 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeteorPred: A Meteorological Multimodal Large Model and Dataset for Severe Weather Event Prediction
Aug 09, 2025Timely and accurate severe weather warnings are critical for disaster mitigation. However, current forecasting systems remain heavily reliant on manual expert interpretation, introducing subjectivity and significant operational burdens. With the rapid development of AI technologies, the end-to-end "AI weather station" is gradually emerging as a new trend in predicting severe weather events. Three core challenges impede the development of end-to-end AI severe weather system: (1) scarcity of severe weather event samples; (2) imperfect alignment between high-dimensional meteorological data and textual warnings; (3) existing multimodal language models are unable to handle high-dimensional meteorological data and struggle to fully capture the complex dependencies across temporal sequences, vertical pressure levels, and spatial dimensions. To address these challenges, we introduce MP-Bench, the first large-scale temporal multimodal dataset for severe weather events prediction, comprising 421,363 pairs of raw multi-year meteorological data and corresponding text caption, covering a wide range of severe weather scenarios across China. On top of this dataset, we develop a meteorology multimodal large model (MMLM) that directly ingests 4D meteorological inputs. In addition, it is designed to accommodate the unique characteristics of 4D meteorological data flow, incorporating three plug-and-play adaptive fusion modules that enable dynamic feature extraction and integration across temporal sequences, vertical pressure layers, and spatial dimensions. Extensive experiments on MP-Bench demonstrate that MMLM performs exceptionally well across multiple tasks, highlighting its effectiveness in severe weather understanding and marking a key step toward realizing automated, AI-driven weather forecasting systems. Our source code and dataset will be made publicly available.
Hardware Architecture Design of Model-Based Image Reconstruction Towards Palm-size Photoacoustic Tomography
Aug 12, 2024



Photoacoustic (PA) imaging technology combines the advantages of optical imaging and ultrasound imaging, showing great potential in biomedical applications. Many preclinical studies and clinical applications urgently require fast, high-quality, low-cost and portable imaging system. Translating advanced image reconstruction algorithms into hardware implementations is highly desired. However, existing iterative PA image reconstructions, although exhibit higher accuracy than delay-and-sum algorithm, suffer from high computational cost. In this paper, we introduce a model-based hardware acceleration architecture based on superposed Wave (s-Wave) for palm-size PA tomography (palm-PAT), aiming at enhancing both the speed and performance of image reconstruction at a much lower system cost. To achieve this, we propose