 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowdDriven: A New Challenging Dataset for Outdoor Visual Localization
Sep 09, 2021
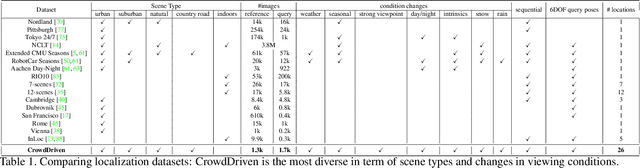

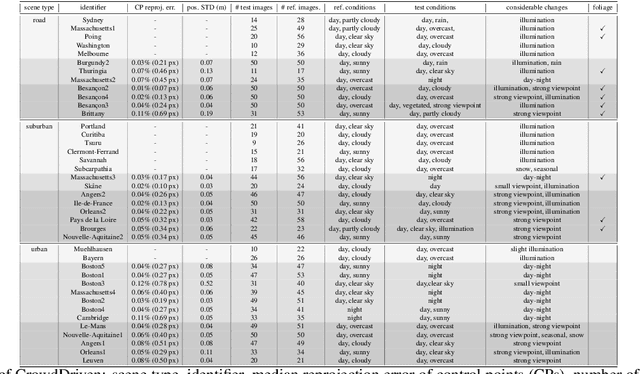
Visual localization is the problem of estimating the position and orientation from which a given image (or a sequence of images) is taken in a known scene. It is an important part of a wide range of computer vision and robotics applications, from self-driving cars to augmented/virtual reality systems. Visual localization techniques should work reliably and robustly under a wide range of conditions, including seasonal, weather, illumination and man-made changes. Recent benchmarking efforts model this by providing images under different conditions, and the community has made rapid progress on these datasets since their inception. However, they are limited to a few geographical regions and often recorded with a single device. We propose a new benchmark for visual localization in outdoor scenes, using crowd-sourced data to cover a wide range of geographical regions and camera devices with a focus on the failure cases of current algorithms. Experiments with state-of-the-art localization approaches show that our dataset is very challenging, with all evaluated methods failing on its hardest parts. As part of the dataset release, we provide the tooling used to generate it, enabling efficient and effective 2D correspondence annotation to obtain reference poses.
Back to the Feature: Learning Robust Camera Localization from Pixels to Pose
Apr 07, 2021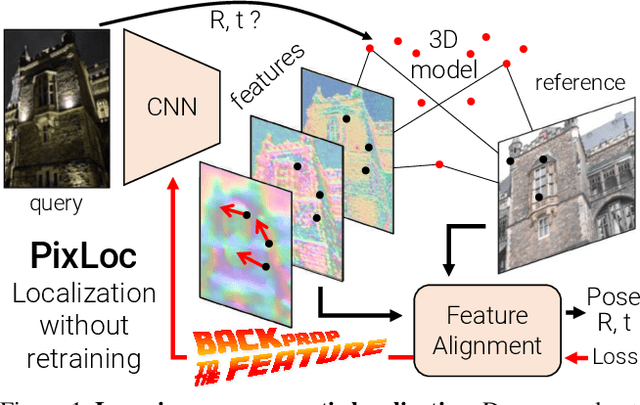
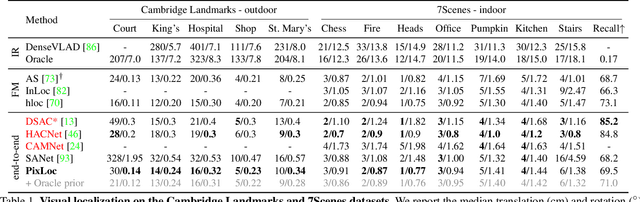
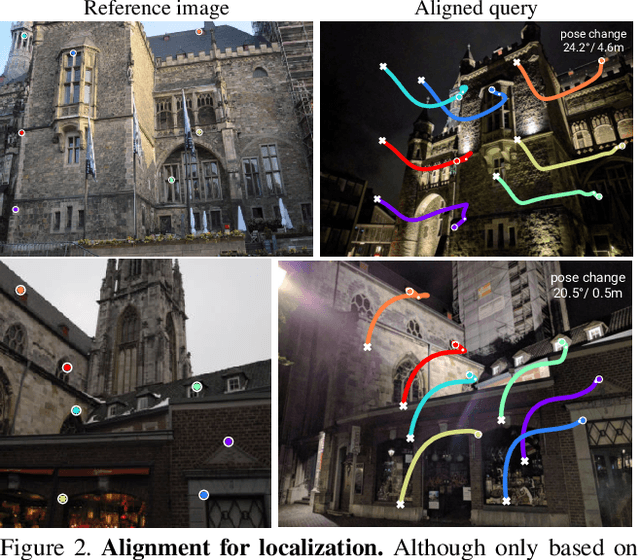
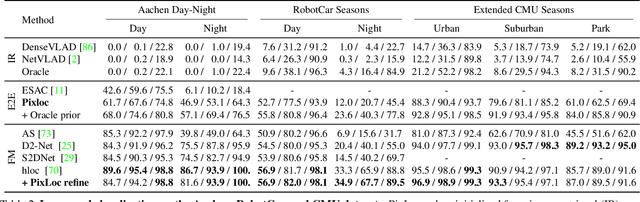
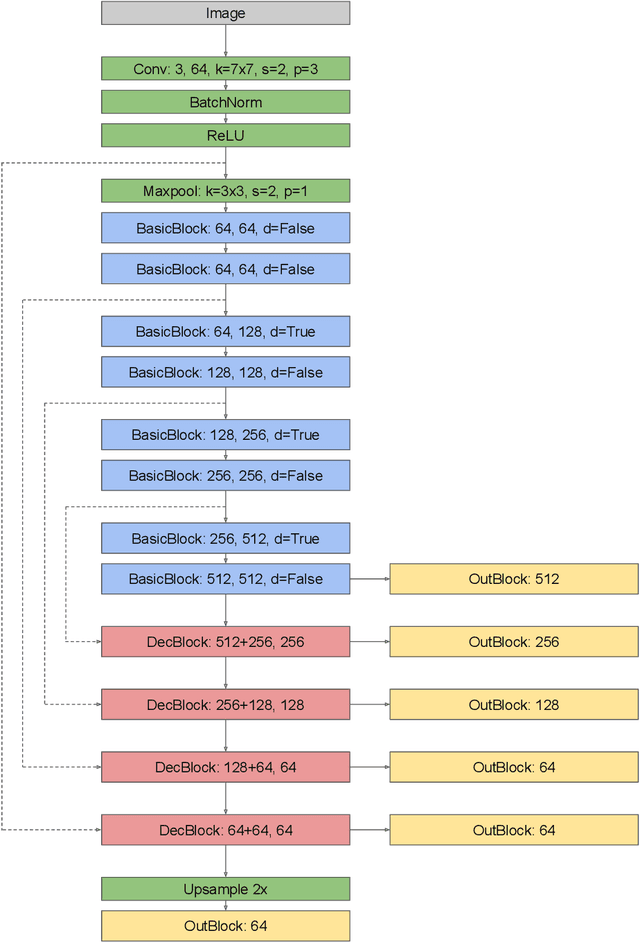
Camera pose estimation in known scenes is a 3D geometry task recently tackled by multiple learning algorithms. Many regress precise geometric quantities, like poses or 3D points, from an input image. This either fails to generalize to new viewpoints or ties the model parameters to a specific scene. In this paper, we go Back to the Feature: we argue that deep networks should focus on learning robust and invariant visual features, while the geometric estimation should be left to principled algorithms. We introduce PixLoc, a scene-agnostic neural network that estimates an accurate 6-DoF pose from an image and a 3D model. Our approach is based on the direct alignment of multiscale deep features, casting camera localization as metric learning. PixLoc learns strong data priors by end-to-end training from pixels to pose and exhibits exceptional generalization to new scenes by separating model parameters and scene geometry. The system can localize in large environments given coarse pose priors but also improve the accuracy of sparse feature matching by jointly refining keypoints and poses with little overhead. The code will be publicly available at https://github.com/cvg/pixloc.
Single-Image Depth Prediction Makes Feature Matching Easier
Aug 21, 2020


