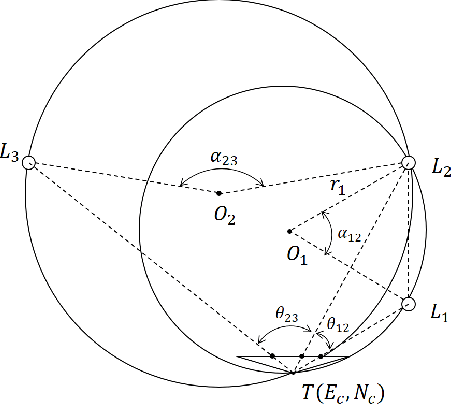
Robust visual localization for urban vehicles remains challenging and unsolved. The limitation of computation efficiency and memory size has made it harder for large-scale applications. Since semantic information serves as a stable and compact representation of the environment, we propose a coarse-to-fine localization system based on a semantic compact map. Pole-like objects are stored in the compact map, then are extracted from semantically segmented images as observations. Localization is performed by a particle filter, followed by a pose alignment module decoupling translation and rotation to achieve better accuracy. We evaluate our system both on synthetic and realistic datasets and compare it with two baselines, a state-of-art semantic feature-based system and a traditional SIFT feature-based system. Experiments demonstrate that even with a significantly small map, such as a 10 KB map for a 3.7 km long trajectory, our system provides a comparable accuracy with the baselines.