an innovative data reuse method that significantly reduces hardware storage resource consumption. We conducted experiments by FPGA implementation of the algorithm, using both phantoms and in vivo human finger data to verify the feasibility of the proposed method. The results demonstrate that our proposed architecture can substantially reduce system cost while maintaining high imaging performance. The hardware-accelerated implementation of the model-based algorithm achieves a speedup of up to approximately 270 times compared to the CPU, while the corresponding energy efficiency ratio is improved by more than 2700 times.
Prototype Learning Guided Hybrid Network for Breast Tumor Segmentation in DCE-MRI
Aug 11, 2024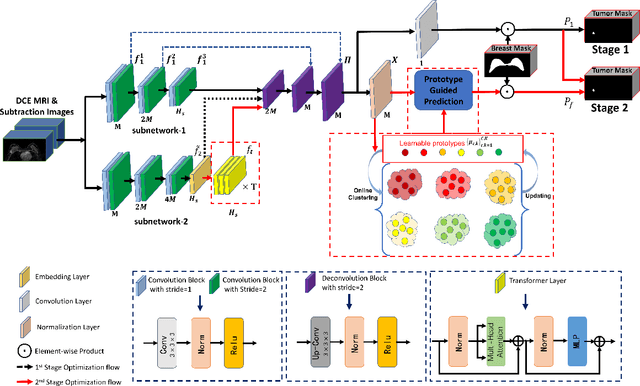
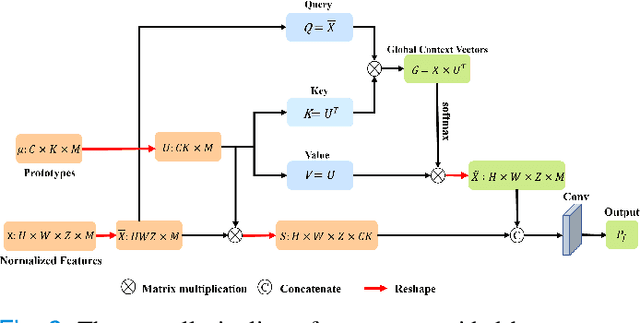
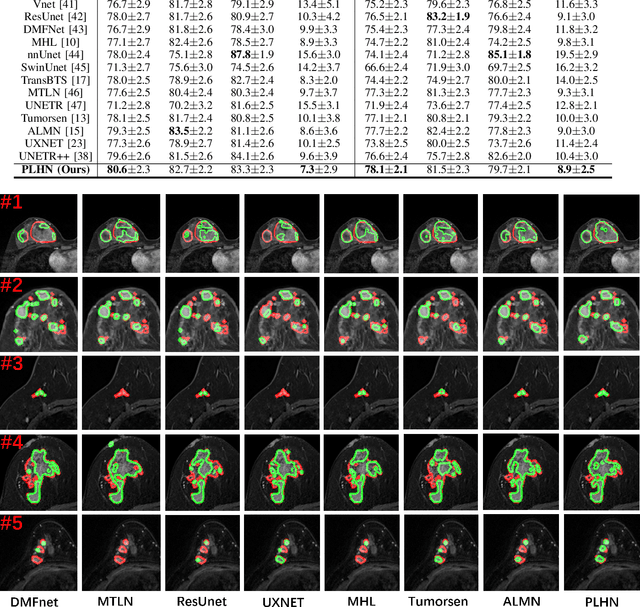
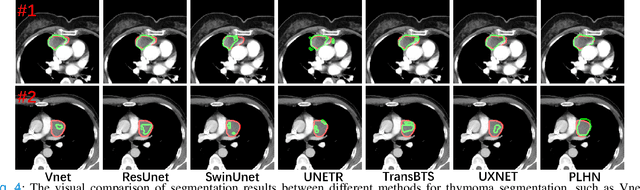
Automated breast tumor segmentation on the basis of dynamic contrast-enhancement magnetic resonance imaging (DCE-MRI) has shown great promise in clinical practice, particularly for identifying the presence of breast disease. However, accurate segmentation of breast tumor is a challenging task, often necessitating the development of complex networks. To strike an optimal trade-off between computational costs and segmentation performance, we propose a hybrid network via the combination of convolution neural network (CNN) and transformer layers. Specifically, the hybrid network consists of a encoder-decoder architecture by stacking convolution and decovolution layers. Effective 3D transformer layers are then implemented after the encoder subnetworks, to capture global dependencies between the bottleneck features. To improve the efficiency of hybrid network, two parallel encoder subnetworks are designed for the decoder and the transformer layers, respectively. To further enhance the discriminative capability of hybrid network, a prototype learning guided prediction module is proposed, where the category-specified prototypical features are calculated through on-line clustering. All learned prototypical features are finally combined with the features from decoder for tumor mask prediction. The experimental results on private and public DCE-MRI datasets demonstrate that the proposed hybrid network achieves superior performance than the state-of-the-art (SOTA) methods, while maintaining balance between segmentation accuracy and computation cost. Moreover, we demonstrate that automatically generated tumor masks can be effectively applied to identify HER2-positive subtype from HER2-negative subtype with the similar accuracy to the analysis based on manual tumor segmentation. The source code is available at https://github.com/ZhouL-lab/PLHN.
Multi-View Vertebra Localization and Identification from CT Images
Jul 24, 2023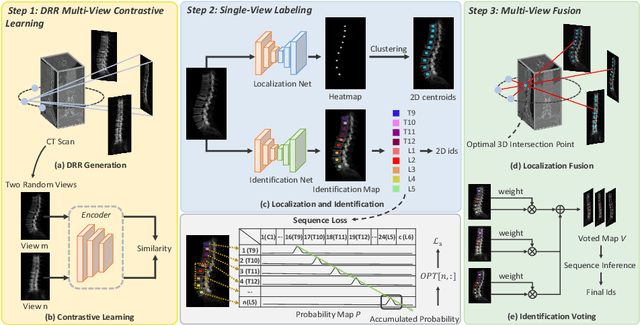
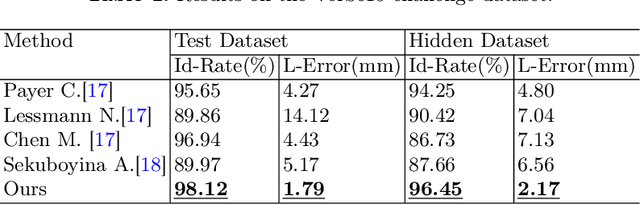
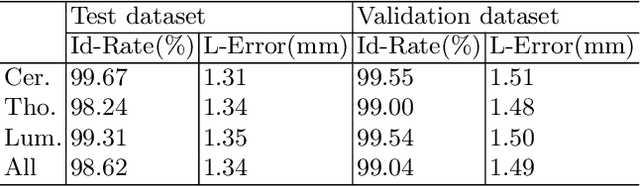
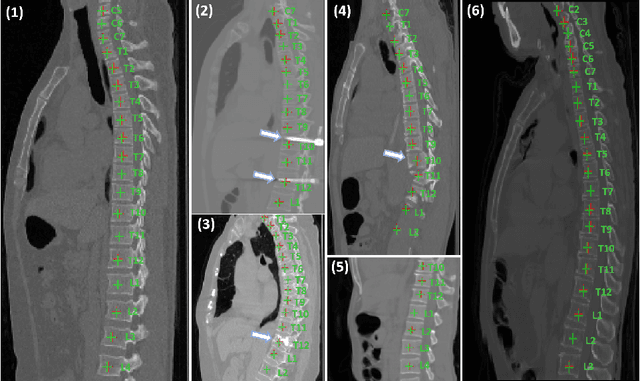