Good local features improve the robustness of many 3D re-localization and multi-view reconstruction pipelines. The problem is that viewing angle and distance severely impact the recognizability of a local feature. Attempts to improve appearance invariance by choosing better local feature points or by leveraging outside information, have come with pre-requisites that made some of them impractical. In this paper, we propose a surprisingly effective enhancement to local feature extraction, which improves matching. We show that CNN-based depths inferred from single RGB images are quite helpful, despite their flaws. They allow us to pre-warp images and rectify perspective distortions, to significantly enhance SIFT and BRISK features, enabling more good matches, even when cameras are looking at the same scene but in opposite directions.
Fine-Grained Segmentation Networks: Self-Supervised Segmentation for Improved Long-Term Visual Localization
Aug 18, 2019
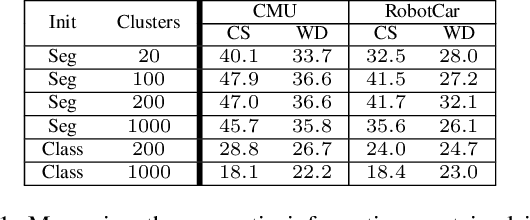
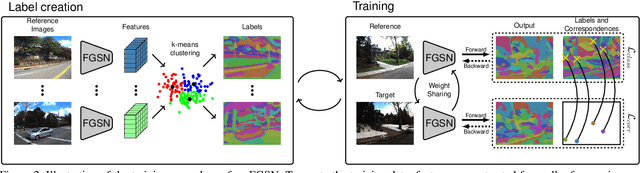

Long-term visual localization is the problem of estimating the camera pose of a given query image in a scene whose appearance changes over time. It is an important problem in practice, for example, encountered in autonomous driving. In order to gain robustness to such changes, long-term localization approaches often use segmantic segmentations as an invariant scene representation, as the semantic meaning of each scene part should not be affected by seasonal and other changes. However, these representations are typically not very discriminative due to the limited number of available classes. In this paper, we propose a new neural network, the Fine-Grained Segmentation Network (FGSN), that can be used to provide image segmentations with a larger number of labels and can be trained in a self-supervised fashion. In addition, we show how FGSNs can be trained to output consistent labels across seasonal changes. We demonstrate through extensive experiments that integrating the fine-grained segmentations produced by our FGSNs into existing localization algorithms leads to substantial improvements in localization performance.
Benchmarking 6DOF Outdoor Visual Localization in Changing Conditions
Apr 04, 2018



Visual localization enables autonomous vehicles to navigate in their surroundings and augmented reality applications to link virtual to real worlds. Practical visual localization approaches need to be robust to a wide variety of viewing condition, including day-night changes, as well as weather and seasonal variations, while providing highly accurate 6 degree-of-freedom (6DOF) camera pose estimates. In this paper, we introduce the first benchmark datasets specifically designed for analyzing the impact of such factors on visual localization. Using carefully created ground truth poses for query images taken under a wide variety of conditions, we evaluate the impact of various factors on 6DOF camera pose estimation accuracy through extensive experiments with state-of-the-art localization approaches. Based on our results, we draw conclusions about the difficulty of different conditions, showing that long-term localization is far from solved, and propose promising avenues for future work, including sequence-based localization approaches and the need for better local features. Our benchmark is available at visuallocalization.net.
Long-term Visual Localization using Semantically Segmented Images
Mar 02, 2018
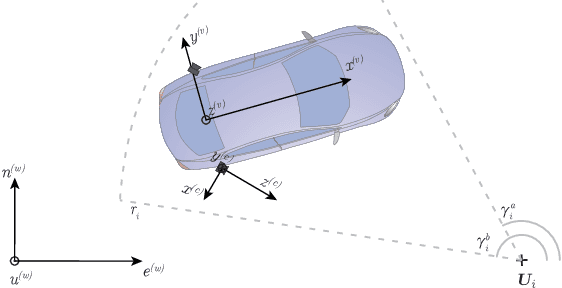

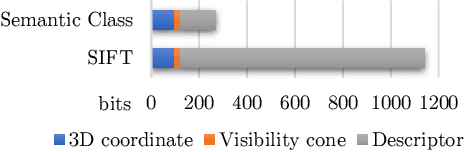
Robust cross-seasonal localization is one of the major challenges in long-term visual navigation of autonomous vehicles. In this paper, we exploit recent advances in semantic segmentation of images, i.e., where each pixel is assigned a label related to the type of object it represents, to attack the problem of long-term visual localization. We show that semantically labeled 3-D point maps of the environment, together with semantically segmented images, can be efficiently used for vehicle localization without the need for detailed feature descriptors (SIFT, SURF, etc.). Thus, instead of depending on hand-crafted feature descriptors, we rely on the training of an image segmenter. The resulting map takes up much less storage space compared to a traditional descriptor based map. A particle filter based semantic localization solution is compared to one based on SIFT-features, and even with large seasonal variations over the year we perform on par with the larger and more descriptive SIFT-features, and are able to localize with an error below 1 m most of the time.