Accurately localizing and identifying vertebrae from CT images is crucial for various clinical applications. However, most existing efforts are performed on 3D with cropping patch operation, suffering from the large computation costs and limited global information. In this paper, we propose a multi-view vertebra localization and identification from CT images, converting the 3D problem into a 2D localization and identification task on different views. Without the limitation of the 3D cropped patch, our method can learn the multi-view global information naturally. Moreover, to better capture the anatomical structure information from different view perspectives, a multi-view contrastive learning strategy is developed to pre-train the backbone. Additionally, we further propose a Sequence Loss to maintain the sequential structure embedded along the vertebrae. Evaluation results demonstrate that, with only two 2D networks, our method can localize and identify vertebrae in CT images accurately, and outperforms the state-of-the-art methods consistently. Our code is available at https://github.com/ShanghaiTech-IMPACT/Multi-View-Vertebra-Localization-and-Identification-from-CT-Images.
Photoacoustic digital brain: numerical modelling and image reconstruction via deep learning
Sep 19, 2021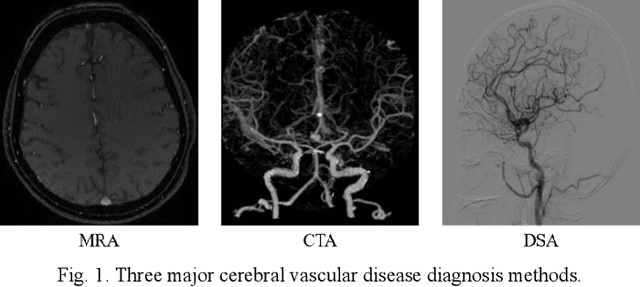
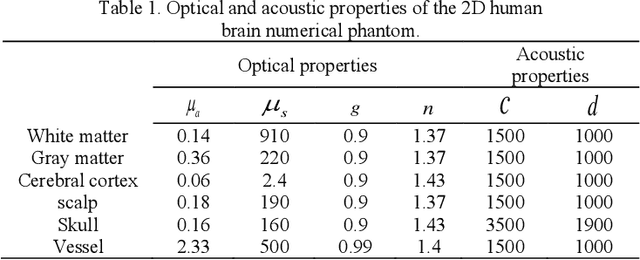
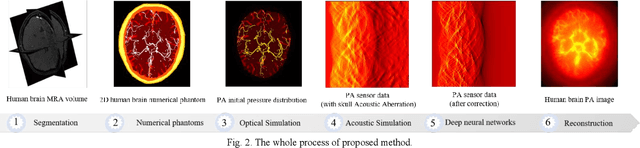
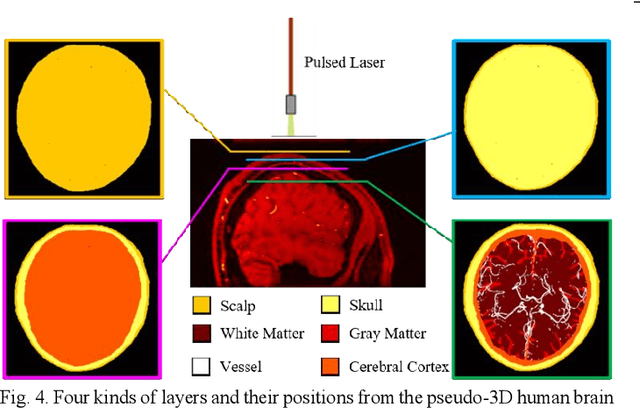
Photoacoustic tomography (PAT) is a newly developed medical imaging modality, which combines the advantages of pure optical imaging and ultrasound imaging, owning both high optical contrast and deep penetration depth. Very recently, PAT is studied in human brain imaging. Nevertheless, while ultrasound waves are passing through the human skull tissues, the strong acoustic attenuation and aberration will happen, which causes photoacoustic signals' distortion. In this work, we use 10 magnetic resonance angiography (MRA) human brain volumes, and manually segment them to obtain the 2D human brain numerical phantoms for PAT. The numerical phantoms contain six kinds of tissues which are scalp, skull, white matter, gray matter, blood vessel and cerebral cortex. For every numerical phantom, optical properties are assigned to every kind of tissues. Then, Monte-Carlo based optical simulation is deployed to obtain the photoacoustic initial pressure. Then, we made two k-wave simulation cases: one takes inhomogeneous medium and uneven sound velocity into consideration, and the other not. Then we use the sensor data of the former one as the input of U-net, and the sensor data of the latter one as the output of U-net to train the network. We randomly choose 7 human brain PA sinograms as the training dataset and 3 human brain PA sinograms as the testing set. The testing result shows that our method could correct the skull acoustic aberration and obtain the blood vessel distribution inside the human brain satisfactorily.
SO-SLAM: Semantic Object SLAM with Scale Proportional and Symmetrical Texture Constraints
Sep 10, 2021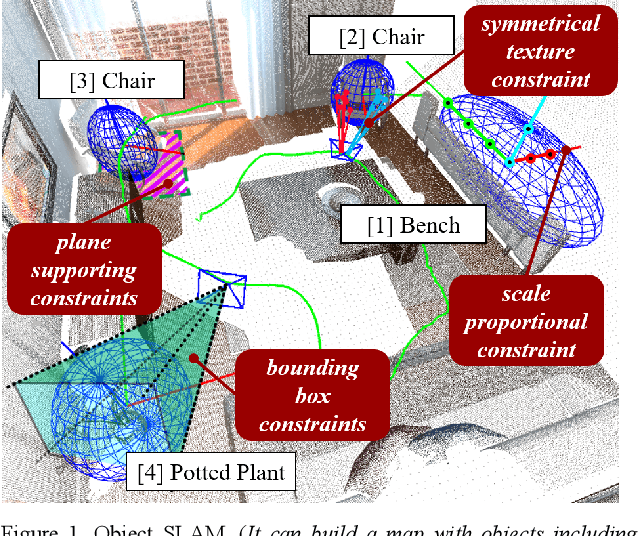
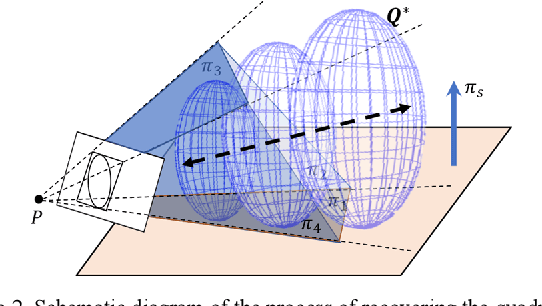
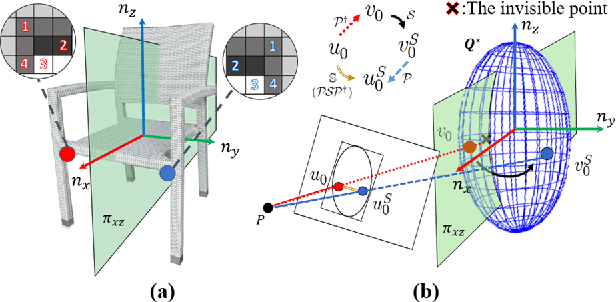
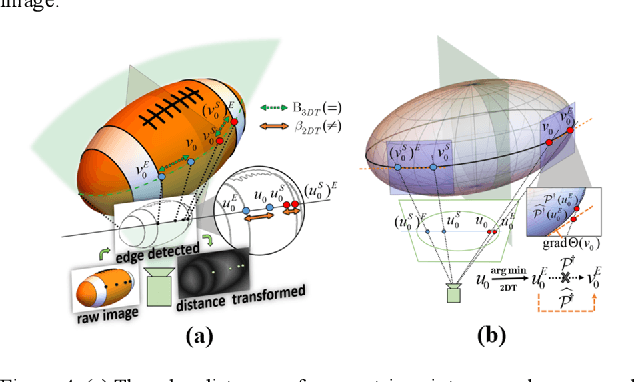
Object SLAM introduces the concept of objects into Simultaneous Localization and Mapping (SLAM) and helps understand indoor scenes for mobile robots and object-level interactive applications. The state-of-art object SLAM systems face challenges such as partial observations, occlusions, unobservable problems, limiting the mapping accuracy and robustness. This paper proposes a novel monocular Semantic Object SLAM (SO-SLAM) system that addresses the introduction of object spatial constraints. We explore three representative spatial constraints, including scale proportional constraint, symmetrical texture constraint and plane supporting constraint. Based on these semantic constraints, we propose two new methods - a more robust object initialization method and an orientation fine optimization method. We have verified the performance of the algorithm on the public datasets and an author-recorded mobile robot dataset and achieved a significant improvement on mapping effects. We will release the code here: https://github.com/XunshanMan/SoSLAM.